
On the preceding page, we have met some keyboards which were quite complicated, because they allowed typing the APL character set as well as that of conventional ASCII, or they included additional characters used for mathematical or typographical purposes.
It should be noted that some languages make demands on a keyboard which lead to it being rather more complicated:
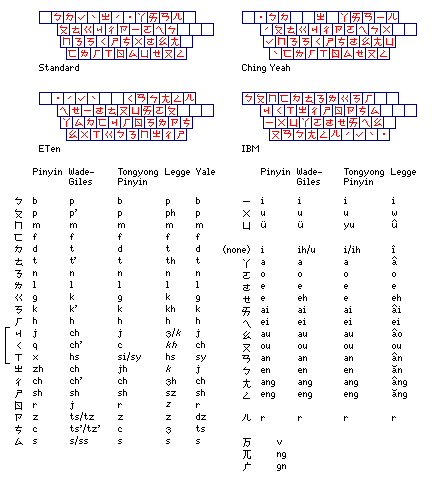
On the top face of the keys, on the left we have the Chinese National Alphabet, Zhuyin Fuhao, or Bopomofo, on the top, and the characters for the Ts'ang-hsieh (Cangxie) input system on the bottom. On the right, a Korean keyboard layout is shown in the otherwise empty space atop the letters. On the front of the keys, the left is given to a Japanese katakana layout, while APL takes up the center and its overstrike characters take the right.
I even drew a slightly more complicated version of this keyboard, in which the Korean keyboard layout was moved to the front of the keys, its space on the right of the keys above the letters taken by the Wubizixing layout, popular in Mainland China:

Of course, real keyboards aren't that complicated in practice; one wouldn't see Japanese and Korean together with Chinese on the same keyboard, and only a couple of input methods would be provided at a time: thus, the main part of a real Chinese-language PC keyboard can look like this:
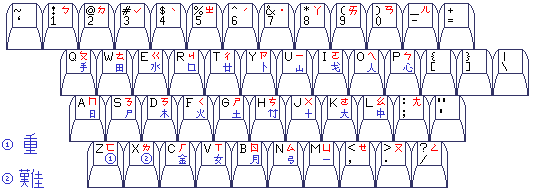
providing the National Alphabet at the top right in red, and the Ts'ang-hsieh at the bottom right in blue. The two symbols I simply left out as too complicated to draw in the space available are here footnoted with two circled numbers; they act as escape characters for the system: (1) Chung, meaning heavy, and thus used for characters with many strokes or many subordinate elements; (2) Nan, meaning difficult, and thus used for characters, regardless of complexity, for which it is difficult to determine or remember how they should be represented in the system.
A photograph of such a keyboard is shown below:

And here is a photograph of a Korean keyboard:

The Japanese keyboard arrangement included in the keyboard diagram above is the old Katakana arrangement, generally used with terminals that could only print or display the Katakana syllabary. Even conventional typewriters were made for typing Japanese in katakana only. The arrangement of such a keyboard is shown below:
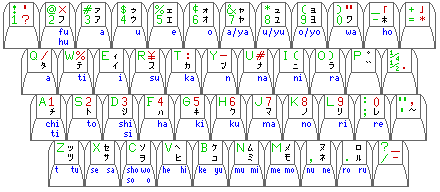
Characters shown in red generally are omitted when the Katakana syllabary is placed on a computer keyboard that can also be used to type by means of a conventional Latin-alphabet typewriter layout; instead, special characters and punctuation marks are typed by switching to that layout.
On the front of the keys, the phonetic values of the Katakana symbols are given in blue; where two Katakana symbols are on the same key, the phonetic value of the shifted one is on the left. In some cases, the official transliteration of Japanese differs from what an English speaker would consider the phonetic value of a Katakana symbol to be; in this case, the official transliteration is given below the conventional phonetic value from the Hepburn romanization.
Computers that handle the Japanese language today and are capable of displaying the Japanese language properly generally use a different keyboard arrangement, in which the keys are labelled using the Hiragana form of the syllabary instead.
Here, red is used to indicate both punctuation marks and special symbols that are included as part of the Japanese keyboard, and also to indicate, on the front of the keys, symbols that are different in the Roman alphabet layout on a Japanese keyboard from the standard U.S. English layout (which is still shown in green on the keys in this diagram); note that the arrangement is based on the bit-pairing layout.
The layout used with the IBM PC is shown below:
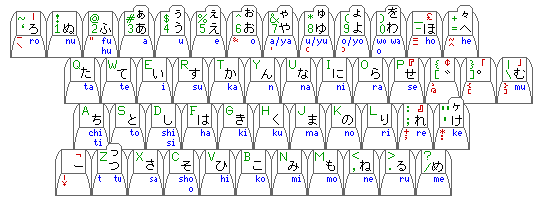
Note (from the phonetic values given on the front of the keys) that in most cases, the Hiragana symbols are located on the same keys as the corresponding Katakana symbols on that type of keyboard.
With both Japanese and Korean, a standard keyboard arrangement was adopted, based on the existing phonetic scripts that each language had.
In the case of Korean, while Hanja (Chinese characters as used in writing the Korean language) are occasionally used to represent scholarly terms derived from Chinese, the overwhelming majority of text is written entirely in the Korean alphabet. However, while Korean is written with an alphabetic script, its letters are not arranged in the linear fashion common to European languages, but are instead clustered together in syllables. This complicates the display of the Korean language, but not its input. Korean keyboards for the PC platform do, though, have a couple of extra keys for the purpose of making it easier to specify when a Chinese character is to be indicated.
In the case of Japanese, Chinese characters as used with the Japanese language, called Kanji, are in constant use. Even with the fact that a Kanji character usually has two possible pronounciations, Kun-yomi and On-yomi, representing the native Japanese word and a Japanese compound form derived from Chinese, a Japanese-language input system can basically operate by using a Japanese dictionary to find the correct form in which to write a Japanese word the pronounciation of which was typed. The Japanese PC keyboard does have several extra keys to allow a character to be specified directly in ambiguous cases, however.
Written Japanese consists normally of the roots of words written in Kanji and grammatical suffixes written in Hiragana, with Katakana used only occasionally either for honorific purposes or to represent foreign words, or for such things as onomatopoeic representations of sounds.
It is only in the case of the Chinese language that no consensus on an input method based on the Western typewriter keyboard has developed, and methods based on a character's component parts are used in addition to phonetic input methods, which is why I am only examining Chinese-language input systems in (a very limited amount of) detail here.
The DaYi input system sometimes accompanies the two systems shown above on Chinese-language keyboards for use in Taiwan, leading to a keyboard arrangement like the one below:
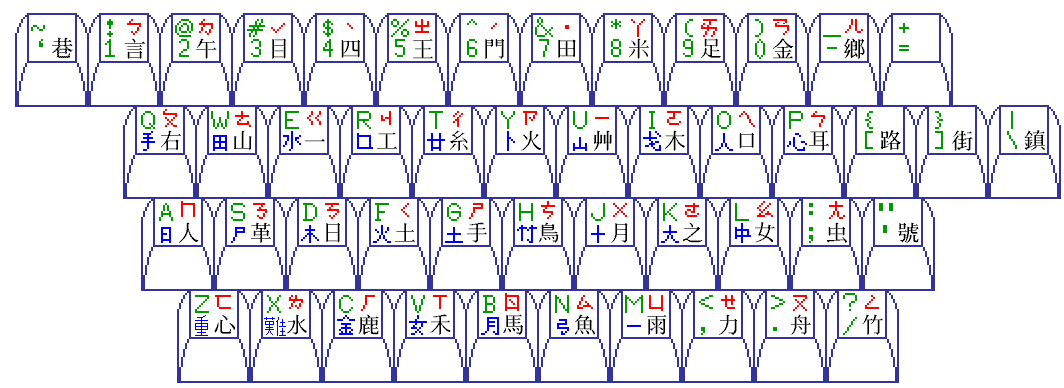
To include it on a smaller keyboard diagram, I placed the characters of the DaYi scheme on the front of the keys, where there is more room because they are there by themselves, and replaced them with those of the Wubizixing system, which is an arrangement found on some keyboards in Hong Kong, and obtained this:

Because the keys used for the Zhuyin Fuhao phonetic signs include the numeric keys, the version of this input method for some platforms avoids using them for choosing a character from multiple alternatives; so the numbers from 1 to 5 in purple show which keys are used for that purpose in some cases. Other versions, such as those designed for cxterm do not have this difficulty, and do use the numeric keys.
The Zhuyin Fuhao phonetic symbols are shown in their most popular keyboard arrangement; other arrangements are also used. The diagram below shows a few of the most common arrangements of these symbols, and also shows the sounds they represent as given in some of the many transliteration systems devised for Chinese.
In the case of the transliteration systems other than that of Legge, it should be noted that many of the subtleties of these transliteration systems are not addressed below; in the case of the Legge transliteration system, the contents of the table should merely be regarded as giving examples of what may be arrived at in that system, and should be regarded as purely illustrative.
In the column on the right, the last three symbols, the sound value of which is not given under any of the columns for transliteration schemes, are three additional symbols which were part of the original [National] Phonetic Alphabet (Chu-yin Tzu-mu/Zhuyin Zumu) representing initial sounds not found in the Mandarin as spoken in Peking, before it was changed to the [National] Phonetic Signs (Chu-yin Fu-hao/Zhuyin Fuhao) to indicate it was intended for annotating Chinese characters rather than for use as a system of writing in itself.
And, given that the illustration above, showing something of the diversity of transliteration schemes for Chinese, may have piqued one's curiosity about what sounds could be so variously transcribed, the following table indicates something of how the consonants of the Mandarin dialect of Chinese are pronounced:
PY WG PY WG PY WG b p b* g k g* zh ch j*** p p' p k k' k ch ch' ch*** m m m h h kh sh sh sh*** f f f j ch jy** r j r*** d t d* q ch' chy** z ts dz* t t' t x hs hsy** c ts' ts n n n s s s l l l
The three palatal consonants, as represented by j, q, and x in Pinyin, are always followed by a medial vowel, one of the ones in the group of three vowels at the top of the left side of the chart in the lower part of the illustration above.
The Cangjie, Chang Jei, or Chong Kit input system (as Ts'ang-hsieh is also transcribed into the Latin alphabet, through the intermediary of Chinese dialects other than Mandarin) as well as WuBi, and the DaYi input system, popular in Taiwan, and, to a lesser extent, the phonetic input systems as well, all have as their ancestor a mechanical Chinese typewriter invented long before the personal computer by Lin Yutang (U.S. patent 2,613,795).
I remember having read about this invention in an article about an adaptation of this typewriter that produced paper tape for computer input that appeared in the June, 1963 issue of Scientific American. The original Mingkwai typewriter by Lin Yutang had a keyboard which was composed of three rows of keys which contained 36 possible shapes for the upper left corner of a character, below which there were two rows of keys containing 28 possible shapes for the lower right corner of the same character; then, at the bottom, there were eight keys used to select one of the up to eight possible results that would result from the two selections. The later article illustrated the Sinowriter, designed jointly by IBM and the Mergenthaler Linotype company for the U.S. Air Force (U.S. patent 3,319,516). It placed the shapes for the upper right and lower left corners of the character together, one of each to a key, so as to fit them on the conventional keyboard of a Friden Flexowriter, and increased the number of shapes for the lower right corner to 30 from 28. A later development of this input device with further improvements was known either as the Modified Sinowriter or as the Chicoder, developed at the Itek Corporation.
Invariably requiring only two keystrokes before a menu of characters is presented constitutes impressive performance for this early input method. Unlike most later ones, it was considered to offer a serious possibility of entry of Chinese characters by persons who did not understand Chinese, as well. Incidentally, I suspect that in order to distribute the characters among the possible codes for the corner shapes, it would be necessary to omit any enclosing radical before taking the lower right shape.
One uses the keyboard to input some facts about the shape of the character desired, and then a series of candidate characters is presented, from which one can choose the desired character. In a simplified version of Cangjie bearing a stronger resemblance to this original system, one specifies the shape of the beginning and end of the character, and then goes immediately to picking that character from what is usually a fairly long list. This system is called the Simplex system, and was originally developed by a Taiwanese company, Mitac, which also purchased rights from Lin Yutang to his invention. Originally, Lin Yutang's attempt to develop a Chinese typewriter had been a financial disaster for him, as a market for it failed to materialize.
The Simplex system apparently is also known as the Quick input method, and while it retains the principle of indicating the upper left and lower right portions of the character, instead of using 36 possible shapes for the upper left, and 28 possible shapes for the lower right, it uses the 24 symbols of the Cangjie keyboard for both parts.
Another aspect of the Mingkwai typewriter in which it differs from modern input systems, and apparently a little-known fact about that typewriter, is that while the sequence upper left, lower right, and then a choice from 1 to 8 selected one of 7,000 characters, the character repertoire of the machine was increased beyond this by allowing compound characters of the most common type, with the radical as the left half, and the phonetic on the right half, to be indicated by specifying the two halves separately.
A left half would be indicated by pressing a key for the upper left corner shape, followed by proceeding directly to making a choice of a left half with one of the selection keys from 1 to 8. Only 78 common left-half components were provided. The number of right-hand components, however, was about 1,300, and thus the right-hand component would also be indicated, like a complete character, by an upper left corner, a lower right corner, and a selection. These symbols, in addition to the 7,000 characters provided directly, were included in the 8,352 character positions the typewriter provided.
This means that the typewriter could produce not only 7,000 characters directly, but about 100,000 additional characters in this way; of course, only a fraction of those additional possibilities would actually make sense in Chinese, but it still significantly increased its power and flexibility, making it perhaps the only fully mechanical typewriter able to do justice to the Chinese written language.
The patent also mentions that 2/5 of the character cell was allocated to the left-half part as the best compromise; many characters with left and right parts normally have them equal in size, but others have the left part much narrower, and so this step was taken to allow more of the characters decomposable into a left and right part to be handled by the typewriter. (While this typewriter was already complicated enough, so much so that it never actually reached production, only a prototype being made, of course it would be theoretically possible to instead have two copies of the right parts, so that 1/2 or 1/3, say, could both be used, while still having an all-mechanical design. And then characters that instead have a top and bottom part, and the various types of enclosures, would suggest themselves as well, but such complexity was rightly eschewed.)
Also, the scheme used for accessing characters with this typewriter was used as the basis for the indexing of characters in a Chinese dictionary which Lin Yutang later prepared.
Lin Yutang was left in serious financial straits by investing in developing the prototype of the MingKwai Chinese typewriter. As a result, he sold the invention, and the physical prototype, to the Mergenthaler Linotype corporation. They, however, also did not produce typewriters on that model, although, as noted above, they did make some use of its principles.
The prototype itself was later believed to have been lost for many years; in early 2024, the granddaughter of a machinist working at Linotype, and her husband, discovered it in his basement after he had passed away, and, after they learned what it was, presented it to Stanford University.
In addition to compound characters with the radical on the left, Chinese characters can also have the radical above the phonetic, or enclosing the phonetic. In the case of an enclosure, since enclosures do not necessarily surround the phonetic on all four sides, it would not be practical to specify this type of character in two parts on a device which prints characters with physical type slugs. But a system which went one step further than the MingKwai typewriter by also allowing characters with the radical on top to be specified in two parts is possible.
This was, in fact, done at one time in France, to create a font of metal type for Chinese more quickly and easily than by cutting punches for every character individually. The typeface is shown in Spécimen de Caractères Chinois Gravés sur Acier et Fondus en Types Mobiles by Marcellin Legrand, who cut the punches for it.
While the MingKwai typewriter provided 78 common left-side components, this font provided 106 left-side components as well as 53 top-side components.
There are several other shape-based input systems, such as one based on the Four-Corner method of organizing Chinese dictionaries, the Array30 system, Boshiami, and Wubizixing (which is designed for the Simplified Chinese characters used on the Chinese mainland) and some that just use the number keys to specify a character one stroke at a time.
One can also specify a Chinese character, especially if one is a native speaker of Chinese, by typing in its phonetic value; this can be done using the letters of the Latin alphabet using a transcription system such as Pinyin, or by using the traditional symbols of the National Alphabet. The phonetic value can be combined with the tone, or the radical. And the radical can be selected by shape or by meaning: that is, the radical, instead of the whole character, could be specified by some shape system, or radicals with related meanings could be grouped together and associated with a single typewriter key.
The DaYi and Boshiami systems of input are commercial products, although limited versions of both systems have been made available for use without charge.
In addition to the systems based on Lin Yutang's original Mingkwai typewriter which were researched by the U. S. Air Force, other attempts were made to devise shape-based input systems for Chinese characters that could even be used by people who did not understand Chinese. In 1983, RLIN, a part of RLG, devised a bibliographic entry terminal for librarians that used a special keyboard containing 246 character components. In 1986, the OCLC CJK 350 terminal was made available for initial testing; it was also for library use, being a modified version of the OCLC terminal for entry of MARC library catalog records. It used a conventional typewriter keyboard, but with an extra row of keys at the top.
Most proposals for using a phonetic writing system to replace characters for the Chinese language focus on using either the Roman alphabet or the "National Alphabet" (bopomofo) to represent the sounds of Chinese words, with the possible use of an indication of tone by accent marks as well. One system of transcribing Chinese speech, the Yale system, spells vowels differently to indicate the different tones of a syllable; this system has a reputation of being awkwards for native speakers of Chinese.
The reason that an indication of tone can be omitted when Chinese is written phonetically is that most Chinese words are, contrary to popular belief in some non-Chinese-speaking areas, two syllables long. Often, however, when Chinese is written in the traditional, or Wen-Yan, manner, only the first syllable is represented by a character.
Since Chinese speakers can understand each other in conversation without having to occasionally resort to writing the character representation of the word they are trying to convey, obviously linguists are correct that the Chinese language is amenable to the same sort of phonetic writing system as is used by other languages. The Hui dialect, in particular, was once written by means of a writing system based on that of Arabic, called Xiao'erjing, and some of the users of that writing system now live in the Commonwealth of Independent States; the form of the Hui dialect they use, with unique loan-words from Arabic and Russian, is known as the Dungan language, and is written using a Cyrillic alphabet.
Despite the living proof that Romanization is possible for Chinese, I still believe that its advocates are forgetting an important factor.
The fact that the Yale system is uncomfortable for native Chinese speakers is an indication that they do not consciously think about tone when they are speaking. But, of course, they do think consciously about meaning, that is, the meaning of the words they are saying, when they speak. Thus, although there is awkwardness involved in adding space for over a hundred radicals, instead of accent marks for four or six tones, to a keyboard, if amiguity were a serious matter, the former alternative might be more congenial. But hasn't it just been noted that, since Chinese words are really disyllabic in most cases, ambiguity is not a serious matter?
Prior to the introduction of simplified characters in the People's Republic of China, and the baihua writing style to go with them, in which writing follows (Mandarin-language) speech closely, written Chinese in the traditional, or Wen-Yan, form was used by all Chinese, including those who spoke Cantonese or other non-Mandarin dialects. China has an immense corpus of written literature in traditional form. If the Chinese people were to abandon the Chinese character, so that new generations did not spend the time learning to read and write with characters, all that literature would become inaccessible to them, unless it was translated into the Chinese dialect which they spoke. Translation would be required in the case of Mandarin, not just the other dialects (otherwise, baihua and wenyan would be identical).
On the other hand, if Chinese characters were abandoned, but replaced by a system in which the phonetic representation of a word were preceded with one of a few dozen radicals preserved from the character system of writing to indicate its general class of meaning, then such a writing system could also serve for the transcription of traditional character-based texts, because it would have enough capacity for the resolution of ambiguity to make such a transcription comprehensible, without the need to fully render the text as a speaker of one's own dialect would read it aloud.
There is a way, therefore, to express the Chinese language in writing, with a restricted symbol set suitable to 8-bit computer representation, and convenient use of a typewriter keyboard, and, most importantly, to allowing students to learn how to write well in Chinese without spending an inordinate amount of time and effort in their studies, which not only serves to transcribe the spoken Chinese language, but which also serves to transcribe traditional character texts. That is the argument for retaining radicals, along with a phonetic method of writing, in Chinese writing reform.
Even retaining radicals in this way, however, does not create a sufficient amount of distinction among characters with the same phonetic value to be perfectly satisfactory for the direct transcription of texts in classical style. One example I have seen is that the characters for "elm" and "dead tree" both have, of course, the tree radical, and also have the same phonetic value. Thus, the need to annotate characters in classical texts with information about the second syllable of the word they are from is not fully eliminated by moving up from tones to radicals. Far be it from me to afflict the Chinese language with Dutch elm disease.
This idea is not, however, original with me.
U. S. Patent 2,471,807, issued to one Yen Ti-Sheng (or Tisheng Yen, as given in the patent), is for a conventional typewriter slightly modified to print characters in this form. As it did not produce traditional Chinese characters, it might be argued that it was not a true Chinese typewriter, but as it did provide a rapid means of recording text and utterances in the language, it was still potentially a useful device, just as the instruments made by Stenotype have their use for English, by permitting faster typing of what may be transcribed later. The parallel is not exact, as this device would not have been fast enough for dictation, but it might increase the speed of Chinese typing to that of conventional typing.
The following is a diagram of the layout of that keyboard:
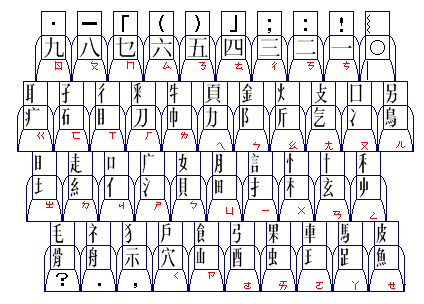
It had 41 keys in four rows; each key bears three characters.
For 37 of the keys, one of those characters belongs to the National Alphabet, leaving four exceptions.
For 31 of the keys, the other two positions contain two half-width Chinese characters which serve as radicals. Of these keys, all but three have a character belonging to the National Alphabet in the third position; the other three have punctuation marks there, accounting for three of the four exceptions noted above.
Nine other keys contain double-width Chinese numerals in the first of the two positions used for radicals, and punctuation in the other one of those positions. A character from the National Alphabet appears in the third position for all of these keys.
The 41st key, which has the underscore in the National Alphabet position, is the key for the full-width circle used as a period in Chinese, and thus it is the fourth of the exceptions to the first rule.
The characters of the National Alphabet combine vertically in the second half of a square character area, following the radical, and replacing the normal Chinese phonetic part of a character.
From the classical set of 214 radicals, the ones used in this design were:
128 39 60 165 93 181 167 86 66 31 (1)
104 112 109 18 50 19 170 69 84 15 196
72 156 30 53 38 74 149 61 24 115
32 120 9 85 154 102 64 75 96 45
82 113 94 63 184 57 (2) 159 187 107
188 137 113 116 46 164 142 95 157 195
In addition, two symbols, denoted by (1) and (2), were present which were not among the KangXi (K'ang Hsi) radicals. (1) suggests an alternate form of 39, and (2) combines 102 and 75, field and tree. Also, it is very likely that radical 163 serves also for radical 170 in particular; in general, of course, many of these radicals will subsume others with related meanings.
The diagram above was created based on a source that appears to have reversed the order of radicals 95 and 96.
While Chinese script reform of this magnitude - less than full Romanization, but greater than just simplifying the characters - is unlikely in the near future, this scheme also has something to commend it as an input method.
On the subject of Chinese typewriters, a year before Lin Yutang's Chinese typewriter was publicized in 1947, IBM exhibited its first prototype of a Chinese typewriter; production was not pursued, and the device required one to memorize the numeric codes of all the characters one wished to type, and thus it addressed only the output problem (it is described in U.S. patent 2,458,339).
Initially, when I heard of this typewriter, my conclusion was that it was obviously useless. Later, when I learned about the story behind it, that it was invented by outside inventors, who then went to IBM to help them market it, and it was demonstrated by a woman who did manage to memorize its entire numeric codebook, it dawned on me that such deceptive marketing was not needed, and the typewriter could actually be useful, if used properly.
While the typewriter itself would be expensive, extra copies of the codebook giving the numeric codes of the characters it could type would be much cheaper to produce.
So a large office that made extensive use of the Chinese language could distribute a copy of the codebook to every secretary. The secretaries could transcribe correspondence into numeric form by hand, and then the texts, already in numeric form, could be sent to the one typist with this kind of Chinese typewriter. Since that typist would only have to type the numbers as given, rather than looking up charcters, the typewriter would be used efficiently, producing typed pages at a rate comparable to that of a conventional typewriter.
Of course, that typist would still need a copy of the codebook to correct occasional errors, but it seemed to me this would be a way to make such a device productive and economically reasonable to use.
The old-fashioned style of Chinese typewriter, in which types are located in a tray, and picked up from that tray to be used in typing by a single moving typewriter key, derives from a Japanese typewriter invented by Sugimoto Kyota and first produced by the Nippon Typewriter Company in 1917 (although one patent dates from 1929, another is from 1915). In the 1920s, the Commercial Press of Shanghai made the first such typewriters for Chinese, the design having been adapted to that language by Chou Hou-Kun (who had previously invented a Chinese typewriter which worked by selecting the character by rotating a drum, and moving a sliding pointer along that drum; for this invention, he is generally credited as the inventor of the first Chinese typewriter), and many years later, at least some of the Japanese companies, such as Nippon Type, which made such typewriters for Japanese also made versions for the Chinese language, and as well, Chinese production of such typewriters was resumed; thus, the Shanghai Typewriter Factory (or Shuangge) produced the Double Pigeon typewriter as late as 1985.
One example of the character layout for a Japanese typewriter of this kind involves 36 rows and 60 columns of characters. There is a Japanese standard for computer input devices of this type, JIS X 6003. One of the Chinese typewriters made by the Commercial Press is described as having 38 rows and 67 columns of characters; typically, machines of this size were often provided with a second tray of less common characters.
Interestingly enough, the first animated film produced in China was an advertising short for the Chinese typewriter from Commercial Press.
Keyboards of an intermediate size, between that of a conventional typewriter keyboard, and one that accomodates the entire available repertoire of characters, have also been proposed for use with the Chinese language. A Chinese-language computer terminal developed by the company TransTech in Taiwan, the Sinoterm, ended up being used as the basis for a terminal used to make library catalog entries for Chinese-language books, the RLIN CJK system.
The keyboard included a conventional typewriter keyboard layout, a Katakana keyboard layout, and a Hangul keyboard layout within it, so that it would be useful for typing text in any of the languages that used Chinese characters, as well as allowing it to be accompanied by text in European languages using the Latin alphabet.
Each key had two Chinese characters or parts of Chinese characters on it; the keyboard worked according to the same principle as Lin Yutang's Minghwai typewriter and the Chicoder keyboard based on it: first, one pressed the key which had on it in the first position the character component corresponding to the upper left corner of the character, and then secondly one pressed the key which had on it in the second position the character component corresponding to the lower right corner of the character. Because the keyboard was larger, there would typically be fewer different characters to choose from afterwards.
IBM once marketed a Chinese typewriter that had a very simple keyboard, containing just the ten digits from 0 to 9. Four-digit code numbers represented 5,400 different characters available with the device.
This page gives the story of how Lois Lew, a woman who had recently emigrated to the United States from China, and who was in financial straits at the time, memorized the code for the device in order to give demonstrations of it.Despite these demonstrations, the device was not a commercial success.
On reading the article, of course I viewed it as dishonest to attempt, through staged demonstrations, to convince prospective buyers of the typewriter that the need to memorize a large code for characters in order to effectively use the device was no problem, when, of course, it would be a very serious problem in practice. But the typewriter failed, presumably because those viewing the demonstrations weren't persuaded by them that their intuition about something so obvious could be wrong.
But it also occurred to me that this was tragic, as if instead those behind the typewriter had been open about the issue, there was a solution to it they could have offered which would have made it clear that this was a typewriter worth purchasing.
Instead of depending on a typist who memorized the codes for at least the common characters, if one had one typewriter, but several copies of the code book, then such a typewriter could be used effectively, rather than being slowed down by the need to look up the characters for it one by one, by this scheme:
Whoever, in a business, wished to have a letter typed on this typewriter would first use the codebook, or have his own secretary use the codebook, to convert the characters to numbers; and then, the sheet of numbers would be sent to the typist operating the Chinese typewriter.
She, too, would have a copy of the code book, but she would only use it for correcting errors.
In this way, this expensive typewriter, operated by one specialist, could produced typed copy on a continuous basis, because the operation of looking up characters in the code book would take place separately from typing; many people could be composing copy for the typewriter at the same time.
The moral is: the way to address a problem is to present a solution, not to pretend it is not a problem.
An alternate means of reducing ambiguity in a phonetic script in the indication of characters, instead of adding radicals, would be to include 'silent letters' or different letters that make the same sound, from the viewpoint of any one dialect, so as to include the needed information in the phonetic spelling of a character to deduce its pronounciation in any dialect. (Of course, I suspect there would be a few non-cognate cases where this would fail.) The "General Chinese" of Y. R. Chao is a system of this type, and an earlier system of this nature was the "Romanisation Interdialectique"; reconstructions of Ancient Chinese phonology might also serve.
This would be universal across dialects, as opposed to the system discussed above, where radicals would be followed by a phonetic representation of the character in the reader's own dialect, but it would leave the reader with a vast number of arbitrary spellings that would need to be memorized. Of course, once a character text is digitized, it could be printed out in characters or in General Chinese, and speakers of any dialect could easily learn which details to ignore when reading texts in it. Learning to write in General Chinese, however, is comparible in difficulty to learning a new spoken language. It may be that even this is easier than learning to write characters, but while it is of interest, and useful for certain purposes, it seems to me that it would not provide the benefits desired from writing reform if used for that purpose.
But if computers did the work of translating to, say, a radical plus General Chinese script for publication, from an input system of radical plus a phonetization of one's own dialect, then, provided one writes in Classical style and not according to the vocabulary and grammar of one's own dialect, one might be as well understood throughout China as if one used traditional characters. Excepting that the system would be easier to learn to read. Adopting as a standard, however, a writing system that requires either computer mediation or the equivalent of learning a second spoken language, does not seem reasonable. But it would be possible to easily create mass reading literacy in such a system, and it would facilitate reaching all the dialect groups through publication in it without having to favor one dialect over another.
As noted above, for general use by native speakers of Chinese, a phonetic input method is much superior to any shape-based input method. However, the data files that describe input methods for cxterm, for example, which have the .cit extension in their compiled form, but which have the "c" replaced by a "t" for their raw, human-readable form, standing for "compiled input table" and "text input table" respectively, show that even with a number indicating tone appended to the Pinyin Romanization of a character, there are still many alternatives that have to be chosen from on the computer screen. One way to improve this is by using an "intelligent" input method based on two-syllable words. Beginning with one of a limited set of radicals similar to this set of 62 radicals (another possibility would be the 97 radicals proposed by Atkin Y. Goo and Gee-In Goo to disambiguate the shape-based four-corner code) giving a category of meanings to which the word belongs, instead of ending with just one of four tones (for Mandarin; six for Cantonese) would be another way to cut the ambiguity down further.
The current traditional system of 214 radicals is usually associated with the K'ang-Hsi Tzu-Tien (Kangxi Zidian), which dates from 1716, although that system was in prior use. The Shuo-Wen Chieh-Tzu (Shuowen Jiezi), an earlier (from 121 A.D.: it may be noted that one of its most highly praised annotated editions, by Tuan Yü-Ts'ai (Duan Yucai), dates from 1815) dictionary which focused on the origin and development of Chinese characters, listed 540 different radicals. (The Unicode site contains a PDF of a fascinating essay by Robert Cook on this work, and the issues surmounted in converting it to a digital form.) In both of these systems, the radical was the actual portion of a character which suggested meaning, as opposed, in the case of characters in the class of phonetic compounds, the part which indicated the character's sound. The later KangXi system reduced this chiefly by lumping together characters which were under little-used radicals.
Often, the radical of a character is the part on the left, or the top, or the enclosure, but this isn't always true: classifying characters based on the character component on the top left, whatever its function, would make an unknown character easier to find for someone unfamiliar with Chinese, and current dictionaries from mainland China using systems with fewer radicals (such as 189 radicals) approach this. The system introduced in Japanese Names and How to Read Them, most familiar from the more recent book The Eater's Guide to Chinese Characters by James D. McCawley, might also be considered here, as perhaps the most accessible indexing system for Chinese characters.
Since I have brought up the subject of Chinese dictionaries here, another digressive note may be in order.
An early basic Chinese-English dictionary, intended for the use of students, included definitions for 5,000 characters, "The Five Thousand Dictionary" by Courtenay H. Fenn. One unique feature was that characters were given one-letter codes indicating the 500 most common characters, the next most common 500 characters, and so on.
There are many Chinese-English dictionaries that cover fewer than 5,000 characters; thus, one example, quite suitable for ordinary purposes, covers "over 3,800 characters"; this was a book of 354 pages. Normally, a Chinese-English dictionary also includes definitions for sequences of multiple characters as well, of course. A typical word in spoken Chinese may be two syllables long, but will often be written by one character instead of two in traditional Wen Yan style as opposed to Baihua, which is the style that more closely follows speech. While the movement to use Baihua for all writing purposes dates back to the revolutionary movement of Sun Yat-Sen that overthrew the Emperor in 1911, informal texts had been published in print in such a form much earlier, with efforts to spread Buddhism in China providing the initial impetus to establish this alternative style of writing, and novels and other popular literature then making use of the new accessible linguistic form.
English-speaking advanced students of Chinese, who wish to acquire the ability to read and translate older classical Chinese manuscripts, have had limited choices when it comes to dictionaries which include a larger number of characters so that rarely-used and obsolete characters can be found.
One larger Chinese-English dictionary often resorted to by such students, with some disapproval from their professors, is Mathews' Chinese-English Dictionary. (One particular fault it has is that some of its definitions are overly specific.) Despite its use in this connection, it covers 7,773 characters. This seemed odd to me, since the Chinese Telegraph Code assigns four-digit numbers to 7,927 characters, and, while I would not be surprised by the telegraph code being comprehensive, I would expect it not to include obscure characters, whereas a dictionary useful in reading even ancient documents seemingly would have to.
There are a few larger Chinese-English dictionaries; the very old Williams' Syllabic Dictionary covers 12,527 characters; it is distinctive in that it includes extensive information on the pronounciation of characters in several other dialects in addition to Mandarin. This was also true of the more accurate Chinese-English Dictionary of H. A. Giles, which covered 13,848 characters.
There are reprints of the original K'ang-Hsi dictionary available, which is one inexpensive recourse that covers 47,035 characters; with, of course, the definitions still being in Chinese.
Traditionally, however, the recommended resource for looking up obscure characters has been a monument of Japanese scholarship, the Dai Kan-Wa Jiten of Morohashi. This originally had 49,964 entries for different characters. This, of course, required the student of Chinese to learn yet another language! Recently, however, it has tended to be superseded by the Hanyu Da Cidian and the Hanyu Da Zidian (the first being a 13-volume dictionary covering over 23,000 characters with many phrases, examples, and citations, the second being an 8-volume dictionary concentrating on single characters, covering 54,678 of them). There is also the Chung-wen Ta Tz'u-Tien (Zhongwen Da Cidian) with 49,905 characters from Taiwan, which is somewhat controversial. As well, there is a large dictionary from Korea (titled simply Han-Han Dae Sajeon, which is apparently a generic term) that covers 53,667 characters which recently came out, published by Dankook University.
Dictionaries that only attempt to describe individual characters, rather than giving the definitions of words and phrases that use them, can include a larger number of characters. The Zhonghua Zihai, from mainland China in 1994, lists 85,500 characters; it is divided into two parts, the first including 50,000 characters that have appeared in previous dictionaries. In 2004, the Dictionary of Chinese Character Variants, from Taiwan, included 106,230 characters. Since a new character is added to Chinese when a new element is discovered, to serve as its symbols, the set of Chinese characters is open-ended, so one can't attempt to use those two immense sources to set a fixed canon of, say, 140,000 characters for Chinese.
The recent seven volume Grand Ricci Chinese-French dictionary covers 13,500 characters, and this is enough for it to be a celebrated achievement of scholarship. Of course, there is more to the merit of a Chinese dictionary than the number of characters it includes; the amount of information in each entry also matters.
I have recently discovered, however, that there is hope for lazy people who would like to look up a rare and obscure Chinese character and at once find an English-language definition for it. This dictionary is quite old; Morrison's dictionary fails to distinguish between p' and p (or p and b) and between k' and k (or k and g), for example, in the pronounciations it gives of the characters, while this dictionary sometimes attempts to do so, but does not do so consistently in a correct fashion. This dictionary, by W. H. Medhurst, in two volumes, at least claims to cover every one of the characters found in the dictionary of K'ang-Hsi. And it's even on Google Books! Actually, character entries in the main body of the dictionary are of a much smaller and conventional number: but what it does have is a list of "Obsolete, Contracted, and Vulgar Characters" and the correct characters of which they are duplicates at the end of each volume.
Also, a large Chinese dictionary was published in 1915, the Chung-hua Ta Tzu Tien (Zhonghua Da Zidian), which while based largely on the K'ang-Hsi dictionary, included much additional material and newer characters. It was originally published in four volumes, and there is a recent two-volume reprint. The four-volume edition is also available online at the Internet Archive, the University of Toronto having digitized their copy.
Since the Chinese have managed with characters for thousands of years, of course, the question might be asked why there is a need for reform of Chinese writing. The obvious answer is that it takes more effort to learn Chinese characters than it does to learn an alphabetic script, and so Romanization would reduce illiteracy. Some writers have recently identified a more specific problem. While literacy in the character script can be achieved, in the sense of being able to read existing texts, with a sufficiently reasonable level of effort that the goal of universal literacy in this sense has not been out of reach for China despite not being wealthy like North America, Europe, or Japan, the ability to write freely in characters is significantly more difficult to learn, and universal literacy in this sense may therefore still not be attained. As noted, the vast majority of Chinese characters are formed from a radical (category of meaning) and a phonetic (sound). In handwriting, it is entirely possible to write a character with a different phonetic part than the standard one. Since the official version of a character is the one which can be typeset or displayed on a computer screen, Chinese speakers are, in effect, in the situation we would be in if typewriters refused to allow an incorrectly-spelled word to be typed, without offering any assistance in finding the correct spelling.
Thus, Chinese characters are blamed for inhibiting creativity and encouraging authoritarianism. There is some truth to this charge, but I suspect that the misfortunes of Chinese history owe more to China's geography than to its writing system. And it may be noted that Chinese characters can be shown to have an important benefit to at least those Chinese people who live as a minority in countries outside China. Members of ethnic minority groups in a given country are often economically disadvantaged. One thing that often worsens this is that, as they are alienated from the majority culture, the tendency of youth to show disinterest in schoolwork can be exacerbated. It is well known that the Jewish people are an example of a minority group which avoids this problem; and the fact that the bar mitzvah, which serves as a manhood ritual for them, depends on Hebrew-language literacy may contribute to this. The relationship between Confucianism and the Chinese civil-service examinations has led to a tradition lending great importance to character literacy for the Chinese people, and the studiousness and academic achievements of Chinese young people, as well as those of related Asian groups, regardless of the country in which they live, are well known. Thus, I claim that for both the Jewish people and the Chinese, as well as for Asian peoples who share some of the Chinese cultural heritage, schoolwork is an expression of their own culture, not an alien one, and therefore to study is, to some extent, for them to perform an emotionally natural act of defiance, instead of an emotionally painful act of surrender, when their group is a minority.
And, it might also be noted that the emotional arguments for retaining characters in script, as used either in China or in Japan, are much the same as are used in the English-speaking countries against the reform of our complicated system of spelling, which is much further from a phonetic one than that of Russia, or Italy, or Finland, or, indeed, that of nearly any other country with an alphabetic script. We are used to our own system of spelling, so it seems more dignified, and its correct use distinguishes people who have undergone formal education from those who have not. Characters appear to impose a burden even heavier than that imposed by English spelling, but of the people who write using an alphabet, the speakers of English are the most poorly placed to criticize those who do use characters; we have not put our own house in order in the same respect, and with far less effort required to do so.
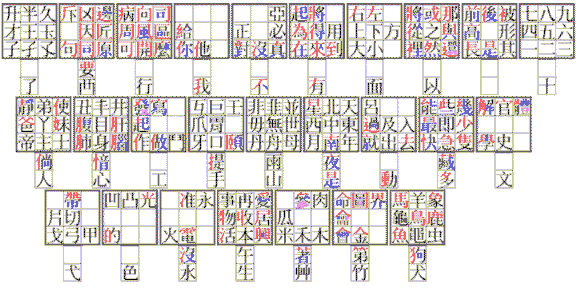
The research that I engaged in to produce the images of keyboards used for popular Chinese-language input methods ended up piquing my curiosity about the subject of the Chinese writing system and input methods for it; here is an image of the first attempt at a keyboard arrangement I have been puttering around with for a few days at one time:
and the beginning of a revised arrangement:
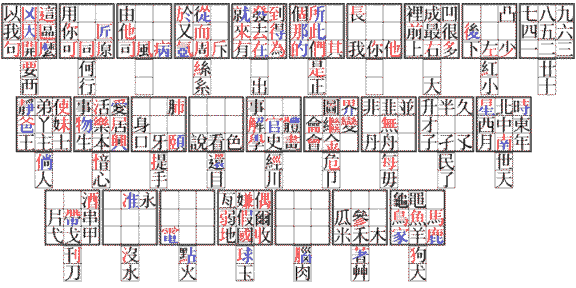
The intent of this keyboard arrangement is to permit one to specify a character in terms of the component parts of which it is composed; thus, it is intended to be amenable to the use of people who do not know the Chinese language, but only a few basic facts about characters.
Some keys bear individual character component parts; other characters have common Chinese characters on them; in that case, the characters are divided into their component parts by color (although, for obvious reasons, this can be done on a wall chart, but not really on the keyboard itself in a useful fashion).
Each key is represented by a 3x3 square with two squares below it: these locations are referenced as follows:
--------
|7a|8a|9a|
|--------|
|4a|5a|6a|
|--------|
|1a|2a|3a|
--------
|A |
|--|
|a |
--
and, where the key has a character on it that is divided into several component parts, prefixing the code by another digit indicates the component part.
The color code for the component parts on the keyboard is the following:
1: red 2: black 3: blue 4: green 5: purple 6: brown
In addition, when two components of a character share a stroke (as is true in two locations on this keyboard) that stroke is shown in grey.
The characters coded by "h", "i", and "k" are in error on this keyboard as shown at present; the "h" character is duplicated elsewhere, and these keys have multiple components, which are inaccessible under the scheme noted above.
Even the characters indicated by capital letters could not have multiple components to permit a simplification I had originally intended: let 7A specify the entire character in the seventh square on the face of the A key, and let 7a, rather than 17a, specify the first component of the character in the seventh square on the face of the A key. The characters are chosen so that, in many cases, the primary purpose of the position on the key is to produce the first component of the character, not the character itself or its other components.
However, as a mnemonic, I had placed examples of the modified forms of radicals when they are used in some combined positions in a character in the capital position on the key; so I need both the simplification and the thing it prohibits. Below, as a method of permitting an extension to the keyboard, I note a way around this dilemma: using the shifts of the digit keys, rather than the digits, to select character components.
Thus, on the earlier version of the keyboard as illustrated, one would type the name of China with the sequence:
5h 15w8i
Since the contents of the "box" radical in the word for "country" are a common word in their own right, and consist of more than one component, that word, rather than the word for "country", is placed on the keyboard, since attempting to use its components from inside that word would require it to be spelled out, one component at a time. However, as first done in the character for "to revolt, overturn" with a group composed of thread-speech-thread, used in a number of complicated characters, such as "bent, crooked" and "spherical", I realized that I could use control over colors to indicate groups of components.
The difficulty of this kind of keyboard is that because it is intended to provide a definite set of character components, instead of requiring the typist to more vaguely specify the general shape of the character, that extensions to the keyboard, not merely to the tables of the input system, would be required to adapt the system from supporting the characters in common use to supporting a much wider set of characters to include those found in old writings.
To permit this, one could use the characters !, @, #, $, %, and ^ instead of the digits from 1 to 6 to select character components; then, one could select an extended character by typing two digits before the letter.
Another difficulty is that, by including the most common characters, and including characters with every possible component, some components are duplicated; to allow the user to use any copy of a component, however, lengthens the input table: the standard format for describing input methods to programs such as cxterm does not provide for specifying the syntax of a tokenizing prepass. But I avoided that, with a later version of the first keyboard arrangement than that shown, by switching from coloring every component of every character (to illustrate the way in which characters are to be broken down) to coloring only those components available for entry; in addition to eliminating duplicates, this let me allow groups of components to be specified.
Based on how cxterm works, I decided that while some input methods do allow the digit keys to serve as both input keys and selection keys, since it wasn't clear from the example text input table files I saw how this was managed, I decided to use the keys :; "' {[ }] _- and += as the first six selection keys when unshifted, and the second six selection keys when shifted. !(letter or digit) enters single-width letters literally, and &(letter or digit) enters double-width letters literally; / replaces - as the association key.
With the Windows IME, < and > are replaced by - and +, but perhaps the Windows IME also provides a way to make using the digit keys as the selection keys practical as well.
Incidentally, the font used to produce the diagram is the 40x40 CNS 11643-1992 font, courtesy of, and copyright by, the Central Bureau of Standards of the Republic of China's Ministry of Economy.
It may be noted that in the People's Republic of China, as personal computers began to become available, an input method based on the same principle which I was using as the basis of the system sketched above, building characters from their components, was the first one offered. It was called Renzhima, but because it was a very slow input method, it was unpopular and failed to catch on. The paper by John DeFrancis from which I heard of this system noted, however, that the most popular input system is one based on Pinyin - and I noted above that a phonetic input system is the most natural for people who can speak Chinese - and also that the other popular system, Wubizixing, takes a long time to learn. Thus, I think that a compound system, which has three layers, the first placing the most common characters on the keys to be typed with a single keystroke, the second being a phonetic system, and the third a system based on the shapes of the characters, could properly use a system like Renzhima, slow and cumbersome for use alone to type an entire text, but with a short learning curve, rather than one of the faster shape-based systems, such as Cangjie, Wubizixing, or DaYi. The reason I make this suggestion should be obvious, even if to some it might appear bizarre: if the shape-based system is to be used only rarely, for a very few characters on an occasional basis, then a short learning curve is much more important than typing efficiency.
That which is a failure when used for the wrong purpose can still be extremely valuable when used where its strengths are needed.
Thinking of this further, the system I envisage might allocate codes this way:
Common characters:
a small letter
A capital letter
7E digit from 1-9 followed by a capital letter
Radicals:
7e digit from 1-9 followed by a small letter with
the code for the radical then followed by an
indication of the phonetic value of the character
Characters constructed from components:
0 the digit zero is used as a prefix for constructing characters
whose pronounciation or meaning is not known
it is followed by a series of two-letter codes representing
character components
having the prefix property, and allowing codes to be unambiguously terminated by a digit choosing one of several alternatives.
The phonetic value of the character could be expressed in Pinyin or in the Zhuyin Fuhao, or in a transliteration of Cantonese such as Jyutping, or a transliteration of Southern Min such as Phofsit Daibuun. For Mandarin, at least, a scheme such as Double Pinyin or ZiRanMa could also be used, where only two keystrokes indicate the pronounciation of a character, the first giving the initial consonant, the second giving both the medial and final vowels.
Someone using this system would have to have charts next to the keyboard. Although the chart of character components wouldn't normally be used in ordinary typing by someone who understands Chinese, two smaller charts, of the common characters and the radicals would still be needed.
Since the radicals are followed by the pronounciation of the character, they are for use by people who do understand Chinese; thus, the actual radical, representing the meaning of the character, is used, even if it is on the bottom or the right of the character instead of the top or the left. An effort would be made to provide all the characters with radicals that are difficult for other reasons with codes for direct entry. This could be done by adding long character codes of the form 78e, for example, so as to avoid using up positions required for more common characters.
To avoid the need for a multiplicity of keyboard charts, however, instead one might simply place nine of the most common characters on each key, with a character component and a radical associated with most of them, similar to the scheme used (for character components only) with the keyboards shown above. The first key pressed would both choose one of nine positions on the next key, and indicate the type of code, as follows:
wer sdf common character xcv uio jkl radical m,. 123 456 character component 789
with successive character components not being prefixed by a digit, but instead either with a wer/sdf/xcv or a uio/jkl/m,. keystroke, depending on which one is under the hand opposite the one used for the key prefixed, so that the use of the right and left hands alternates more often for better typing speed.
Further thought is leading me to a system similar to the preceding idea, but borrowing a little from this as well.
The character codes which preceded Unicode which were used to encode Chinese characters, not discussed on this page, are discussed on this page within the cryptography section of my web site (the page is about UTF-8).
Copyright (c) 2003, 2005, 2007, 2022 John J. G. Savard