How do computers actually do arithmetic?
The table for binary addition is:
+ 0 1 0 0 1 1 1 10
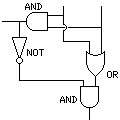
thus, when two binary bits A and B are added, the bit of the sum in the same place is A XOR B, and the carry is A AND B. The exclusive OR function needs to be built from the fundamental AND, OR, and NOT operations in most forms of logic, and A XOR B is the same as (A OR B) AND (NOT (A AND B)). Of course, A AND B has already been calculated, since it is required as the carry. Thus, a binary adder has the following logic diagram:
This involves just three gate delays. But addition requires the propagation of carries, and thus the time required to add two long numbers is proportional to their length in the simplest type of adder. This can be speeded up by calculating sums in advance with either input value of the carry, and then selecting the right one, so that carries propagate at a higher level over many bits at a time:
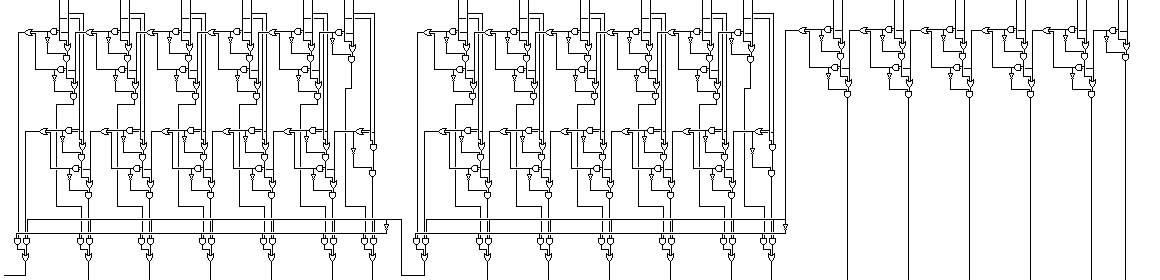
Here, a circuit that adds two binary 18-bit numbers is shown. It is divided into three groups of six bits. Except for the least significant group, each is added together in two ways in parallel, one assuming no carry in, one assuming that a carry in is present; the carry then selects the right result without having to propagate through the six bits of the next group.
If we take this kind of architecture to its ultimate conclusion, the form of carry-select adder we obtain is also known as the Sklansky adder, shown in a more schematic form below:
Newer designs for addition units belonging to the parallel prefix and flagged prefix classes have since been developed. Parallel-prefix adders include the Brent-Kung adder, the Kogge-Stone adder, and the Han-Carlson adder. Although they do not improve on the speed of the Sklansky adder, they address a limitation of real logic circuits which that design ignores, the fact that logic gates have a limited fan-out.
Another important design is the carry-lookahead adder. For a given span of bits within the anticipated result of an addition, there may be a carry out of those bits, or it may be the case that there would be a carry out if there were a carry in to those bits.
While determining this directly for a long span of bits by combinatorial logic would be impractical, this can be done easily for a short span of bits, and the principle can be applied recursively to achieve the same for longer extents.
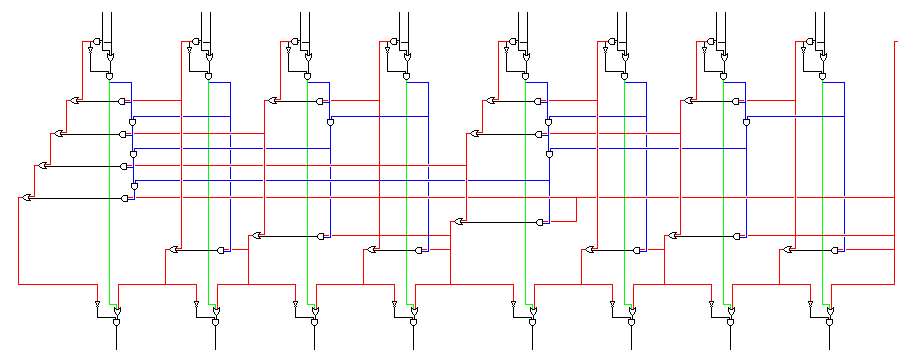
The diagram above shows an example of a carry-lookahead adder. The lines shown in green carry partial sums from the half adders at the top of the diagram; the lines shown in blue contain signals showing that a carry will propagate; these are ANDed together in pairs to provide information about propagation along longer and longer segments of the adder; the lines shown in red contain signals showing that a carry is generated internally; these are ORed together to eventually derive the real carry for every bit in the adder, which is then provided to the half adders at the bottom of the diagram, avoiding the time needed to ripple across the whole adder.
The real carry out of a bit is used as well as the real carry in to a bit, so that some gates can be omitted from the half adders at the bottom.
Binary multiplication does not require much of a multiplication table; all that is required is to make a decision to add or not add a copy of one factor to the result, based on whether the corresponding bit of the other factor is a one or a zero.
One straightforward, although expensive in terms of the number of gates required, way to speed up multiplication is to perform all the multiplications of one factor by the individual bits of the other in parallel, and then add the results in pairs, and then the sums in pairs, so that the number of addition stages required is proportional to the logarithm to the base 2 of the length of the second factor.
If, at the beginning of a multiplication, one calculated three times the multiplicand, then two bits of the multiplier at a time, which can only have the values 00, 01, 10, or 11, could each be used to create a partial product; this would trim away the top layer of the addition tree, cutting the amount of circuitry required almost in half. (It may be noted that the NORC computer by IBM, an ambitious vacuum-tube computer which used decimal arithmetic, calculated multiples up to nine times the multiplicand in advance to speed multiplication.)
While these basic concepts do play a part in performing high-speed multiplication, they omit another factor which has an even more dramatic effect on the speed of multiplication, but which makes fast multiplication somewhat more difficult to understand.
A special type of adder, called a carry-save adder, invented by the well-known John von Neumann, can be used in multiplication circuits, so that carry propagation can be avoided for all but the last addition in the additions required to perform a multiplication. In order to use this kind of adder, instead of adding numbers in pairs, speed can be increased by adding numbers in groups of three. This is because one can turn three numbers into two numbers, having the same sum, without propagating carries through the number. This is because a full adder, which takes two bits and an incoming carry bit, and outputs a result bit and a carry bit, can also be used as a 3-2 compressor, one type of carry-save adder. The carry bits move to the left, but since these bits are all shifted left independently, the delays of carry propagation are not required.
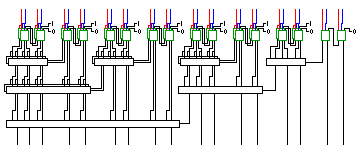
The diagram below shows the difference between a conventional addition circuit with carry propagation, shown in the top half,
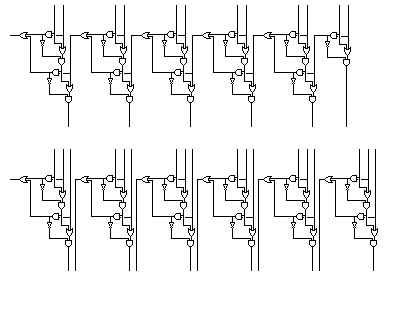
and the 3-2 compressor form of carry-save adder, shown in the bottom half, and involving arguments the same number of bits in length.
As the diagram attempts to illustrate, although carries do not propagate in the sense of being added in to the previous digit, they do still move one place to the left.
One can then add the two resulting numbers by means of a conventional adder with accelerated carry propagation, such as a carry-select adder as depicted above, or, because carry propagation, even when accelerated, causes such a large delay, one can simply use successive stages of 3-2 compression, performing conventional addition only at the very last stage.
This technique was used to speed multiplication in the IBM 7030 computer known as STRETCH.
Instead of simply using one carry-save adder over and over to add one partial product after another, or to have a single line of carry-save adders if it is desired to do successive steps from different multiplications at once in a pipelined fashion, if maximum speed is desired and the cost of hardware and the number of transistors used is no object, one could, as shown above, use several carry-save adders in parallel to produce two results from three partial products, and then repeat the process in successive layers until there are only two numbers left to add in a fast carry-propagate adder. One form of this kind of circuit, arranged according to a particular procedure intended to optimize its layout, is known as the Wallace Tree adder; this was first described in 1964, and an improvement, the Dadda Tree adder, was described in 1965.
The diagram below:
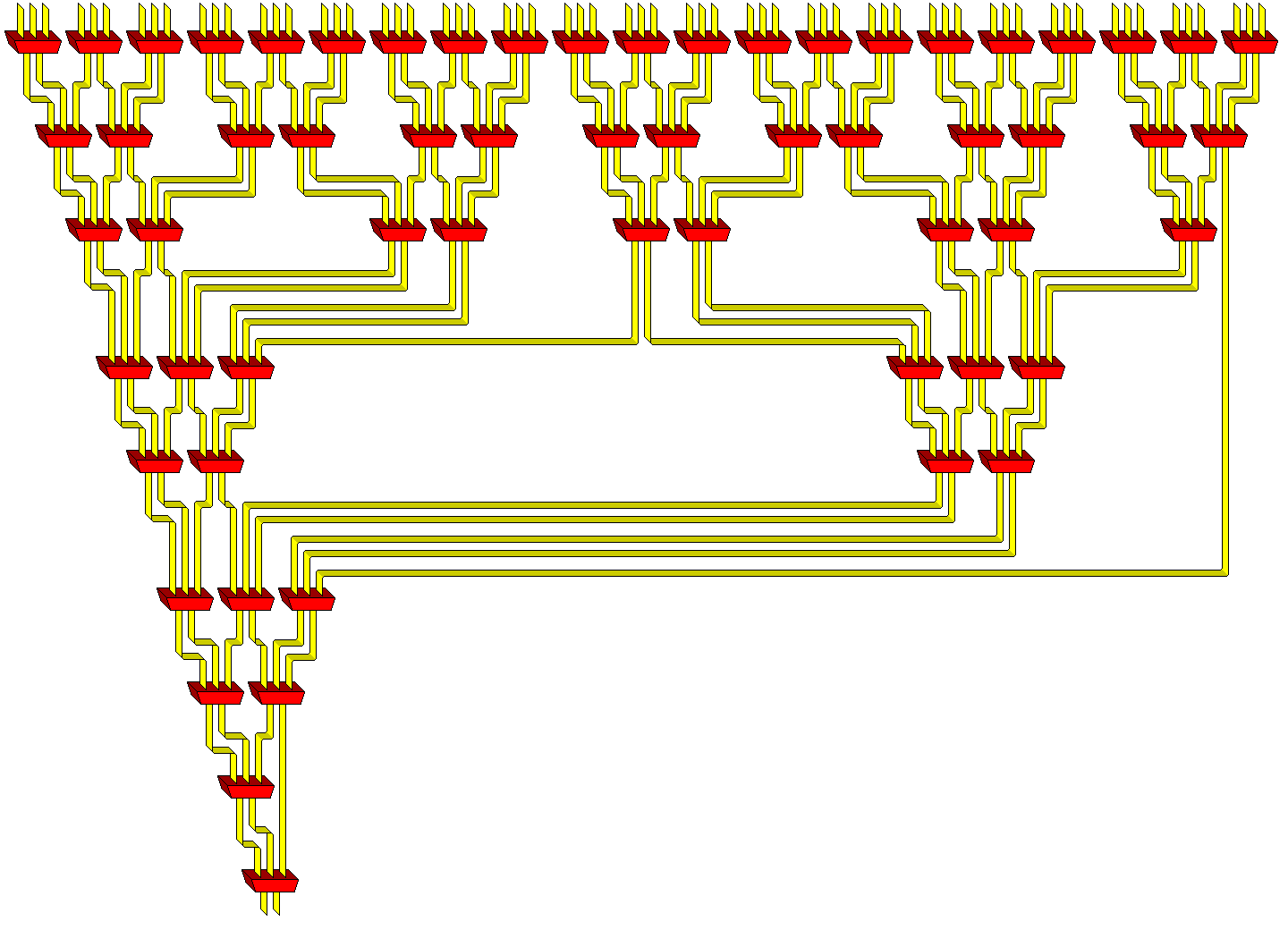
illustrates how, with only two inputs left to go into a carry-propagate adder at the end, successive layers of carry-save adders increase the maximum number of possible partial products that can be included to 3, then 4, and then 6, 9, 13, 19, 28, 42, and 63. The sequence continues: 94, 141, 211...
In the IBM System/360 Model 91, a Wallace Tree of limited size was used, as it was necessary to be somewhat concerned with the number of transistors to use:
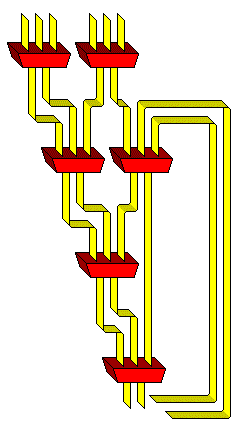
Six partial products were handled by this unit, which were generated from thirteen bits of the multiplier. To avoid having to calculate three times the multiplicand, instead of using two bits of the multiplier for each partial product, sets of three bits that overlapped by one bit were used.
To continue the overlap, the groups of thirteen bits also overlapped by one, so that each iteration took care of twelve bits of the multiplier.
The code used was:
Bits Value Used Offset 000 0 0 001 1 +2 1 over 010 2 +2 011 3 +4 1 over 100 4 -4 -8 101 5 -2 1 over -8 110 6 -2 -8 111 7 0 1 over -8
Thus, the values that began with a 1 corrected for the excess of 1 found in the conversion of the preceding group of bits that ended in 1.
But the groups of three bits, being overlapped by one bit, differ in value by a factor of four, not eight. There is a problem working this scheme in the way that seems correct, though; 4-4 is zero, 5-4 is one, 6-4 is two, but 7-4 is three.
But there is a reason why 8 is correct: while the error in encoding the previous group of bits was 4, since the last bit of the previous group is also the first bit of this group, when I say that the adjustment is 8 relative to the value of the next group, I'm counting that bit twice, so the other 4 is a correction for that! Anyways, this scheme is the one described later on this page as Booth encoding.
The STRETCH, or IBM 7030,
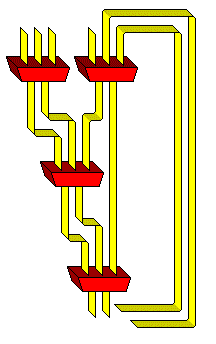
used a similar, but even smaller, such unit. Incidentally, note that the STRETCH dated from 1961, so trees of carry-save adders were used for multiplication before Chris Wallace's 1964 paper.
Apparently, this is the kind of carry-save-adder tree multiplier that was used in the Amdahl 470V/6 and 470V/7 as well, as the machine reference manuals for those models note that they each have a high-speed multiplier that takes eight inputs at once.
The description of the multiplication unit in the STRETCH in the book "Planning a Computer System" notes that multiples up to 7 times the multiplicand are precomputed, so each input to it retires three multiplier bits, instead of two as with normal Booth encoding, so each use of the smaller carry-save adder tree in STRETCH retired 12 multplier bits just as each use of the larger one in the 360/91. (However, precomputing those multiples would have been slower than using Booth encoding.)
The description of that unit in U. S. Patent 3,115,574, however, indicates that something similar to Booth encoding, rather than a naïve precomputation of multiples, was also used in the STRETCH. Incidentally, there is a misprint in the patent: the patent by Tootill that it references should be U. S. Patent 2,693,907 rather than the number appearing.
On the other hand, the Intel Pentium 4 used a larger Wallace Tree, with 25 inputs, which, after Booth encoding, was large enough that floating-point numbers of up to 64 bits in length (in IEEE 754 format, and thus with an effective mantissa of 53 bits, including the hidden first bit) could be multiplied without a second trip through the unit, and thus such multiplies could be pipelined.
Incidentally, note that this means that a more advanced form of Booth encoding was used in the Pentium 4 than the one used in the Model 91, which only cut the number of multiplier terms in half, and which, thus, would only have allowed up to 50 bits, not 53 bits, to be reduced to 25 terms for addition.
An alternative method of speeding up multiplications by using a scheme of addition that avoids having to possibly propagate carries across the entire width of a number is known as signed digit multiplication.
For example, a signed radix-4 number can be converted to a form consisting of the signed digits -3, -2, -1, 0, 1, 2, and 3, still with 4 as the radix.
The sum of two such numbers will be in the range of -6 to 6.
If that sum is generated in the form of a carry digit and a sum digit in the form shown in the table below:
Sum | Carry Digit Sum Digit ----+----------------------- -6 | -1 -2 -5 | -1 -1 -4 | -1 0 -3 | -1 1 -2 | 0 -2 -1 | 0 -1 0 | 0 0 1 | 0 1 2 | 0 2 3 | 1 -1 4 | 1 0 5 | 1 1 6 | 1 2 alternates: -2 | -1 2 2 | 1 -2
then, since the sum digit is always from -2 to 2, and the carry digit is always -1, 0, or 1, the sum of the sum digit at a given radix position, and the carry digit from the next lower radix position will always be in the range from -3 to 3, requiring no further carries. Thus, two stages of circuitry are sufficient to perform a signed-digit addition without regard for the size of the numbers involved.
This is a redundant representation of numbers, so at first glance this does not seem to be that much different from Wallace Tree addition. However, it does have the important advantage that instead of summing three numbers to two, it sums two numbers to one. While this takes two stages, so it doesn't mean this is faster than Wallace Tree addition, it can provide for a tidier layout of circuitry on a chip, and this was cited as its major benefit.
The half adder, although it takes two inputs and provides two outputs, has been used to improve the Wallace Tree adder slightly.
One way this has been done is: when there are two left-over values at a given stage to be added, then, they might be put into a half adder. Although this produces two outputs, one of those outputs will consist of carries, and will therefore be shifted one place to the left. If the number of terms to be added in the next stage is still not an even multiple of three, then, at least at the beginning and end of the part added in the half adders, the number of left-over bits will be reduced by one.
The Dadda Tree multiplier uses this, and in other ways takes the fact that the carry bits are moved from one digit to another into account so that each layer of the tree for each digit will, as far as possible, work efficiently by acting on a number of input bits that is a multiple of three. This is basically achieved by delaying putting groups of three input bits into a carry-save adder until later stages where this is possible without increasing the number of stages.
More recently, in U.S. Patent 6,065,033, assigned to the Digital Equipment Corporation, the fact that half the input bits are moved to the left as carry bits was noted explicitly as a way to replace the larger tree generating the middle of the final product by multiple trees of more equal size starting from the middle and proceeding to the left.
As noted above, one could trim away a considerable portion of the addition tree by using two digits of the multiplier at a time to create one partial product. But doing this in the naive way described above requires calculating three times the multiplicand, which requires carry propagation.
Another idea that suggests itself is to note that either less than half of the bits in a multiplier are 1, or less than half of the bits in a multiplier are zero, so that in the former case, one could include only the nonzero partial products, and in the latter case, one would multiply by the one's complement of the multiplier and then make a correction. But this would require an elaborate arrangement for routing the partial products that would more than consume any benefits.
Fortunately, there is a method of achieving the same result without having to wait for carries, known as Booth encoding. The original paper describing this was published in 1950.
The goal is to make it possible for each pair of bits in the multiplier to introduce only one partial product that needs to be added. Normally, each pair of bits calls for 0, 1, 2, or 3 times the multiplicand, and the last possibility requires carry propagation to calculate.
Knowing that -1 is represented by a string of ones in two's complement arithmetic, the troublesome number 3 presents itself to us as being equal to 4 minus 1. Four times the multiplicand can be instantly generated by a shift. The two's complement of the multiplicand would require carry propagation to produce, but just inverting all the bits of the multiplicand gives us one less than its additive inverse. It is possible to combine bits representing these errors, since each time this happened, it would be in a different digit, in a single term that could be entered into the addition tree like a partial product. Or it could be placed within another term of the product that lies entirely to the left of its location.
But that, alone, doesn't eliminate carry propagation. If we code 3 as -1 with +1 to carry into the next pair of bits in the multiplier, then, if we find 2 there, once again we will be stuck with 3.
As it happens, though, we have one other possible value that can be produced without carry propagation from the multiplicand that is useful. We can also produce -2 times the multiplicand by both shifting it and inverting it; this time, the result will also be too small by one, and that, too, can be accounted for in the error term.
Using the fact that -2 is also available to us in our representation of pairs of bits, we can modify the pairs of digits in the multiplier like this:
00 0 01 +1 10 +1 -2 11 +1 -1
Since only -2, -1, 0, and +1 are initially and directly used to code a pair of bits, a carry of +1 from the pair of bits to the right will result in the possible values -1, 0, +1, and +2; no troublesome value results that requires an additional carry.
A second step is not really needed, since one just has to peek at the first digit of the following pair of bits to see if a carry out would be coming; thus, Booth coding is often simply presented in the manner in which it would be most efficient when implemented, as a coding that goes directly from three input bits to a signed base-4 digit:
00.0 0 00.1 +1 01.0 +1 01.1 +2 10.0 -2 10.1 -1 11.0 -1 11.1 0
In the table as shown here, I place a binary point between the two bits for which a substitution is being made and the bit that belongs to the preceding group on the right. This serves as a reminder that the last bit encoded is to the right of the place value of the result of the code, and also that the rightmost pair of bits is encoded on the basis of a 0 lying to their right. Of course, the final carry out, not apparent in this form of the table, should not be forgotten; but it can also be found by coding an additional leading two zero bits appended to the multiplier.
And the digits of the multiplier as converted can be used to determine the value of the error term. In addition to the error term, it is also necessary to remember that the partial products can be negative, and so their signs will need to be extended; this can be done by means of extending the various carry-save adders in the Wallace tree only one additional bit to the left with proper organization.
An alternative version of Booth encoding that does require generating three times the multiplicand, in return for converting three bits of the multiplier at a time into a term from the set {-4, -3, -2, -1, 0, +1, +2, +3, +4} has also been used. However, if one is going to allow hard multiples of the multiplicand, that is, multiples which require a carry-propagate addition to produce, then, one could also generate five times the multiplicand (5=4+1), nine times the multiplicand (9=8+1), and even, through the use of the same principle as underlies Booth encoding, seven times the multiplicand (7=8-1); three times, of course, gives six and twelve times by a shift, so, if one is willing to build three carry-propagate adders working in parallel, one can produce all the multiples in the set {-8, -7, -6, -5, -4, -3, -2, -1, 0, +1, +2, +3, +4, +5, +6, +7, +8}, and encode four bits of the multiplier at a time.
If the multiples of the multiplicand are generated in advance, and the multiplier is long enough, then one can retire four bits of the multiplier and, using a pre-generated multiple, following the principle used in the NORC, do so with only a single carry-save addition.
If the multiples are not generated in advance, or when a full-width Wallace Tree is used, it would seem that multi-bit Booth encoding could not provide a gain in speed, because an addition requiring carries would take as long as several stages of carry-save addition.
If one is retiring the bits of the multiplier serially, to save hardware, rather than using a full Wallace Tree, in which all of the multiplier is retired at once, and the partial products are then merged into half as many terms at each step, one could retire the last few bits of the multiplier at a slower rate while waiting for the larger multiples of the multiplicand to become available. The Alpha 21264 multiplier unit used this technique, using Booth encoding of bit pairs in the multiplier until a conventional adder produced the value of three times the multiplicand for use in later stages allowing the use of three-bit Booth encoding of the multiplier thereafter.
Some early large and fast computers, such as the Elliot 152 and the Whirlwind, before either the carry-save adder or Booth recoding were invented, speeded up multiplication by using a tree of ordinary adders. A multiplication unit of this type was called a whiffletree multiplier, after a type of harness for two draft animals that ensures that both contribute useful work even if they aren't pulling equally hard.
Division is the most difficult of the basic arithmetic operations. For a simple computer that uses a single adder circuit for its arithmetic operations, a variant of the conventional long division method used manually, called nonrestoring division provides greater simplicity and speed.
This method proceeds as follows, assuming without loss of generality (which means we can fix things by complementing the operands and remembering what we've done, if it isn't so) that both operands are positive:
If the divisor is less than the dividend, then the quotient is zero, the remainder is the dividend, and one is finished.
Otherwise, shift the divisor as many places left as is necessary for its first one bit to be in the same position as the first one bit in the dividend. Also, shift the number one the same number of places left; the result is called the quotient term.
The quotient value starts at zero.
Then, do the following until the divisor is shifted right back to its original position:
If the current value in the dividend register is positive, and it has a one bit corresponding to the starting one bit of the value in the divisor register (initially, the divisor as shifted left), subtract the divisor register contents from the dividend register, and add the quotient term to the quotient register.
If the current value in the dividend register is negative, and it has a zero bit corresponding to the starting one bit of the value in the divisor register, add the divisor register contents to the dividend reigster, and subtract the quotient term from the quotient register.
Shift the divisor register and the quotient term one place to the right, then repeat until finished (when the quotient term becomes zero at this step, do not repeat).
If, after the final step, the contents of the dividend register are negative, add the original divisor to the dividend register and subtract one from the quotient register. The dividend register will contain the remainder, and the quotient register the quotient.
An example of this is shown below:
Divide 10010100011 by 101101.
00010010100011 DD 0000000 Q
10110100000 DR 100000 QT
11111100000011 DD 0100000 Q
1011010000 DR 10000 QT
11111100000011 DD 0100000 Q
101101000 DR 1000 QT
11111100000011 DD 0100000 Q
10110100 DR 100 QT
11111110110111 DD 0011100 Q
1011010 DR 10 QT
00000000010001 DD 0011010 Q
101101 DR 1 QT
00000000010001 remainder 11010 quotient
which produces the correct result; 1187 divided by 45 gives 26 with 17 as the remainder.
Speeding up division further is also possible.
One approach would be to begin with the divisor, from which 8, 4, and 2 times the divisor can be immediately derived, and then with one layer of addition stages, derive 3 (and hence 6 and 12) times the divisor, 5 (and hence 10) times the divisor, and 9 times the divisor, and then with a second layer of addition stages, derive the remaining multiples from 1 to 15 of the divisor.
Then an assembly of adders working in parallel to determine the largest multiple that could be subtracted from the dividend or the remaining part of it without causing it to go negative could generate four bits of the quotient in the time a conventional division algorithm could generate one.
The decimal version of this technique was used in the NORC computer, a vacuum tube computer designed for very high-speed calculation.
Another method of division is known as SRT division. In its original form, it was a development of nonrestoring division. Instead of choosing, at each bit position, to add or subtract the divisor, the option of doing nothing, and skipping quickly over several bits in the partial remainder, is also included.
Starting from the same example as given above for nonrestoring division:
Divide 10010100011 by 101101.
00010010100011 DD 0000000 Q
10110100000 DR 100000 QT
11111100000011 DD 0100000 Q
10110100 DR 100 QT
11111110110111 DD 0011100 Q
1011010 DR 10 QT
00000000010001 remainder 11010 quotient
Thus, when the partial remainder is positive, we align the divisor so that its first 1 bit is under the first one bit of the partial remainder, and subtract; we add a similarly shifted 1 to the quotient.
When the partial remainder is negative, we align the divisor so that its first 1 bit is under the first zero bit of the partial remainder,and add; we subtract a similarly shifted 1 from the quotient.
In the example, an immediate stop is shown when the right answer was achieved; normally, two additional steps would take place; first, a subtraction of the divisor, and then, since the result is negative, an addition in the same digit position; this is the same second chance without shifting as is used to terminate nonrestoring division.
The property of shifting at once over multiple zeroes is no longer present in the high-radix forms of SRT division.
Thus, in radix 4 SRT division, one might, at each step, either do nothing, add or subtract the divisor at its current shifted position, or add or subtract twice the divisor at its current shifted position. Instead of a simple rule of adding to a zero, and subtracting from a 1, a table of the first few bits of both the partial remainder and the divisor is needed to determine the appropriate action at each step.
To achieve time proportional to the logarithm of the length of the numbers involved, a method is required that attempts to refine an approximation of the reciprocal of the divisor. This basic method, which uses the recurrence relation
r' = r * (2 - r*x)
where x is the number whose reciprocal is to be found, and r and r' are two successive approximations to its reciprocal, doubles the number of accurate digits in the reciprocal with each iteration.
The recurrence relation can be made more understandable by splitting it into two parts.
Given that r is an approximation to the reciprocal of x, then we can consider r*x to be 1+e, where e is a small error term reflecting the proportion by which r differs from the real reciprocal.
Thus, we can have as our first equation, containing one multiplication,
e = r*x - 1
If r is (1+e) times the real reciprocal, (1-e) times r will be a much closer approximation to the reciprocal, since the result will be (1-e^2) times the real reciprocal. Thus, the second multiplication can be part of the equation:
r' = (1 - e)*r
An advantage of leaving the recurrence relation in the form from which it was originally derived is that e is a small quantity compared to 1+e, and so significance can be preserved. We will see how this can be used below.
Another method of performing division, which also converged quadratically, and required two multiplications for each iteration, was Goldschmidt division. It was described in U.S. patent 3,508,038 with inventors Goldschmidt and Powers, assigned to IBM, and was developed for the IBM System/360 Model 91 computer.
This method had one disadvantage over Newton-Raphson division, in that the earlier multiplications could not be done at less than full precision. But it had the larger advantage that the two multiplications in each step were independent of one another, and so they could be done in parallel, or on successive cycles in a single pipelined multiplication unit.
Its basis is the binomial theorem:
The reciprocal of 9 is 0.11111..., and this is one case of the binomial theorem:
1 1 1 1 --- = ----- + ------- + ------- + ... n n+1 (n+1)^2 (n+1)^3
This becomes useful because if we determine the error in our first approximation to the reciprocal using a modified form of the equation above, in order to change the sign of our error term
e = 1 - r*x
so, now, the original approximation to the reciprocal, r, is 1 - e times the true reciprocal, and multiplying it by 1 + e yields a closer approximation, but multiplying it by 1/(1 - e) instead would yield the exact result.
And, by the binomial theorem,
1 e
e + e^2 + e^3 + e^4 + e^5 + .... = --------- = -------
1 1 - e
--- - 1
e
and so we can get 1/(1-e) just by adding 1 to that result. Quadratic convergence can be obtained by steps like this:
e (1 + e) e + e^2 (1 + e^2) e + e^2 + e^3 + e^4 (1 + e^4) e + e^2 + e^3 + e^4 + e^5 + e^6 + e^7 + e^8
The first column shows our approximations to e/(1-e), and the second column shows what we have to multiply each one by to get the next one.
In fact, one would start with 1 + e, thus approximating 1/(1-e) directly, and skipping an entire iteration; it is just shown this way for ease of understanding.
1 + e (1 + e^2) 1 + e + e^2 + e^3 (1 + e^4) 1 + e + e^2 + e^3 + e^4 + e^5 + e^6 + e^7
Occasionally, for dealing with numbers with higher precision, it's been proposed to modify the algorithm so as to achieve cubic convergence, tripling the number of correct significant digits with each iteration:
1 + e (1 + e^2 + e^4)
1 + e + e^2 + e^3 + e^4 + e^5 (1 + e^6 + e^12)
1 + e + e^2 + e^3 + e^4 + e^5 +
e^6 + e^7 + e^8 + e^9 + e^10 + e^11 +
e^12 + e^13 + e^14 + e^15 + e^16 + e^17
but it appears that this would make each iteration take twice as long, thus not providing an advantage over the conventional version of the algorithm.
Although each step in the Goldschmidt algorithm has to be done at the full precision of the final result, another option would be to use the Goldschmidt algorithm at (slightly more than) half precision for all the steps except the last one, and then use the Newton-Raphson algorithm for the final step to increase the precision to that desired. If the time saved by doing all the previous steps at half precision exceeds the time taken by an additional multiplication, that could be worthwhile.
As well, one source I've recently read noted that this is a useful choice for quite another reason: for the same reason that the Goldschmidt algorithm needs to be done at the target precision from the start, roundoff errors can accumulate during the execution of that algorithm. Therefore, if good accuracy, even if not the perfect accuracy demanded by the IEEE 754 standard, is a requirement, and performing the Goldschmidt algorithm to somewhat greater precision than the target precision is not an option, as it is not desired to face an additional hardware requirement for this specialized purpose, doing the last round with the Newton-Raphson algorithm allows roundoff errors to be overcome.
One obstacle to the use of existing hardware is that since double-precision numbers tend to take exactly twice the storage of single-precision numbers, but their exponent fields are not twice as long (even where, as in the IEEE 754 standard, they aren't exactly the same size), doing the Goldschmidt algorithm in single precision and then Newton-Raphson in double precision for just one round won't quite work; in that case, one simple option would be to do Newton-Raphson for two rounds, at the cost of an extra multiply time. Of course, the more usual case is where there is only one set of floating-point hardware, and so the previous Goldschmidt rounds were done to full precision; in which case, of course, one final Newton-Raphson round would suffice.
One difficulty with the use of both of these iterative methods for division is that they do not naturally lend themselves to producing the most accurate result in every case, as required by the IEEE 754 standard.
The obvious way of dealing with this is as follows:
If one is calculating a/b, one begins by approximating the reciprocal of b.
Because the accuracy of that approximation doubles with each iteration, there will be some excess precision available at the final iteration.
Obtain an approximation to a/b by multiplying this result by a at the full working precision of the calculation.
If the part of that result that needs to be rounded off to fit the quotient into the desired format is close enough to .4999... or .5000... to create concern (thinking of the mantissa as being scaled so as to become an integer in its ultimate destination), then, first replace that part by an exact .5. Multiply it by b, the divisor.
If the result is greater than a, then .5 is too high, so round down. If the result is less than a, .5 is too low, so round up.
Because allowing a division to take a variable amount of time could interfere with pipelining in some computer designs, work has been done on finding improved algorithms for IEEE 754 compliant Goldschmidt division.
The Texas Instruments 74ACT8847 was a floating-point coprocessor available in 25 MHz and 33 MHz clock speeds that sold for about $700 in one version; it was used in some Sun workstations, as well as being able to be used as a replacement for the 80387 coprocessor with some additional circuitry. I have seen a claim that a patent from 1989, U. S. patent 4,878,190, describes how, by performing Goldschmidt division to six extra bits of precision, it is possible to correct the final result to produce an exact result that satisfies the IEEE 754 standard. (Incidentally, that patent also referenced another patent, which dealt with signed digit multiplication, that technique also having been used on that chip.) However, the process described in that patent still requires multiplying the final quotient by the divisor in the final step to determine the direction of rounding.
However, that final step of multiplication could be performed using only the last few bits of the numbers involved, and so my initial impression that the existing state of the art, as indicated by the patents I had reviewed, required either two sets of division hardware working in parallel, or an extra full-width multiplication adding to the latency of the operation, was mistaken, and instead IEEE 754-compliant rounding can be achieved at reasonable cost in both hardware and time for division.
Several engineers working at Matsushita, Hideyuki Kabuo, Takashi Taniguchi, Akira Miyoshi, Hitoshi Yamashita, Masashi Urano, Hisakazu Edamatsu, and Shigero Kuninobu, developed a method of adapting iterative division to produce accurate results with a very limited latency overhead which was published in a 1994 paper. This is also being done in software today; Intel's Itanium microprocessor does not have a division instruction, but makes use of a short software routine for division that uses the iterative method and delivers correctly rounded results; this is made possible by the use of a multiply-and-accumulate instruction that performs both multiplication and addition at the same time, and is based on, as is acknowledged in Intel's publications on this, work done by IBM for the RS/6000 processor, as described in a 1990 paper in the IBM Journal of Research and Development by Peter W. Markstein, and which is the subject of U.S. patent 5,249,149, with Markstein and Daniel Cocanougher as inventors. (Intel's own improvement to this is given in U.S. patent 6,598,065, John R. Harrison being the inventor.)
Other research and patents from Matsushita involving several of these same engineers related to improving another characteristic of division algorithms. In order to perform an iterative division, how often is it really necessary to perform the final step in multiplication, creating an explicit numerical result at the cost of carry propagation? Perhaps it is not necessary at all, except once at the very end.
A table-driven method of division for arguments of limited width, described in a paper by Hung, Fahmy, Mencer, and Flynn, can also be used to obtain an excellent initial approximation to the reciprocal in the time required for two multiplications; conventional techniques can then double the precision of the approximation in each additional multiplication time used.
To divide A by B:
B will be normalized before starting, so that its value is between 1 and 2.
The first few bits of B will be used to obtain two values from a table; one value will be an approximation to 1/B, and the other will be the derivative of the function 1/B with respect to B at the point indicated by the first few bits of B.
In the first multiplication time, multiply, in parallel, both A and B by the approximation to 1/B found in the table, and also multiply 1 plus the remaining bits of B, not used to find a table entry, by the second table entry.
In the second multiplication time, multiply, in parallel, both the modified A and the modified B by the product involving the remaining bits of B.
In subsequent steps, where the modified B is 1 + epsilon, multiply both the modified A and the modified B by 1 - epsilon. Since 1.001 times .999 is .999999, this doubles the precision in each step.
Basically, what is being done here is: as the reciprocal of the divisor is being determined by repeatedly multiplying the divisor by numbers that will bring it closer to 1, the dividend is being multiplied, in parallel, by these numbers, so that it does not need to be multiplied by the reciprocal of the divisor separately, at the end of the computation. Is one exchanging one multiplier for several? Not really, as the reciprocal of the divisor would have to be constructed from several individual multiplications if it were used explicitly. The need for several multipliers, instead of just two, comes from the desire to allow full pipelining.
It is the high-precision starting approximation obtained in the first two steps that was the unique contribution of this paper. Producing the quotient in parallel with the reciprocal as outlined above is also a potential feature of hardware implementations of the methods of producing accurate quotients by the iterative method outlined in the IBM and Intel patents referred to above.
Thus, the procedure given in the IBM patent involves a recurrence relation with four operations; the reciprocal of b, approximated by r, is improved by the two-step recurrence relation:
m = 1 - b*r r' = r + m*r
(note that m stands for minus epsilon) and the quotient is improved in parallel by the operations:
s = a - b*q q = q + s*r
By choosing an initial approximation to the reciprocal of b that is guaranteed to be greater than 1/b rather than less than 1/b for a divisor b whose mantissa consists entirely of ones, the final step is guaranteed to produce a result that will round properly. Once enough approximation steps are performed so that the final r has the precision required, the two steps to improve the quotient are performed one extra time, with the second of the two steps also used to set the condition codes for the division operation as a whole. (All the preceding steps must be performed as round to nearest regardless of the rounding mode that is selected.)
In the Intel improvement of this method, it is noted that once epsilon, the error in an approximation to the reciprocal of b, is known, epsilon squared can be computed directly, instead of being discovered as the error in a subsequent step. Thus, instead of approximating 1/(1+e) as 1-e, one can directly calculate an infinite product yielding the reciprocal,
2 4 8
(1 - e) * (1 + e ) * (1 + e ) * (1 + e ) ...
since
2
(1 + e) * (1 - e) = 1 - e
2 2 4
(1 - e ) * (1 + e ) = 1 - e
4 4 8
(1 - e ) * (1 + e ) = 1 - e
8 8 16
(1 - e ) * (1 + e ) = 1 - e
and so on: if one thinks of the first term as 1-e insted of 1+e, then all the corrections are in the same direction.
A method to obtain a further improvement in efficiency in this type of calculation is discussed in a paper by Ercegovac, Imbert, Matula, Muller, and Wei from Inria. It can happen that the initial approximation to the reciprocal of the divisor is such that as it doubles in accuracy in each step, instead of having half the required accuracy just before the final step, it may be short of the required accuracy by only a few bits. In that case, instead of squaring e^n to obtain e^(2n), one could simply look up 1 + e^(2n) in a table using the first few bits of e, and this could be done at an early point in the computation.
Although it still takes two multiplies per iteration, it is also still an improvement, because it now takes only one add.
Another high-performance division algorithm also proposed by Hung, Fahmy, Mencer, and Flynn works on a different principle.
If one is dividing A by B, this can be considered to be A/(Bh + Bl) where Bh and Bl are the most significant and least significant halves of B respectively.
Bh^2 - Bl^2 is the product of Bh + Bl and Bh - Bl. Multiplying the top and bottom of the formula by Bh - Bl, then, one gets A/B = A(Bh - Bl)/(Bh^2 - Bl^2).
When one squares the most significant and the least significant halves of a number, the square of the least significant half becomes insignificant, so Bh can be used as an index into a table of 1/(Bh^2) for a second multiplication step while one performs the first multiplication step of multiplying A by (Bh - Bl).
Since this requires using half the number as an index into a table, the precision of numbers it can handle is limited, but again it could be useful in forming an initial approximation, and the limit is not too strict; 24 bit numbers can be divided with a table of reasonable size, and this is enough to perform single-precision floating-point division. (While Bh^2 can be calculated from Bh by multiplication instead of a table lookup, that doesn't help since it is 1/Bh^2 that is needed.)
Using the formula (a+b)^2 = a^2 + 2ab + b^2, a method for calculating square roots by hand was devised that resembles long division:
8. 4 2 6 1 4 9
______________________
71.00 00 00 00 00 00 |
64 |
---------------------|
7.00 |1 6
6.56 | 4
--------------------|
44 00 |16 8
33 64 | 2
------------------|
10 36 00 |1 68 4
10 10 76 | 6
------------------|
25 24 00 |16 85 2
16 85 21 | 1
---------------|
8 38 79 00 |1 68 52 2
6 73 29 44 | 4
--------------|
1 55 49 56 00 |16 85 22 8
1 51 67 06 01 | 9
--------------|
3 82 49 99 |
To find the square root of 71, first, it is noted that 71 is between 64 and 81. Thus, we subtract 8 squared, or 64, from 71, and note that our square root will be 8 point something.
In subsequent steps, what has gone before will play the role of a in the formula above, and the next digit in the square root will play the role of b. And, as with 8, a^2 has already been subtracted, so, for whatever digit we choose as b, we must be able to subtract 2ab + b^2 from what remains.
Thus, let us choose 4 as the next digit in the square root. We will subtract 2 * 8 * .4 plus .4 squared, which is 6.56, from the number.
On the next line, what we are dividing by (with the allowance that the b^2 term may change what we use) is 2 * 8.4, which is 16.8. This goes into .44 a bit more than .02 times, so we get 33 60 plus 04, or 33 64 to subtract.
8.42 times 2 is 16.84; this goes into .1036 .006 times, and so we get 10 10 76 to subtract. Finally, we start with 8.426 * 2, which is 16.852, and divide .002524 by it, to get 1, and so we subtract 16 85 21.
As the last decimal place of a is one position ahead of b, if we treat both terms as integers instead of as real numbers, the formula becomes 20*ab+b^2, which is what is used when this is done in a more mechanical fashion.
Other than noting that as the numbers involved keep growing, this is not useful as a method of pseudorandom number generation, not much more need be said.
The resemblance between this method of calculating square roots and long division is sufficiently close that it is possible to adapt, for example, high-radix SRT division to calculating square roots. If the first part of the square root is determined from a table, the 2ab term will be large enough, compared to the b^2 term, that a modified table, giving the value of b to try from 2a and the current remainder will keep the error small enough so that it is always possible to proceed to the next digit on the next step.
Another method of approximating the square root of a number is available for computers, which is much faster for sufficiently large numbers, or when performed in software, known as Newton-Raphson iteration. In fact, the method of approximating the reciprocal of a number shown above is another example of Newton-Raphson iteration.
If r is our existing approximation, and r' is the improved approximation, for 1/x, the recurrence relation was:
r' = r * (2 - r*x)
since if r = (1/x)*(1+e), for some small e, 2 - x*r is 1-e, and (1+e)*(1-e) is 1 - e^2, which is much closer to one.
For square root, we get the recurrence relation:
1 x
r' = - ( --- + r )
2 r
and, as x/r and r have, to the first order, equal and opposite discrepancies from the square root of x, r' is once again much closer to the right answer than r.
This is the classic Newton-Raphson iteration for square root. Given that division is slower than multiplication, can it be improved upon?
One simple-minded approach might be to start with an approximation to the square root, r, and an approximation to the reciprocal of the square root, q, and also calculate y, the reciprocal of x, at the beginning.
Then, use the pair of recurrence relations:
1
r' = - ( qx + r )
2
1
q' = - ( q + ry )
2
If q is initially the reciprocal of r, then r' and q' are better approximations than r and q after the first step. Perhaps they will continue to improve in later steps, a less elaborate iteration which simply improves q that apparently has been used in practice both on Burroughs and Cray machines (my source, which claimed that, had a typographical error, and omitted the factor of 1/2), is the following:
1
q' = - q * ( 3 - x * q * q )
2
Let us suppose that q is equal to the true reciprocal of the square root of x, which we will call p, times (1 + e). Since e is small, 1/(1+e) is approximately 1-e.
Then, q * ( 3 - x * q * q ) becomes, approximately, p * (1+e) * (3 - (1+2e)), which is p * (1+e) * (2-2e), which is approximately 2p, and, thus, half of that is a new approximation in which the new error is of the order of the square of the old error.
A fast method of calculating trigonometric functions using only shifts and adds was described in a paper which described how it was applied to a device bearing the acronym CORDIC as its name.
A vector (x,y) can be rotated through an angle theta by means of the equations:
x' = x cos(theta) - y sin(theta) y' = y cos(theta) + x sin(theta)
In the CORDIC algorithm, a table is required whose contents are:
arctangent(1/2) arctangent(1/4) arctangent(1/8) arctangent(1/16) ...
Beginning with suitable starting values of x and y, one iterates through a fixed number of steps wherein one performs either
x' = x - y M y' = y + x M
or
x' = x + y M y' = y - x M
M starts as 1/2, and is divided by two at each step, so multiplying x and y by M is simply a shift. This enlarges the vector (x,y) in addition to rotating it by plus or minus the arctangent of M.
If one is calculating the sine or cosine of an angle, one adds or subtracts the table value from the angle to bring the result closer to zero, to decide which operation is to be performed. Then, the starting values of x and y are chosen so that the successive enlargements will lead, at the end, to a vector whose length is exactly 1.
If one is trying to find an inverse trigonometric function, the goal is instead to make y equal to zero, although striving to make x equal to y will also work, provided one adds 45 degrees to the angle one uses as the starting point.
In that case, one wishes to find theta, so the scaling of x and y are irrelevant; therefore, the rule about performing either a clockwise or counterclockwise rotation at each step is no longer required.
To find either the arcsine or arccosine, one has to first modify the input by a calculation involving a square root, as due to the scaling at each step, only the arctangent can be found directly by this method.
The paper noted that this method could also be applied to the hyperbolic trig functions with modifications. However, a simpler method can be used to calculate logarithms directly with similar efficiency.
For that method, one requires a table containing the values:
log(1 1/2) log(1 1/4) log(1 1/8) log(1 1/16) ...
and to find the logarithm of a number between 1 and 2, one at each step chooses either to leave it alone, or add it to itself shifted right by the number of places N that is also the number of the step; the latter is done if its result is less than or equal to 2.
Since, in this method, we don't have to worry about always having to perform a clockwise or counterclockwise rotation in each step, so that the scaling factor is not altered, it is easy to adapt this method to decimal arithmetic. One can have a table of log(2), log(1.1), log(1.01), and so on, and just repeat the steps at each level up to nine times. This was indeed how logarithms were calculated on the HP-35 calculator, for example.
This was also the method used by the early Wang programmable calculators, but with one improvement: instead of log(2), log(1.1), log(1.01), log(1.001), log(1.0001), log(1.00001)... the table contained log(2), log(0.9), log(1.01), log(0.999), log(1.0001), log(0.99999) and so on. Thus, the same basic idea as used for nonrestoring division is used here, so that the need to backtrack, or to determine in advance if a value should be subtracted, is avoided, thus keeping the number of operations required to a minimum.
This basic algorithm for calculating logarithms happens to be much older than CORDIC. I recently learned, from reading an article about how the HP-35 pocket calculator was designed, that it was described in Arithmetica Logarithmica by Henry Briggs from 1624, and also in The Radix, a New Way of Making Logarithms by Robert Flower from 1771.
The book by Robert Flower gives a number of different ways to calculate logarithms, beginning with one based on repeatedly taking the cube root, first of ten, and then each succeding time of the previous result. This makes sense as a starting point, if one doesn't have a good alternative means of calculating logarithms based on Taylor series or something similar available to construct one's initial table. But the method discussed here, using a table with logarithms of the integers from 2 to 9, then 1.1, 1.2, ... 1.9, then 1.01, 1.02, .... 1.09, and so on is given later, and called the direct method.
This method was referred to as the radix method by Briggs, and he too presented other methods, starting with one based on starting with ten and taking the square root repeatedly.
I have also learned, from a web site on calculator history, that Wang Laboratories brought suit against Hewlett-Packard for its use of this algorithm in the 9100A calculator; this is how Briggs' earlier description of the algorithm came to light, from Hewlett-Packard's defense in that lawsuit.
One web site notes an even earlier description of this method from 1618, by William Oughtred, often considered the inventor of the slide rule. It is perhaps fitting that the inventor of the slide rule would have also invented a key algorithm used in the pocket calculators that supplanted it.
This description appeared in the 1618 edition (the second edition) of a translation of John Napier's Mirifici Logarithmorum Canonis Descriptio into English by Edward Wright under the title A Description of the Admirable Table of Logarithmes; the authorship of the appendix was not given, but it is believed to be by William Oughtred, and it is also notable for first introducing the X-shaped symbol for multiplication.
Edward Wright is also noted for putting Mercator's projection on an explicit mathematical basis, giving the formula for calculating where its parallels should be drawn.
At this point, perhaps a little note about the history of logarithms might be made here.
In his original treatise on the logarithm, John Napier started from 10,000,000 and defined its logarithm as 0, and then defined the logarithm of 9,999,999 as 1. Thus, 0.9999999 times 9,999,999 would have the logarithm of 2, and so on.
Napier himself realized that this was unwieldy, and he devised common logarithms and began work on a table of common logarithms, but was unable to complete it before his death, and so the work was continued by his friend Henry Briggs.
Thus, the name Napierian being presumably taken for his original system, common logarithms were, despite the apparent injustice, also called Briggsian logarithms.
Meanwhile, natural logarithms as we understand them today first appeared in a table by John Speidell, published in 1619, two years after Napier's death. Natural logarithms, as opposed to logarithms in Napier's original system, are often called Napierian logarithms. This is not as strange as it might seem.
The base of the natural logarithms, e, is the limit, as n goes to infinity, of
/ 1 \ n | 1 + --- | \ n /
So, had Napier chosen to assign 1 to the logarithm of 10,000,001 instead of 9,999,999, the relationship of Napierian logarithms to natural logarithms would be even more obvioux than it already is. Although ten million, being finite, is not the tiniest part of infinity, yet for some purposes, it can be taken as a close approximation.
Thus, for Napier's original system, we need merely approximate e for n=9,999,999 to obtain e' (which is 2.71828 16925 44952 67979 05405..., as opposed to e itself, which is 2.71828 18284 59045 23536 02874...) , and after taking the logarithm of a number x to that base, which we shall call lna(x), for the approximate natural logarithm of x, the logarithm of that number in Napier's original system is (lna(x) - lna(10,000,000))/lna(0.9999999) .
One can calculate lna(x) by taking ln(x), and then multiplying the result by the conversion factor 1.00000 00500 00004 16666 67041 66670... .
However, this may be an oversimplification.
Looking at the account of how the first table of logarithms was constructed, translated into English in 1889, one sees that three tables were used as the basis of constructing the tables.
The first was based on 10,000,000 having a logarithm of 0, and 9,999,999 having a logarithm of 1. But the second started from 10,000,000 and went as its next step to 9,999,900, going down in steps of 100, and the third started from 10,000,000 with 9,995,000 as its next step, and going down in steps of 5,000.
However, Napier did not carelessly take the steps in the second and third tables as corresponding to a change of 100 and 5,000, respectively, in logarithm. He did use his first table to derive the necessary adjustment for the second table, and then the first two tables to derive the necessary adjustment for the third, with the result that the logarithm of 9,999,900 was 100.0005 and that the logarithm of 9,995,000 was 5,001.2485387.
Later in that document, it is noted that the logarithm of 1,000,000 and thus the difference in logarithms which corresponds to a factor of ten, is 23,025,842.34; that would result from using 2.71828 28425 31975 20690 33310.. as one's approximation for e. So it turns out that accumulated error has led to an over-compensation; instead of the smaller approximations to e that would result from using the finite n=9,999,999, his logarithms actually ended up being based on a value for e that was too high. Which seems to me to make it less unfair to call natural logarithms "Napierian logarithms", even if the ideal concept is due to Speidell.
A short table of the approximations for various values of n can be given:
n (1+1/n)^n
1 2
2 2.25
3 2.37037 037...
4 2.44140 625
5 2.48832
6 2.52162 63717 42112 48285 32235...
7 2.54649 96970 40713 11394 79055...
...
12 2.61303 52902 24678 16029 95330...
...
52 2.69259 69544 37177 27556 11776...
...
365 2.71456 74820 21874 30319 38863...
...
1,998 2.71760 18896 95860 26797 85022...
...
99,999 2.71826 82370 38576 70921 76487...
...
999,999 2.71828 04693 18017 74403 81864...
...
9,999,999 2.71828 16925 44952 67979 05405...
10,000,000 2.71828 16925 44966 27119 85502...
...
infinity 2.71828 18284 59045 23536 02874...
these values, incidentally, being truncated rather than rounded, so that all the visible digits are correct.
How would one adapt the CORDIC method for trig functions to decimal arithmetic? This was done for pocket calculators.
Could one just always go through five steps for each digit, each step being a repetition of
x' = x - y M y' = y + x M or x' = x + y M y' = y - x M
for M being one of arctangent(1/10), arctangent(1/100), and so on?
That won't quite work, because sometimes one would have to stop after an odd number of steps, and sometimes after an even number of steps.
One possibility is to use a simpler method; when it is necessary to worry about the scale factor (it is not for inverse trig functions, or for calculating the tangent, it is only a concern for sine and cosine) one still can simply either perform the calculation with the arctangent of decimal 0.1, 0.01, 0.001, 0.0001 and so on or not in up to five steps in either direction. At the end, just calculate sqrt(x*x+y*y) to obtain the scale factor.
Another would be to adapt the table of values to the decimal system in some way. One would begin with the arctangent of decimal 0.5, end with the arctangent of decimal 0.1, and use two suitable values in between to make the approximation process behave properly.
Or, if that can't be made to work sensibly, speed things up a bit by using seven steps for every two digits, since 128 is only a little bit bigger than 100, while 16 is a lot bigger than 10. So one might use the arctangents of 0.5, 0.25, 0.14, 0.7, 0.04, 0.02, and 0.01, and then repeat the cycle dividing by 100 each time; 0.14 is only a little larger than half of 0.25, and 0.4 is only a little larger than half of 0.7, thus avoiding strange behavior.
Although these methods are quite rapid compared to the conventional method of using the Taylor series to approximate a function, they are not the fastest methods known, at least asymptotically for numbers with very high precision. It is possible to evaluate these elementary transcendental functions, as it is possible to perform division, in a time comparable to that required for multiplication; that is, in a number of addition times proportional to the logarithm of the length of the number. Originally, CORDIC methods were applied to small computer systems with limited hardware resources, to which they are very well suited, but despite the possibility of better methods in theory for the case of very high precisions, the CORDIC methods are still useful in large computers as well, if they calculate transcendental functions in hardware instead of software. They are superseded by other methods, though, for multi-precision arithmetic, particularly in the régimes where one would use Schönhage-Strassen multiplication.
These algorithms, as described here, require comparisons to be made at each step, on the basis of which decisions are made. While it would not be possible to make the exact comparisons noted here without completing the additions, and performing carry propagation, can comparisons of a limited type be performed on numbers in the raw redundant form used with carry-save adders, and, if so, can these algorithms be modified to make use of such comparisons? One encouraging factor is that, since multiplication is not used, we do not necessarily have to contend with the negative values that are required for Booth encoding.
If, instead of having one binary number, we have two binary numbers that we wish to avoid adding, and we want to say something about their combined value by looking only at their first few bits, we can indeed say that if both numbers are of the form 000xxxxx, their sum is of the form 00xxxxxx. But some pairs of numbers not of the form 000xxxxx will also have sums of the form 00xxxxxx.
The modification of the CORDIC algorithms for this situation that suggests itself is something based on using twice as many steps, involving changes to the numbers of half the size at each step.
The hyperbolic functions sinh and cosh are defined as:
x -x
e - e
sinh(x) = ----------
2
x -x
e + e
cosh(x) = ----------
2
We know that
x+y x y e = e * e
and so we can derive the equations
sinh( x+y ) = sinh(x)cosh(y) + cosh(x)sinh(y) cosh( x+y ) = sinh(x)sinh(y) + cosh(x)cosh(y)
Here, since cosh(x) is always greater than sinh(x), we can choose values of y such that 1/(tanh(y)) is equal to 2, 1 1/2, 1 1/4, 1 1/8, and so on to produce sinh(x) and cosh(x) for arbitrary values of x, starting from some fixed value of x. Thus, for each step, we once again have:
-n
K * sinh( x + y ) = sinh(x) (1 + 2 ) + cosh(x)
n n
-n
K * cosh( x + y ) = sinh(x) + cosh(x) (1 + 2 )
n n
where K[n] is 1/sinh(y[n]), where (1 + 2^(-n)) = 1/tanh(y[n]).
As with the trigonometric functions, sinh(-x) = -sinh(x) and cosh(-x) = cosh(x), so, once again, we can "rotate" either clockwise or counterclockwise at each step, and we need to do so to keep the scaling consistent at the end if it is sinh, cosh, or the exponential function we are calculating.
Since cosh(x) + sinh(x) = e^x, this can be used as an alternative method of calculating the exponential function, or even logarithms. To calculate logarithms, we would start from a value for x based on the number whose logarithm we wish, so that the test performed in each round on the current approximation would not require scaling. Again, if the logarithm is desired, scaling ceases to be an issue.
The IEEE 754 floating-point standard set forth a very tough requirement for computer makers. Whenever an addition, subtraction, multiplication, division, or square root operation was performed, the answer had to be the right answer.
This is a difficult requirement to meet. If one uses an algorithm that yields only a good approximation to the right answer, even if one calculates that approximation to several more digits of accuracy than the desired result, there will always be a case when the result is 12345.4999... with an error of .0002 and you need to round it to only five digits. The fastest algorithms for division and square root above are in this class, but it is possible to check the result with a multiplication at the end. Because of this, the requirement was not imposed on functions such as the log and trig functions.
A way of meeting this requirement was explained, so that people would understand that it was possible to meet. It involved appending three bits to the end of numbers during actual arithmetic operations, a guard bit, a round bit, and a sticky bit.
The guard bit was already a well-known practice. Illustrating its importance with an example in decimal notation, let us suppose we are working with five-digit precision.
Start with
1.0000
and subtract
.99999
Without a guard digit, when .99999 is aligned with 1.0000, it becomes either 1.0000 or, if it is truncated instead of rounded, .9999. So the answer is either 0, or .0001. With a guard digit, we can get .00001, which is the right answer.
The round bit is needed because the guard bit can sometimes be lost during a calculation.
Start with
.98765
and add
-1
0.12421 * 10
Because the result is 1.000171, it has to be shifted to the right one place to fit in the computer register holding the result. The round digit ensures there is still extra precision, beyond the five digits of the final result, so that it is still possible to see it should be rounded to 1.0002 and not 1.0001. Incidentally, note that this shows that in addition to the Guard, Round, and Sticky bits on the right, the registers in which arithmetic is actually performed also need to have an oVerflow bit on the left.
The sticky bit lets one tell the difference between an exact .5, which needs to be rounded up half the time, and rounded down half the time, to avoid systematic errors (the usual rule being to round to the nearest even number, to avoid creating another 5), and odd fractions like .50001 which must always be rounded up. Its name explains how it works; the sticky bit is set when anything nonzero is shifted out of the right end of the register, no matter how small it might become later.
In order to ensure that numbers like .49999 don't get handled the wrong way, there is another important rule about the sticky bit: there are no carries out of the sticky bit; the attempt is not made to round what gets shifted in there.
Start with
23456
and add
.50112
and the result will be 23456.50*, and so it will be rounded to 23457.
Instead, start with
23456
and add
.49955
and the result will be 23456.49*, since the missing .00955 only sets the sticky bit, and isn't rounded to .01, and so it will be rounded to 23456.
When subtraction is performed, if the number being subtracted has its sticky bit set, increase that number by one in the round digit place, then set the sticky bit of the result; this will correctly indicate the result is a little bit more than the numeric value represented.
Note also that at most one number in an addition or subtraction can use the sticky bit, otherwise the correct result is ambiguous. This clearly is the case in addition or subtraction, as only the smaller number needs to be shifted right for alignment. What about multiplication or division?
In multiplication, if one starts from the least significant end, the partial products need never use the sticky bit; in binary multiplication, they will never need to be shifted right at all, since the cumulative total is always less than the partial product, and in other bases, at most one right shift, which makes use of the guard digit only, is required.
In long division, the sticky bit is never used at all, except to shorten the final result at the end.
The CORDIC algorithm, given above, had to be adapted to decimal operation to be used in pocket calculators. Many of the algorithms above, such as using recurrence relations to obtain reciprocals and square roots, are independent of the representation of numbers.
But what about carry-save addition, which provided the most significant increases in speed in multiplication, by making the time for adding together partial products significantly faster than a normal add time?
Since 1 + 9 + 9 = 19, changing two incoming decimal digits and an incoming carry to one decimal digit, and an outgoing carry to be moved to the next decimal place, is possible. And, of course, it should be possible, since once again it is a decimal full adder that performs the compression, just as a binary adder did in the binary case.
Since a binary digit is four bits long, though, adding two binary digits would produce carries inside the digit. One way to avoid this might be to represent a decimal digit as current going through one of ten different wires, and make circuitry that effectively performs addition by table lookup.
A compromise between that and conventional binary-coded decimal was used in the early days of computers, which was known as bi-quinary notation.
A decimal digit was represented by two values, one which could be either 0, 1, 2, 3, or 4, and another which could be 0 or 5.
This could be easily converted to and from 5421 weighted binary notation, but, currently, the convention is to represent numbers with 8421 weighting, in natural binary-coded decimal. A small change to bi-quinary notation, however, would adapt it to work with conventional binary-coded decimal; simply represent a decimal digit by two values where one is either 0, 2, 4, 6, or 8, and another which could be either 0 or 1. This does have one drawback, as one has to test both parts of a digit to determine whether or not it is 5 or greater, for telling if a number in ten's complement notation is negative, but if this format is simply used internally for computation where the numbers involve have already been tested for sign, it should not be a concern.
The diagram below
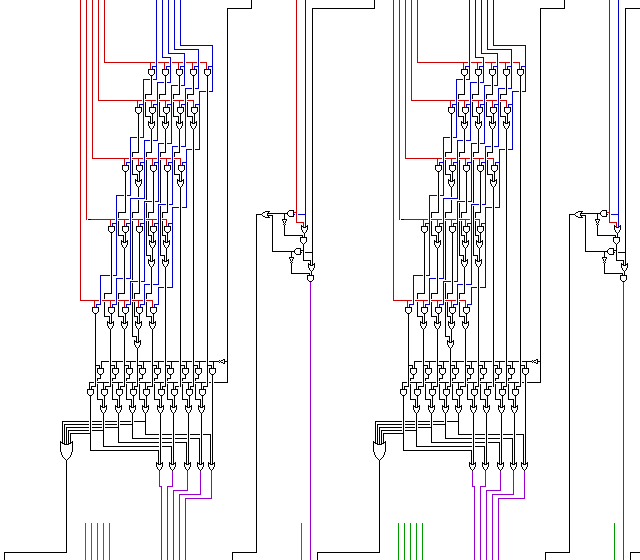
shows two digits of a carry-save adder working in what we might call qui-binary notation, or simply reversed bi-quinary notation. (In fact, in doing a search for information on bi-quinary coding, I find that the term "qui-binary" has, in fact, been used previously, particularly in connection with counter circuits: as well, the advantage of the qui-binary system in having a closer relationship to conventional BCD is noted, for example, in U. S. Patent 3,308,284, with inventor Harold R. Grubb, assigned to IBM.) For clarity, the two operands of the addition are shown in the diagram in red and blue, and then the output is shown in purple, with an additional operand that can be introduced for the next stage shown in green. The internal wiring, including the carries, remains in black.
Note also that while in one portion of the diagram, an OR gate with five inputs is shown, while in another portion, to limit the number of signal wires in a crowded area of the diagram, it is assumed that an OR gate with three or four inputs is to be realized by a two-level tree of OR gates. This would, in an actual realization of the circuit, be adjusted for consistency with the requirments of the logic type in use, and to achieve the minimum realizable gate delays therewith.
At first, I thought that it has only been as recently as 2003 that decimal carry-save adders have been discussed in the literature, in a paper by Erle and Schulte, but I have since been apprised of a paper by D. P. Agarwal from 1974 in which decimal carry-save addition was discussed. It appears from that paper that there are also ways to minimize the number of gate delays involved in a BCD full adder such that a resort to biquinary arithmetic can be avoided, although this scheme at least has the merit of being simple to illustrate.
What about the inputs to the Wallace tree?
If one has all the multiples of the multiplicand from 0 times the multiplicand to 9 times the multiplicand, then the terms to be added can be selected. With binary arithmetic, the issue of Booth encoding only arises if we try to multiply by two or more digits at once; with decimal arithmetic, we seem to face the issue even with a single digit.
Are we going to have to build a Wallace tree with a base so broad that we spend the first three layers of the tree adding together up to nine copies of the same number?
As it happens, biquinary notation comes to our rescue again. In biquinary notation, the values of the components of the digits are:
500 100 50 10 5 1
where you can have either 0 or 1 times the 500, 50, and 5, and either 0, 1, 2, 3, 4, or 5 times the 100, 10, and 1.
In quibinary notation, on the other hand, the values of the components of the digits are:
2000 1000 200 100 20 10 2 1
where we can have either 0 or 1 times the 1000, 100, 10, and 1, and either 0, 1, 2, 3, 4, or 5 times the 2000, 200, 20, and 2.
Now, it happens that 1000 is twice 500, and 200 is also twice 100. And thus, we can, by encoding a decimal number into biquinary, and shifting it one place left, turn it into the quibinary form of twice itself.
For example,
4 7 3
is 01 10000 10 00100 01 01000 in biquinary,
and 00001 01 10000 10 00100 01 01000 01 in qui-binary
is 0 9 4 6 in decimal
Similarly, by encoding into quibinary, and shifting one place left, we get the biquinary form of five times the number. So we can, through suitable encoding and decoding into mixed radix systems, obtain what is in essence a fractional digit shift.
Instead of having to allow nine partial product terms for every digit in the multiplier, we can encode the digits of the multiplier using a 5221 weighted code, and then add together four partial product terms per digit. This matches the performance of binary multiplication without Booth encoding.
Without the need for anything resembling Booth encoding, we can still double that performance. Since nine times nine is eighty-one, which is only two digits long, by separating the digits in odd and even digit positions into two separate numbers, we simply need a multiplication table to form, without carries, all the basic multiples of numbers every second digit of which is zero. Hence, we now have only two partial product terms per digit, which, if decimal were hexadecimal, would match the performance provided for binary arithmetic by Booth encoding.
Incidentally, as this would work equally well for any number base, not just base-10, and recalling, as we noted above, that it was difficult to make Booth encoding to work as well for more than two bits at a time, it may be noted that if one uses multiplication tables that go up to 1,023 times 1,023, so as to work in base-1024, one can obtain the same amount of reduction in the size of the base of the Wallace tree, and hence the same savings in circuitry, as one could by having an effective means of Booth encoding for five bits at once. Of course, large lookup tables also consume available resources. And one needs to use a 15 times 15 table, involving two four-bit inputs, to match the performance of standard Booth encoding which simply operates on two, rather than four, bits at a time, thus, Booth encoding is to be preferred where feasible.
Even a times table going up to 9 times 9 is something to avoid if we can. Using the trick given above of shifting between bi-quinary and bi-quinary representations, we can, without carries, multiply a decimal number by 4 or 8 as well as by 2 or 5. Can any multiple of a number from 0 to 9 be formed by adding together at most two multiples from the set 0, 1, 2, 4, 5, and 8?
Why, yes.
3 = 1 + 2 6 = 2 + 4 or 1 + 5 7 = 2 + 5 9 = 4 + 5 or 1 + 8
Since 8 is 4 + 4, we don't even need to bother doubling three times in succession to obtain that multiple. So we can limit the number of terms entering the base of the Wallace tree to two for each term in conventional multiplication without the need for a decimal multiplication table.
It was pointed out to me, when I mentioned this in a newsgroup, that performance could be improved still further if one simply used carry-save addition to produce all the multiples. Each resulting multiple would then consist of one decimal number, and one set of carries; since up to nine sets of carries could be fused into one decimal digit without carries, that would be more efficient.
Upon reflection, however, I realized that the first layer of the Wallace tree would convert the multiples obtained by my biquinary/quibinary method to that form as well, and so the only question is whether several stages of carry-save addition, or my conversion system, is quicker. One can always save circuitry for lengthy multipliers by doing the conversion on the multiples instead of having a full first layer of the Wallace tree.
Upon further reflection, however, I realized that this brought up a very important detail that I missed concerning the decimal version of the Wallace tree. Since nine sets of carries are equivalent to one digit, and the stages are not 3 to 2 compressors any more, but 2+1 to 1+1 compressors, where digits are distinguished from single-bit carries, one can improve matters by gathering bunches of carries and turning them into decimal digits.
Not all attempts to find a faster way of doing arithmetic have yet been successful.
If one is doing arithmetic on integers guaranteed to be in the range 0-1000, since 1001 is equal to 7 * 11 * 13, one could add, subtract, and multiply independently the residues of those numbers modulo 7, 11, and 13, and get a result which uniquely identifies the answer.
However, actually producing the number, while the Chinese Remainder Theorem says it is possible, is too much work for this to be practical. Or so it seems.
In fact, though, while the original idea of radix arithmetic has not worked out, a closely related method is used for such operations as calculating pi to large numbers of digits.
If one wishes to determine the remainder of a long decimal integer modulo nine, one can do so by taking the sum of its digits. And to determine the remainder modulo eleven, one can do so by taking the difference of two sums of alternating digits, 1, 100, 10000, and so on all having remainders of 1 modulo 11, and 10, 1000, 100000 and so on all having remainders of 10 (or -1) modulo 11.
Similar methods can be used for finding remainders modulo 99 and 101, 999 and 1001, and so on, and were it not for the fact that, for example, determining remainders modulo 99 and 101 only gives you a unique remainder modulo 9999 and not one modulo 10001, an algorithm for converting to and from a nested radix representation resembling a fast Fourier transform would work.
One could remedy the flaw by using longer radices, but another algorithm for performing a Fourier transform on the digits of numbers, one which retains the imaginary part as well as the real part of the transform, has instead been the one to meet with success - Schönhage-Strassen arithmetic.
Since addition is quicker and requires less circuitry than multiplication, some systems convert numbers to their logarithms at the time of input, retaining them in this form only in memory.
Occasionally, though, one has to add and subtract as well as multiply and divide. A paper by S. C. Lee and A. D. Edgar, "The FOCUS number system", described a way to do this using a relatively short look-up table.
If you with to add two positive quantities, x and y, of which x is the greater, simply use log(y/x), which can be obtained by subtracting log(x) from log(y), both of which you have, and use that as an index into a table of log( 1 + y/x ), which result may be added to log(x) to give log(x+y).
If, instead, you wish to subtract y from x, use log(y/x) as an index into a table of log( 1 - y/x ), which again gives what you need to add to log(x) to get your answer.
And, of course, the assumption that y is less than x, and both are positive, is without loss of generality, since one can use their absolute values, and interchange addition and subtraction if they are of opposite sign, and interchange the two numbers if the wrong one is smaller in absolute value.
These tables are tables of Gausiann logarithms, also called Addition Logarithms and Subtraction Logarithms. For speeding up arithmetic with low-precision quantities, when computation was slow but memory was fast, it would work, but it does not seem to be applicable, say, to speeding up arithmetic on double-precision floating-point quantities.
However, it is not necessarily the case that this method is utterly unsalvageable. Given that we're dealing with tables of quite smooth and continuous functions, which, as we look at them at a larger and larger scale, approach being linear, one could imagine using a short table, plus low-precision arithmetic for interpolation, as a means of doing high-precision arithmetic.
In general, though, computers aren't designed to make any worthwhile time savings from such a method possible, as they optimize common and straighforward operations.