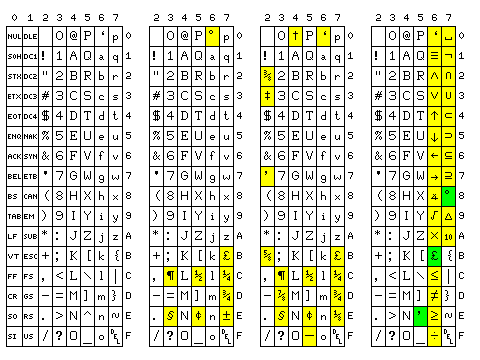
Quite a long time ago, I had felt that there ought to be a standard modified version of ASCII for use in word processing applications:
replacing the characters not normally found on a typewriter by additional characters which are found there. One could do the same for a basic set of characters appropriate to a typesetting keyboard as well, shown in the third chart above, or for a set of characters for computing, as shown in the fourth chart. I think that originally I interchanged the substitutes for ~ and \ as when I first had the idea, I wasn't thinking exclusively in terms of the now-ubiquitous keyboard layout derived from the 101-key Model M keyboard:

Similarly, if that keyboard layout is to be used without any change, the substitutes for ` and " would need to be interchanged for the typesetting character set, but that gives a character equivalent in meaning to ` the code for ", which seems inappropriate.
Changing a few characters within the basic 94-character printable characters of ASCII originally was not unusual, when ASCII was strictly a 7-bit code;
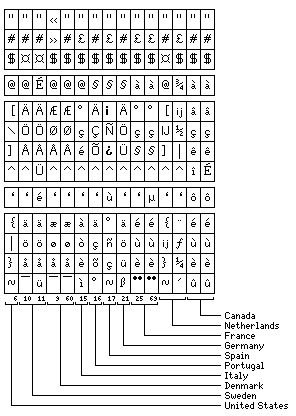
as this was done to accommodate the accented letters used by numerous languages. Later, those first 94 printable characters were kept constant in codes derived from ASCII that were 8 or 16 bits long.
Thinking in terms of Unicode, and its extension of ASCII to what was, at first, a 16-bit code (although it was only Unicode 1.0 that was strictly defined as a 16-bit code) to support other languages, it seemed to me that because some foreign languages have more than 32 letters in their alphabet, it was a pity that what we think of 8-bit ASCII (officially, ISO 8859-1) couldn't have been restructured significantly, rather than having its first 128 characters kept strictly compatible with ASCII:
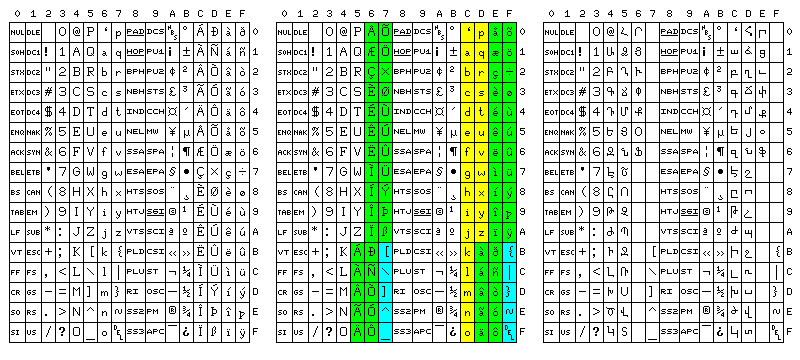
As noted above, I felt that alternate ASCII character sets for computation and word processing would have been useful. This was still the case even when ASCII was expanded to eight bits from seven:
The multiplication and division symbols used in grade school textbooks weren't particularly important characters, and so the OE ligatures should have been left in those code positions for ISO 8859-1. But the emphasis on accented letters, while understandable to facilitate international use, meant the code was chiefly oriented to word processing.
It didn't include the symbols for less than or equal to, not equal to, and greater than or equal to, which seemed to me to be the most important deficiencies of ASCII when used for writing computer programs. And so, I put those characters in, along with the characters I removed from ISO 8859-1, in the computing character set, along with the Greek alphabet.
Finally, another anomaly of 8-bit ASCII is the code positions used for control characters.
Control characters certainly are important for a code used for communications between a computer and a computer terminal. But they really aren't very useful for a code used to store documents as files on a disk drive.
These days, computers usually don't have terminals connected to them - instead, the computer is the terminal, as this keeps hardware costs to a minimum.
Taking out the control characters, except for 00 being NUL and FF being DEL, allows including small capitals as a basic character case in the code, having the same status as upper and lower case - instead of being treated as a presentation form which requires a switch to a different font.
I'm willing to accept that boldface and italic are presentation forms, but the keyboard ought to include keys for switching to those as well, rather than requiring one to lift one's hands up and use the mouse to select text and switch to them.
However, doing away with control characters might be just a tad too radical.
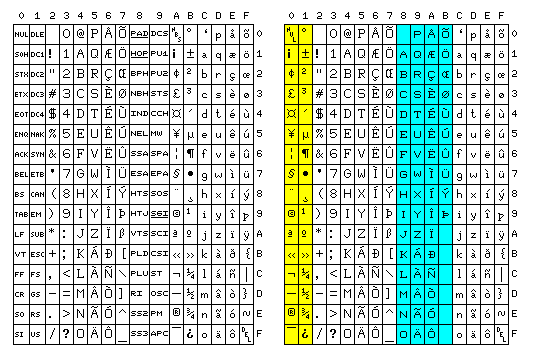
Using the word processing form of ASCII as a basis, and keeping only the most important additional characters, one could arrive at the following 8-bit character set to serve as the starting point for a code:
However, while I tried to pick the most necessary of the added special characters, this is too tight a squeeze. The Euro symbol really ought to be added, if one is going to make changes, and several other highly useful characters had to be left out.
Note that, though, with the restructuring done to accomodate languages like Armenian, it is no longer as convenient to handle Chinese, Japanese, or Korean with a double-byte character set (DBCS). At least, though, with this design, it's not completely impossible. With ISO 8859-1 in its original form, the printable characters with the high bit set allowed 94 possible prefix characters as the first character of a two-character code representing one Chinese character. Using the high bit to indicate lower case had spoiled that. But with a space reserved for small capitals, at least those 32 codes could be used as DBCS prefixes. Given the full integration of the high bit, the second character could be any of the 222 normal printable characters, rather than being only one of 94 characters.
This doesn't mean that the situation for DBCS coding has improved, as 2 times 94 times 94 was always an option that had been easy to take, and the Big-5 coding had made use of that option.
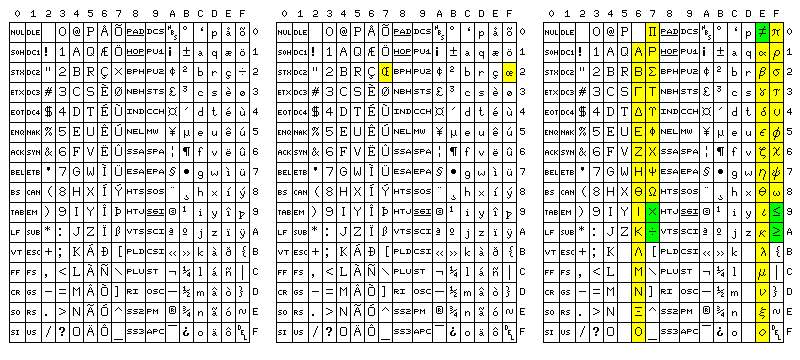
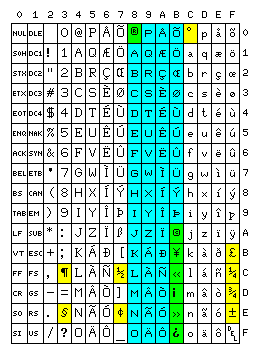
Considering that many control characters aren't used, while some are, and that the two possible 8-bit codes for technical and word processing use would be derived from portions of a 16-bit code, which would have to be modified from Unicode to fit a significantly modified basis that replaces ISO 8859-1, this diagram indicates how enough room for new currency symbols might be obtained:
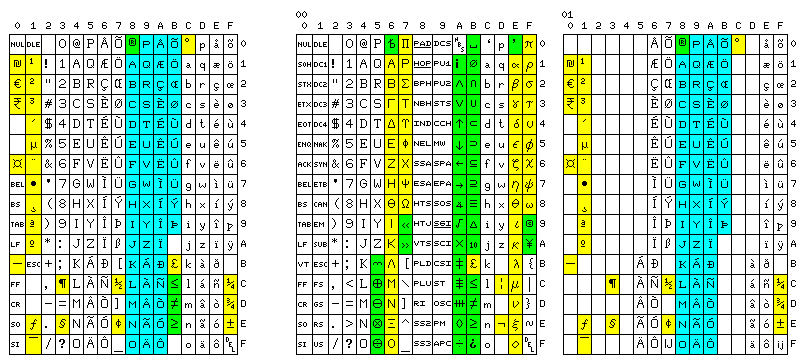
After taking some time to examine the history of the development of ASCII, an even stranger idea occurred to me.
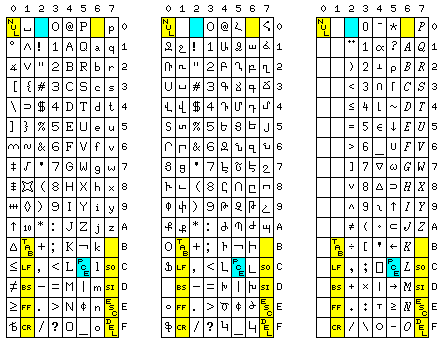
First, I thought, when adding lowercase to ASCII, the old ESC and ALT MODE characters could have been left in their old places; except for the lower case letters, instead of adding printable characters, one - the backslash - could even be subtracted. Then there would be 89 printable characters, one of which would be the space, matching the size of a conventional typewriter keyboard, and removing the temptation to add keys in awkward places on computer keyboards.
A truncated ASCII of this sort is depicted in the first section of the diagram above.
Later, I developed this idea further, as can be seen further down on this page.
Then, I thought, if ASCII is to be modified to reflect the typewriter keyboard, perhaps some characters could be moved around so as to allow a bit-pairing keyboard to have its characters in the normal positions of a typewriter keyboard, rather than forcing people to wait until the technology advanced before they could enjoy typewriter-pairing keyboards.
The second diagram shows a possible arrangement with this goal in mind. The third diagram shows an even more radical rearrangement; it has the one flaw, though, that because it is assumed the period and comma are never shifted, it interferes with providing an alternate APL keyboard layout.
The fourth diagram shows the rearrangement in the third diagram, with typewriter alternate characters. Note that some pairs of symbols are assigned in reverse compared to the typewriter arrangement shown at the top of the screen; this is because characters that occured on the shifted keys on a typewriter were, in that earlier arrangement, put on the "first" key - the one on the left - when the two characters were split between two different keys.
Instead of a new version of, or a replacement for, ASCII, this code could be considered as a terminal connection code - used strictly for computer terminals, with translation to ASCII being done for intercommunication.
On another page, near the bottom, I suggest another scheme for a modified version of ASCII, with a different goal in mind.
When lower-case letters were added to ASCII, several additional characters `, {, |, }, and ~, were added as well. This meant that ASCII terminals which supported lower-case had keyboards which would have three or four more keys in the main typing area of the keyboard than a typewriter with a full keyboard (that is, one that had the digit 1 on a key of its own, and that had the + and = symbols on a key on the right).
This can be handled gracefully enough - the 101-key US version of the Model M keyboard for the IBM PC causes no problems for touch-typists.
But a lot of the earlier lower-case ASCII terminals, and even earlier keyboards for the IBM PC, were not so convenient to use.
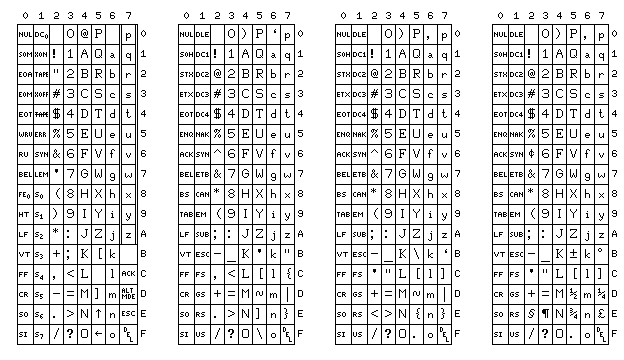
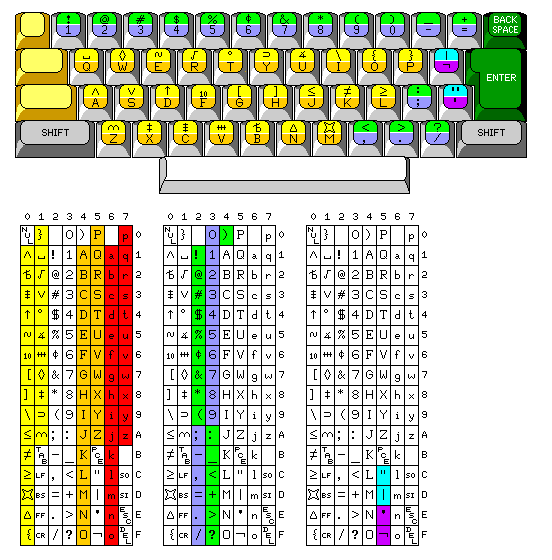
And so I proposed that ASCII ought to have been modified, in the manner shown in the diagram on the right.
Don't add the five new characters - and, indeed, also remove the backslash.
Also, due to another issue that came up in the history of ASCII, making ASCII ! correspond to EBCDIC | instead of EBCDIC ! so that PL/I programs could be written in the uppercase-only subset of ASCII, I removed the square brackets, and replaced them by vertical bar and logical NOT.
The first diagram shows how I would change ASCII, the second one how an alphabet with more letters, in this example the Armenian alphabet, would fit into this modified ASCII, and the third one how APL terminals would work.
Instead of having fewer printable characters than conventional ASCII, though, I manage to have more. I do this by taking away 26 of the control character positions - so after taking away six characters, I add twenty-six characters, for a net gain of twenty. The square brackets and the backslash are back, along with characters used by ALGOL and characters used on some older IBM computers. The idea is that a terminal handling my proposed modified ASCII could operate in two modes - one where the letter keys type lower-case, unless shifted to produce upper-case, and another where the letter keys type upper-case, unless shifted for one of those 26 additional special symbols.
For ASCII, after lower-case was added, there were two kinds of keyboards, the bit-pairing keyboard and the typewriter-pairing keyboard. In the bit-pairing keyboard, shifting a character always inverted one or two of its high-order bits; these keyboards followed the pattern that was universal for upper-case only ASCII keyboards, but with added keys. The typewriter-pairing keyboard resembled that of a typewriter more closely, but now larger ROMs were needed because in some cases the codes for the shifted and unshifted character on a particular key were not related.
So the diagram to the right here shows how a further modification allows a simple keyboard, constructed like a bit-pairing keyboard, would still have a conventional electric typewriter arrangement of characters.

Of course, it's much too late now to make such a radical modification of ASCII. So the diagram on the left illustrates another possibility. What if the modified ASCII discussed above were instead treated as a separate code, let's call it TERMCODE for "Terminal Code", and have terminals using this code connected to computers that then translate it to ASCII for internal use - but slightly modified so that the character set remains the same.
In the diagram, the code chart on the left shows how ASCII might be modified in such a scenario, and the code chart on the right shows the corresponding version of TERMCODE.
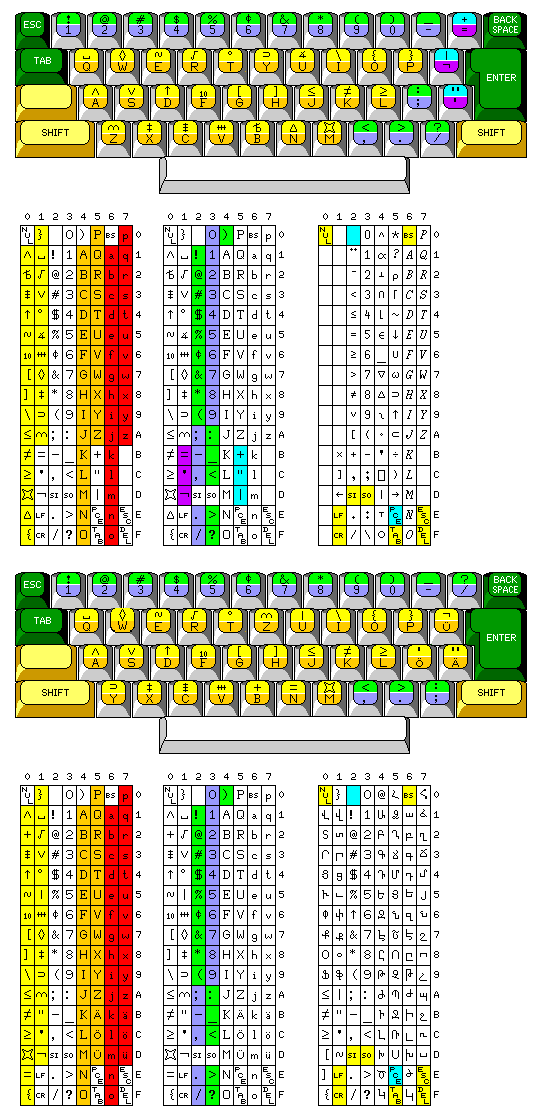
Upon reflection, however, at the cost of further restricting the available control characters, and more radically modifying the original ASCII arrangement, the scheme shown at left allows three additional keys on the keyboard to be changed from carrying special characters to carrying letters of the alphabet.
In the upper half of the diagram, the code chart on the right shows how the assignment of the characters on the APL keyboard is changed to correspond to this modified coding.
This way, at least it becomes possible to use this code for a German keyboard, as illustrated in the lower part of the diagram, with some limited re-assignment of code points.
While it doesn't provide for direct support of languages with longer alphabets, such as those with the Cyrillic script, the partial support of Armenian, in the sense that it can at least be coded in a straightforward manner, even if the keyboard mapping is no longer quite as simple, is actually improved, as the code chart in the lower right of the image shows.
Too many control characters would be lost if more than three letter keys were added to the keyboard. The IBM Selectric Composer had Nordic elements available, which required five additional keys to be used for additional letters, but I see that the individual keyboards for Norwegian, Swedish, and Danish only require three additional keys each:
German: Ü Ö Ä Norwegian: Å Ø Æ Swedish (and Finnish): Å Ö Ä Danish: Å Æ Ø
so those languages can be properly supported as well.
On the other hand, Icelandic, Hungarian, and Croatian are examples of languages which require more than three keys for additional letters with both upper-case and lower-case, while both Spanish and Portuguese, requiring less than three additional alphabetic keys, pose no issue.
Many older computers used six bits to represent a character. That was adequate for the upper-case Latin alphabet, the ten digits, and a reasonable selection of punctuation marks, quite enough to allow computers to be used in a pedestrian manner for the kind of no-nonsense commercial and scientific work that computers were used for when their use cost hundreds of dollars an hour.
These days, of course, things are different. We use computers to type letters, as that makes it easier to correct typing mistakes... just as one example (the application known as "word processing") of how we can use computers for less awe-inspiring purposes now that they're rather less expensive.
However, even when one has a lot of memory available, one can turn that memory into a lot more memory if one uses it more efficiently. As well, elsewhere on this site, I devote a whole section to various schemes of making it practical to use data in formats that are multiples of twelve bits in length on the basis that this permits the use of floating-point formats that provide a more optimal assortment of available precisions (on the basis that 32 bits is too short, whereas 36 bits is useful for many things; 64 bits is too long, whereas 60 bits is plenty, and most of the time, 48 bits is just right, as proven by the fact that pocket calculators usually show numbers to 10 significant digits).
And so I illustrate below a character code that allows the flexible and efficient use of six bit character cells:
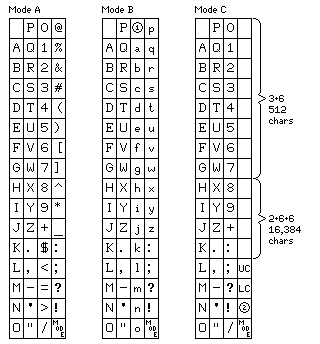
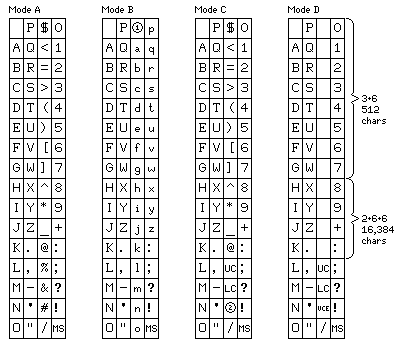
The normal starting state of this six-bit encoding is in Mode A. An ordinary and pedestrian encoding of characters in six bits, except that there are only 62 printable characters provided in addition to the space.
One character is reserved to set the mode. Which mode has to be indicated by the character that follows it. Note that the first 27 characters are the same in all three modes, the space followed by the 26 letters of the alphabet, however, this isn't a necessity for the proper functioning of the mode escape character; its effect depends on the numerical code of the following character, not the character it currently represents.
Thus, in Mode A, you have 63 characters, and that's it. The 26 letters are always in upper case in this mode.
Mode C offers a 48-character set only. In the old days of computing, people managed with that; a 48-character set with a slightly different choice of characters than is shown here was adequate for printing invoices and paycheques (characters such as ?, !, and " would be dropped in favor of & and *, the former being needed for some company names, and the latter needed for printing paycheques).
But it offers some more things as well.
There are two control characters labelled UC and LC. These shift the letters between upper-case and lower-case; they do not change the other printable characters so as to provide 96 characters, however.
Instead, eight of the last sixteen characters in the code are prefix characters. Combining one of those prefix characters with one additional characters allows an additional 512 characters to be represented.
As well, another four of the last sixteen characters are prefix characters to be followed by two additional characters. This allows characters to be represented by fourteen bits, giving a set of 16,384 characters, which is enough to allow Chinese-character text to be included.
The 512-character set will mostly be used for mathematical and programming symbols.
Languages with different alphabets or even just accented letters will instead be supported by using other characters following the mode selection character. Mode followed by space will return to the plain Latin alphabet and the character set shown in the diagram. Mode followed by a character from E onwards will select a different language, and each language will have its own Mode A, Mode B, Mode C, and Mode D best suited to its own character set.
Before discussing what Mode D looks like, let's turn to Mode B.
If one is going to store a text document on a computer, it will use both upper-case and lower-case letters, so avoiding the need to use shift characters to access them will save space. Fitting 52 letters in two alphabets into 64 codes means there isn't quite enough room for both the ten digits and even the most common punctuation marks, and so the digits are omitted.
The circled 1 indicates a control character used to shift to Mode C'.
Mode C' is the same as Mode C, except that the control character shown as a circled 2 shifts to Mode B (instead of using both the mode shift character and a B, which takes two characters instead of one).
In the regular Mode C, the control character shown as a circled 2 is the Upper Case Escape character; if it is followed by the code for a letter, it shifts that letter to upper-case, without shifting out of lower-case mode if the text is in that mode. This makes text with upper and lower case characters more compact when represented in Mode C, even if Mode B is also available to make it even more compact.
Now for Mode D. For a language other than English, the requirement for accented letters, or a larger alphabet, may mean that it will be impossible to fit the alphabetic characters of that language into either Mode B or Mode C in a practical manner, to say nothing of Mode A.
Mode D is basically Mode C, but without the twelve prefix characters - instead, they are available for use as additional printable characters. So a language can have significantly more than 26 letters, and still have access to the UC, LC, and Upper Case Escape control characters to allow upper-case and lower-case to be mixed in an efficient manner.
Just as the 63 characters of Mode A are such as would be associated with a text-only computer code without control characters, while there are control characters for the purpose of selecting additional printable characters, there are no conventional control characters such as carriage return, line feed, tab, back space, and so on in the code; it's strictly a code for storing text, and it would need to be supplemented for communicating with peripheral devices.
One could embed it in a 128-character 7-bit code for that purpose - or just embed it in a 70-character 4 of 8 bit code, which gives six additional characters, some of which could be used as escape characters if more control characters are required.
However, after some further thought, I realized that I could do better.
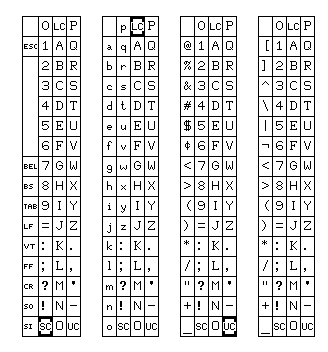
Here, Mode C and Mode D are now interchanged, however, the old mode D, which is now mode C, is now the one that Mode B switches to with a single control character.
The main improvement is that it is no longer necessary to change the codes of any printable characters between modes; this is achieved by not putting the case shifting characters and the prefix characters in the last column, where they conflict with the very important punctuation marks placed after the lower-case letters in Mode B.
Also, the Mode Shift character is now noted by MS instead of trying to fit the word "Mode" into a box too small for it.
Some additional words about how this code works for other languages are also in order.
In the case of a language using the Latin alphabet, but with additional accented letters, what is envisaged is this: only Mode C will be modified for that language. The modification will consist in replacing some or all of the characters available in Mode C, but not in Mode D (as they are in the positions used for prefix characters in Mode D) by the additional accented letters.
Characters so replaced, if applicable, will also have both an upper-case and a lower-case form if applicable, and be affected by the upper-case or lower-case shifts.
Having twelve characters available in this way means this scheme will even work for Armenian, as well as most languages with the Cyrillic alphabet.
And Georgian has 33 letters at present, and without case shifting in normal use, it is even easier to support.
However, changing the language may modify any or all of the modes.
If Chinese is selected, Mode D would be modified so that the 512 double-character characters include many of the most common Chinese characters, to bring the average length of Chinese texts closer to 12 bits per character than 18 bits per character.
If Korean is selected, as there are more than 512 syllables that can be written in Hangul, only the more common ones can be coded with only two characters. Of course, jamo would also be used in mode C.
In the case of Japanese, using upper-case for katakana and lower-case for hiragana in mode C is the obvious convention. However, as more than 38 kana are present in either system, additional characters will need to be replaced in that mode.
Recently, the idea of a six-bit code had crossed my mind again, but this time, I thought of one with a different structure:
Again, there is a mode with only upper-case letters, and a fairly typical complement of special characters, as found with a typical six-bit code. And there is a mode with both upper-case and lower-case letters, with only the most essential punctuation marks, and not even the ten digits, available.
But this time, in addition to "Upper Case" and "Lower Case" shift characters, there is also a "Stunt Case" shift character. Then there are the upper-case letters and the ten digits... and fifteen control characters. Having control characters available makes the code a more general purpose code, which can be used to communicate with terminals and other devices, as well as being used for textual data storage within the computer.