As previously noted, there is the 16-bit Unicode character set, and the larger 31-bit ISO 10646 character set which includes it.
For transmitting such characters, an elegant (if somewhat inefficient) scheme which represents all 7-bit ASCII characters in a single byte known as UTF-8 is the current standard.
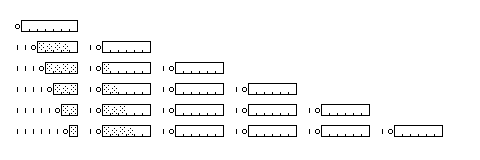
In UTF-8, characters, considered to have 31-bit values, are encoded as follows:
Character: Representation: Character Range: 0000000 00000000 00000000 0abcdefg : 0abcdefg 00 - 7F 0000000 00000000 00000ABC Defghijk : 110ABCDe 10fghijk 080 - 7FF 0000000 00000000 ABCDEfgh ijklmnop : 1110ABCD 10Efghij 10klmnop 0800 - FFFF 0000000 000ABCDE fghijklm nopqrstu : 11110ABC 10DEfghi 10jklmno 10pqrstu 010000 - 1FFFFF 00000AB CDEfghij klmnopqr stuvwxyz : 111110AB 10CDEfgh 10ijklmn 10opqrst 10uvwxyz 0200000 - 3FFFFFF ABCDEfg hijklmno pqrstuvw xyzabcde : 1111110A 10BCDEfg 10hijklm 10nopqrs 10tuvwxy 10zabcde 04000000 - 7FFFFFFF
The capital letters denote bits that must not all be zero. These bits are showed by areas peppered with dots in the diagram below:
This coding has many desirable properties, one of which is that is unambiguous which transmitted bytes begin a character, and which merely continue one. Also, there are no shifted states in the code. This coding also does not affect mechanical sort order of strings.
It was originally developed by Ken Thompson during the development of the Plan 9 operating system at AT&T. It was first drafted on the back of a restaurant placemat.
However, it allows only 2,048 characters to be encoded in two bytes; yet, many existing codes allow over 8,000 Chinese characters to have two-byte codes. Also, this means that every letter in a Greek or Hebrew language document will take up two bytes, and every symbol in a Thai-language document will take three bytes. Being able to shift into a character set appropriate to the language to be used would seem to be an important property for an efficient coding.
If one is prepared to surrender the desirable properties of this coding, there is sufficient room within it that an efficient coding could be created that is compatible with it.
One way this could be done is by adding these codes:
110ABCDe 01fghijk - character ABCDefghijk - shift into mode where 1pqrstuv means character ABCDpqrstuv 1110ABCD 10Efghij 01klmnop - character ABCDEfghijklmnop - shift into mode where 1pqrstuv means character ABCDEfghipqrstuv
and so on. Having the second-last byte, instead of the last byte, of the form 01xxxxxx would indicate shifting into a mode where two bytes of the form 1xxxxxxx xxxxxxxx indicate a character contained in the same 32,768 character expanse as the character whose code was thus modified, for example:
1110 ABCD 01Efghij 10klmnop - character ABCDEfghijklmnop - shift into mode where 1lmnopqr stuvwxyz means character Almnopqrstuvwxyz
Unfortunately, U+08000 is right in the middle of the CJK unified ideographs, limiting the usefulness of that mode, and so something more complicated is required.
Leaving any of these modes would require the use of a control character, perhaps SO (shift out).
And this would still leave room for an additional set of more efficient codes for characters:
10xxxxxx 0xxxxxxx 10xxxxxx 1xxxxxxx 0xxxxxxx 10xxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx
and so on.
These codes would only be available, of course, where one of the shifted modes above was not in use. The shifted modes affect all character codes where the first character begins with a 1; this keeps the codes of the form 0abcdefg always available, since they are needed to represent control characters.
However, from the standpoint of truly unbiased internationalization, it would seem desirable to change the way in which shifted modes work. As shown here, it is easy enough to set up a mode in which a Chinese-language text interspersed with English-language portions is represented by two bytes for each Chinese character and one byte for each English letter. But it isn't possible to achieve equal efficiency if one is instead dealing with a Chinese-language text combined with Greek or Russian quotations.
Replacing 10 with 01, where the first byte already specified the length of the code, was used to indicate that the character also caused a shift to its own region of the available characters. Since 00 and 11 are also available, one can define two additional shift regimes, which, unlike the original one, do not transform the interpretation of characters as comprehensively.
With 00, the modes would be of this type:
110ABCDe 00fghijk - character ABCDefghijk - shift into mode where 0pqrstuv means character ABCDpqrstuv if p and q are not both zero, and 000000rstuv otherwise 1110ABCD 10Efghij 00klmnop - character ABCDEfghijklmnop - shift into mode where 0pqrstuv means character ABCDEfghipqrstuv if p and q are not both zero, and 00000000000rstuv otherwise
with 00 in the last position, and with 00 in the second-last position, we would have instead cases such as:
11110ABC 10DEfghi 00jklmno 10pqrstu - character ABCDEfghijklmnopqrstu - shift into mode where 110RSTUv 00wxyzab means character ABCDEfghijRSTUvwxyzab
and in this case, multiple modes of this form could be active at one time, so that one can specify that characters of the form 0PQrstuv belong to the Greek or Russian character set (while characters of the form 000rstuv remain control characters) and that characters of the form
110ABCDe 10fghijk
belong to the Chinese character set, or at least a chosen group of 2,048 contiguous characters from it.
Naturally, if 00 replaces 10 in the third-from last character, it is the interpretation of characters of the form
1110ABCD 10Efghij 10klmnop
that is modified, and so on.
Thus, so far, we have the situation where 01 replacing 10 sets up a shifted mode in which a byte beginning with 1 begins a fixed-length code representing a character in a selected portion of the code table, and 00 replacing 10 sets up a shifted mode in which the normal interpretation of the bits indicating the type of a code are retained, but standard UTF-8 character sequences of a specific chosen length are now shifted to refer to a different part of the code table.
The obvious thing to do next is to have 11 replacing 10 set up a shifted mode affecting the more efficient multibyte coding indicated by a combination whose first byte is of the form 10xxxxxx. Since this group of codes involves two-character combinations with 13 bits of information, three-character combinations with 20 bits of information, and so on, this would begin with having 11 replacing 10 in the second-last character:
11110ABC 10DEfghi 11jklmno 10pqrstu - character ABCDEfghijklmnopqrstu - shift into mode where 10vwxyza 0bcdeFGH means character ABCDEfghvwxyzabcdFGH (note that FGH are capitals in order to be distinct symbols, not to indicate they cannot all be zero, as of course they can)
As with the codes involving 00 replacing 10, these codes don't affect the parsing of character sequences, only the final meaning attached to a character, and thus multiple shift modes of the 11 type and multiple shift modes of the 00 type may all be simultaneously in effect. On the other hand, only one shift mode of the 01 type can be in effect at a given time, and when such a shift mode is in effect, no other shift modes can apply either.
With 11 in the second-last byte, we are creating a shifted expanse of 8,192 characters instead of 2,048 characters; thus, when combining Chinese with Greek or Russian, it would make sense to use a 00 shift mode for Greek or Russian and a 11 shift mode for Chinese.
However, there is one problem when 00 replaces 10 in the last byte of a multibyte character sequence. The fact that characters of the form 000xxxxx are not affected, while necessary to ensure the control characters always remain available, creates a conflict between the operation of these shift codes and the structure of the UNICODE code table, which, after the first 256 characters, does not treat the first 32 characters of each group of 128 characters in a special way.
The simple shift mode with 01 replacing 10 does not have this problem, although it has its own limitations.
Since 11, in the codes defined so far, can replace 10 in the second-last byte and in earlier ones, but not in the last byte, there is a remedy available:
110ABCDe 11fghijk - character ABCDefghijk - shift into mode where 00qrstuv means character 00000qrstuv, and character 01qrstuv means character ABCDeqrstuv.
This general type of coding allows any group of 64 characters defined by all but the last six bits to be made available in single-byte codes, while keeping not only the control characters, but the digits and common punctuation marks, always available.
It may well be more commonly used than the one with 00 replacing 10 in the last byte of a multibyte character code. But there may also be cases in which that one is more appropriate, since some languages use their own digits and punctuation marks, and require more than 64 character codes, but less than 96.
It should be noted, however, there is already a more compact encoding of UNICODE in 8-bit characters, of the general type to which the scheme above belongs, that was proposed by Reuters. (It is called SCSU, the Standard Compression Scheme for UNICODE.)
There is also another scheme which allows compressed strings to have the same collating order as raw 16-bit UNICODE strings; it is called BOCU, Binary Ordered Compression for UNICODE. This is done by representing the first character in the string by its full 16-bit code, and then representing successive characters by codes representing the difference between that character and the preceding character. Small differences get shorter codes, so texts that remain within the same area of 128 characters can be coded with one byte per character. The codes for differences are themselves in order. An IBM patent was freely licensed for purposes of implementing this standard.
SCSU is described in Unicode Technical Standard 6, and BOCU is described in Unicode Technical Note 6.
The Unicode ranges used for Chinese characters are currently defined as follows (more extensions may be added in the future, of course):
4E00- 9FCC (9FFF) 20,941 CJK Unified Ideographs 3400- 4DB5 (4DBF) 6,582 CJK Unified Ideographs Extension A 20000-2A6D6 (2A6DF) 42,711 CJK Unified Ideographs Extension B 2A700-2B734 (2B73F) 4,149 CJK Unified Ideographs Extension C 2B740-2B81D (2B81F) 222 CJK Unified Ideographs Extension D F900- FAD9 (FAFF) 474 CJK Compatibility Ideographs 2F800-2FA1D (2FA1F) 542 CJK Compatibility Ideographs Supplement
Incidentally, the Hangul syllables are in the range from AC00 to D7A3 (D7AF).
Since even with UTF-8 encoding, the representation of texts in Chinese or in other languages which use Chinese characters, such as Japanese and Korean, is not particularly efficient, it is not surprising that enthusiasm for switching from the standards which were previously defined for those languages is limited.
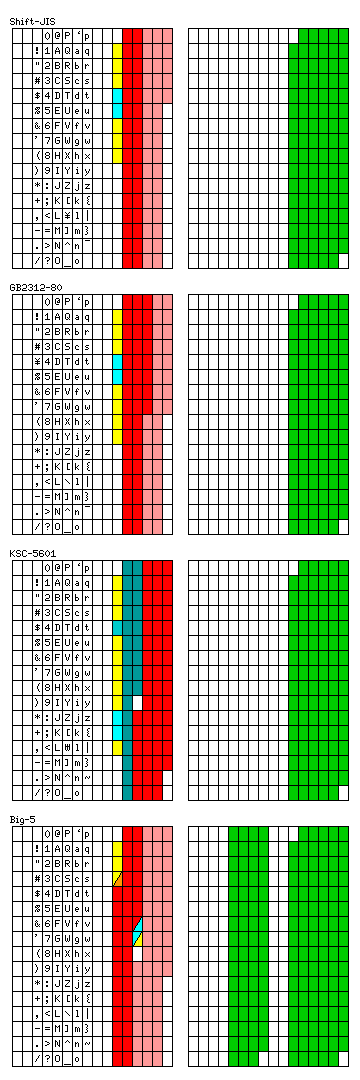
The diagram at the right gives an overview of some of those standards, which are known by the general name of Double Byte Character Sets. These character sets often use as their basic unit a 94 by 94 character matrix. A character in this matrix can be indicated by two printable characters in regular 7-bit ASCII.
Two basic methods are available for making use of such a matrix. If one is using 8-bit characters, then one can use both 7-bit ASCII and a 94 by 94 character set at the same time, since the high bit of a character can be used to indicate if it is simply a 7-bit ASCII character, or the first of two bytes indicating a single character. Note that one can use two 94 by 94 matrices of characters at once, since one can maintain the prefix property while still having the freedom to set or not set the high bit of the second character.
If one is using 7-bit characters, then one can use the SI and SO control characters, or escape sequences, to switch between using 7-bit ASCII characters for ASCII text, or for using those characters in pairs to indicate the members of one 94 by 94 matrix of symbols.
The charts on the right are based on the former method of using two bytes to represent a single character.
The first chart illustrates Shift-JIS, the name given to the modification of JIS 0208 that makes use of the high bit, as the original standard only envisaged using 7-bit characters with escape codes to represent Japanese characters.
The first character indicates the general type of the character being encoded. Thus, yellow indicates punctuation marks, special symbols, letters in the Roman, Greek, or Cyrillic alphabet. Light blue-green indicates characters in the Katakana and Hiragana syllabaries. Red indicates the first group of the most frequent Kanji, and pink the second group of less common Kanji.
In the second grid in the first chart, the green squares indicate the possible values of the second byte of a two-byte character.
The second chart illustrates the GB 2312 standard. This standard is similar in structure to the Japanese standard, except that the use of the high bit was envisaged from the start. Extensions to this standard have also been developed in Mainland China, the most important being GB 18030 which includes all the characters from Unicode in the CJK Unified Ideographs and CJK Unified Ideographs Extension A ranges.
The third chart illustrates KSC 5601, the standard used in Korea. A darker blue-green color is added to indicate the codes used for the Hangul alphabet used for the Korean language, and a still darker blue-green for the syllables made up of combined letters in normal Korean writing. Note that the Chinese characters, called Hanja when used to write Korean, belong to only a single sequence. This sequence contains 4,888 Chinese characters.
Incidentally, there is also a double-byte character set developed by North Korea, with room for 4,653 Chinese characters. Despite the fact that North Korea is said to have abolished all use of those characters for writing Korean, the text of the standard refers to them as Hanja characters for writing Korean, not as characters added to permit Chinese to be expressed in the code.
Chinese characters, often significantly modified in form, have been used in the past in the writing of several other languages besides Chinese. At one time, Vietnamese was written using characters built from the same components as Chinese characters, and on the same principles, but designed specifically for the Vietnamese language; these characters were known as Chu Nom. The ancient Tangut language was recorded with Xixia characters; these appear similar to Chinese characters, but are subtly different in appearance, and are said to be formed on different principles. Before the people now known as Manchurians adopted this name, they were known as the Jurchen, and they used a limited set of characters derived from Chinese characters to record their language before switching to a system similar to the traditional Mongolian script. Today, the Manchurians speak Mandarin, but their language is still used in another part of China by the Xibo, a minority ethnic group relocated to a valley in Sinkiang province in ancient times. The Zhuang people of Kwangsi province in China, who now use a Romanized script, once used, and to a limited extent still use, a script called Sawndip, also based on Chinese characters. Several other languages, in addition to these, which made some use of Chinese characters are listed in the Wikipedia article on Chinese characters.
In the three codes seen so far, the sequence of characters shown in red, with the most frequent characters, is ordered in terms of the pronounciation of the character, and the less frequent characters in both the Japanese and Mainland Chinese standards seen above are ordered in the traditional dictionary order, first by radical, and then by number of strokes.
The fourth chart illustrates the Big-5 character coding developed in Taiwan and most commonly used to represent tradidional Chinese characters. Here, each group of characters, both the most frequent and the less frequent, is ordered first by number of strokes, and then by radical.
The possible values for the second byte, shown in green on the second grid, extend across both possible values for the high bit. The entire value of the second character, including the high bit, is less significant than the first character, so the matrix is a straightforward 94 by 157 matrix.
Because the rows are wider, special categories of character, such as Katakana and Hiragana, don't have a series of whole rows to themselves, but instead are straddled across rows. This is shown by dividing character cells for the first byte by a diagonal line.
The orange color, introduced on this chart, indicates the characters of the phonetic National Alphabet (Zhuyin Fuhao), also known as Bopomofo.
A somewhat tidier character set was derived from the Big-5 character set, known as CNS 11643, which organized the characters from Big-5 into 94 by 94 blocks, as well as adding room for additional characters. In this set, there is also a first group of 5,401 frequently used characters, and a group of 7,650 less frequent characters (which omits two duplicates originally present in the Big-5 set).
Because some characters were also shifted from their positions in the Big-5 code due to corrections in stroke count, the mapping between Big-5 and CNS 11643 is non-trivial, although the number of irregularities is limited.
This character set currently uses seven planes of characters. The first two are used for the Big-5 repertoire; since Big-5 occupies roughly one and two-thirds planes, some additional room is present, and some of that is used to provide code points for the 214 classical radicals.
Each of the next three planes of characters contains a group of characters going from those with a few strokes to those with many stokes. So each of the first five planes in order contains a group of characters which are less frequently used than those in the preceding planes. The sixth and seventh planes, however, constitute a single group of characters by frequency, with those in that group with up to 14 strokes being in plane 6, and those with 15 or more strokes in plane 7.
Another character code devised in Taiwan for Chinese characters orders all the groups of characters within it in the classical order of radical first and then stroke count. (Incidentally, the classical order is also used in Unicode.)
It is CCCII, the Chinese Character Code for Information Interchange. It uses three bytes to represent a character, allowing 94 sets of 94 by 94 matrices of characters. However, unlike CNS 11643, which uses eight such matrices to represent the characters of Chinese, it is actually designed on the premise that only six such matrices are really needed, if one does not count variant forms of the same character.
The first group of six matrices represents the normal Traditional Chinese form of a character; the second the Simplified Chinese character forms used on the mainland. Then another ten groups are allocated to other Chinese variants, followed by one group for the Japanese versions of the characters and one for the Korean versions of the characters.
This huge character repertoire starts out with only 4,808 Chinese characters (instead of 5,401) selected as the most common ones. The second group of less common characters, however, is bigger, with 17,032 characters. These two groups, plus other miscellaneous symbols, take up about two and two-thirds bit planes. The rest of the six bit planes used for the first group of planes is used for the third group of characters, consisting of 20,583 characters considered to be rare.
In the United States, a variant of CCCII, known as EACC, is used by libraries.
The structure of the GB 18030 character coding is shown in the chart below:
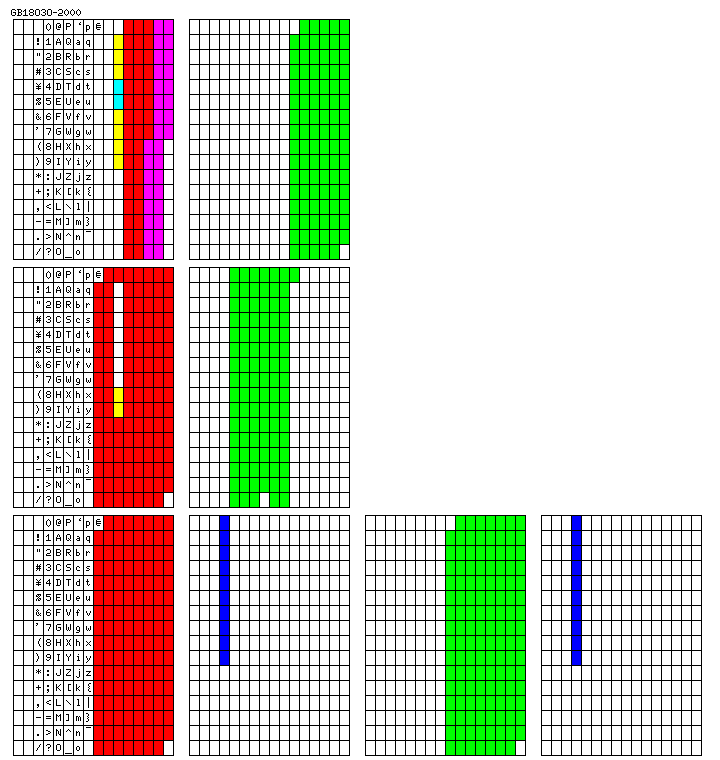
Additional two-byte characters are defined by clearing the high bit in the second byte; some of the code points are not used, being available for user-defined characters, and some are used for additional special symbols instead of Chinese characters.
Four-byte characters have the structure of being composed of two two-byte components with the two bytes coming from the same ranges. Thus, the second bytes of the two two-byte halves indicate 100 possible bit planes, each bit plane being of 126 x 126 characters.
The system of 214 radicals is usually identified with the K'ang-Hsi Tzu-Tien (KangXi Zidian), although I have read a claim that it was introduced in an earlier dictionary. This system was derived from the one using 540 radicals in the earlier Shuo-Wen Chieh-Tzu (Shuowen Jiezi) largely by lumping together the characters belonging to radicals which applied to very few characters. Thus, the 540 radical system attempted to indicate the "real" radical of every character, although some of its choices of radical have been open to criticism, while the 214 radical system was changed to work better as a character-finding aid. The Chinse word for "radical", Pu-shou (bushou) literally means "classifier", so such a change is legitimate. Like a determinative in Egyptian hieroglyphics, the radical normally indicates the general category to which the meaning of a character belongs, and is definitely not the root of a word, as the English term might be thought to imply.
The number of phonetic components used in Chinese characters has been variously estimated, with numbers from 858 to 1350 given.
One can think of the stock of Chinse characters as having been built up in this way: first, there is a group of simple character elements; some of them began as pictures, and others were like arrows pointing up and down to stand for "up" and "down". Then, an additional group of characters was created by combining two or three elements to express an idea; thus, the symbols for "sun" and "moon" were combined to make the character for "bright". Once a basic stock of a few hundred characters were made this way, the majority of Chinese characters could then be formed, built from one character indicating the general category of meaning to which the character belonged, and another having the same or a similar sound.
Since characters usually stand for the first syllable of a two-syllable word, at least when modern Chinese is written in classical style, the existence of many characters with different meanings but the same pronounciation is understandable.
Some characters have a more complex derivation than outlined above. One could simplistically conclude that there are at least 200,000 possible Chinese characters by multiplying together the numbers of radicals and phonetics. In practice, the K'ang-Hsi dictionary had 47,035 (or 49,030, if "graphic variants" are counted) characters, and later old Chinese dictionaries had even more, up to about 90,000.
About 4,000 characters are said to be enough for routine purposes, with perhaps another 2,000 being required to handle proper names and commonly-used alternative forms of characters. The Dai Kanwa Jiten by Morohashi, a large contemporary dictionary aimed at assisting the reading of classical Chinese, includes entries for 49,964 (after later revisions, 54,678) characters, and so the length of the K'ang-Hsi dictionary may not be entirely without justification.
Very recently, the Zhongua Zihai was published by the Chung Hwa Book Company, which covers 85,568 characters; it includes characters used for Chinese dialects, characters used in Japan and Korea, and new characters such as those used in the names of newly-discovered chemical elements.
Even that is not an absolute record: 106,230 characters are listed in The Dictionary of Chinese Variant Forms, compiled by the Republic of China Ministry of Education.
It has been noted above that whether or not the high bit is present in the second character allows a double-byte character set to encode two 94 by 94 matrices of characters.
The group of 32 control characters with the high bit set could also be considered as being available for use. These would allow the equivalent of a third 94 by 94 matrix of characters, since three possible ways to employ them in conjunction with another character drawn from a set of 94 exist:
Of course, two high-bit controls can also appear in a row; but an extra 1,024 characters would seem to be of limited utility. Of course, they could be used as the beginning of a three-byte character.
In any event, this seems to offer the opportunity of using two bytes to provide access to a larger character repertoire than provided with any existing DBCS code for Chinese characters. This type of technique has been used in some extended character codes used in South Korea.
Since it is plane 1 that is divided into numerous small parts for the Roman alphabet and various special symbols, it would seem that it is that plane (rather than the last one) that should be represented using the possibilities involving the high-bit controls.
The two possibilities with the high-bit control coming first involve rows of 94 characters, and so they are the more "conventional"; I would use those to represent the 4,084 most common characters. Perhaps some of those codes could also be used to represent the first few of the remaining 17,032 less common characters, but as I do not plan to include those of the 20,583 rare characters that are in the first three planes, and having the first row of each 94 by 94 matrix reserved also does not fit well with the amount of rearrangement that seems to be appropriate, there is enough room to represent the less common characters entirely in the two conventional 94 by 94 matrices which do not involve the high-bit control characters.
Three consecutive values for the first character would make a 96-character row when the high-bit control character comes last, and, as noted, those codes can be used for the unusual characters.
To be specific, I am proposing the following representation of most of the first three bit planes of CCCII:
(miscellaneous characters) A1 81 - A1 9F 21 22 21 - 21 22 3F A2 80 - A2 9F 21 22 40 - 21 22 5F A3 80 - A3 9E 21 22 60 - 21 22 7E A4 81 - C5 9A 21 23 21 - 21 2F 7A (4,804 most common) 80 21 - 80 7E 21 30 21 - 21 30 7E 81 21 - 9F 7E 21 31 21 - 21 4F 7E 80 A1 - 80 FE 21 50 21 - 21 50 7E 81 A1 - 83 B0 21 51 21 - 21 63 30 (17,032 less common) A1 21 - A1 7E 21 64 21 - 21 64 7E A2 21 - BB 7E 21 65 21 - 21 7E 7E BC 21 - BC 7E 22 22 21 - 22 22 7E BD 21 - FE 7E 22 23 21 - 22 64 7E A1 A1 - A1 FE 22 65 21 - 22 65 7E A2 A1 - BA FE 22 66 21 - 22 7E 7E BB A1 - BB FE 23 22 21 - 23 22 7E BC A1 - F9 F3 23 23 21 - 23 60 73
Because the less common characters fit entirely into two bit planes, and the most common characters fit entirely into the two thirds of a bit plane that can be conventionally encoded, and none of the rare characters are included, although some of them were present in the first three bit planes of CCCII, a considerable amount of empty space is left in this code.
To maximize its general usefulness, and as Katakana and Hiragana are already included in the special characters carried over from CCCII, I propose to use some of this code space for Hangul, as follows, this time with codes corresponding to those of KSC 5601:
C6 81 - C6 9F 24 21 - 24 3F C7 80 - C7 9F 24 40 - 24 5F C8 80 - C8 9E 24 60 - 24 7E 84 A1 - 84 FE 30 21 - 30 7E 85 A1 - 9C 7E 31 21 - 48 7E
The Hangul alphabet is placed within the codes with a high-bit control character as the second character, while the compound Hangul characters are placed after the most frequent Chinese characters at the end of the two-thirds of the extra bit plane that begins with a high-bit control character.