The previous page dealt with UTF-8, a scheme for extending the ASCII character set to embrace all of UNICODE, and a suggestion of mine to make use of some codes it does not use in order to make it more efficient with regard to bandwith, at the expense of some of its desirable and elegant properties.
On this page, I first describe the current official standard for transmitting lower-case characters within the framework of 5-level teletypewriter code, and then I proceed to propose a compatible scheme of providing for representing, with reasonable efficiency, the entire UNICODE repertoire, divided between character sets for different languages, within 5-level code.
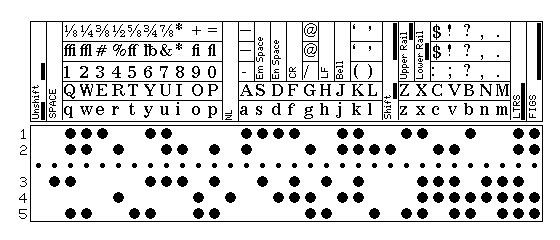
The ASCII over AMTOR code shown in the chart of 5-level code representations and variants on the introductory page of the chapter on telecipher machines illustrated one method of transmitting lower-case characters by means of 5-level code, using the all-zeroes character as an extra shift character to access them. There is also an official standard of very recent vintage for using lowercase with 5-level code, which works on a significantly different principle: a LTRS code while already in letters case is used to toggle between upper and lower case.
I'm not kidding, and, no, I didn't make this up myself; this standard is CCITT Recommendation S.2 (Melbourne, 1988), also adopted as ITU-T Recommendation S.2. (It was very hard to locate it again on the Web, after having originally found it by accident.)
This standard does not include ASCII graphics characters, but it was designed to be compatible with the use of the all-zeroes code for supplementary alphabetic characters; these characters could have their lower case available using their shift character in the same fashion as LTRS is used.
This new standard works as follows:
Initially, in the absence of any unusual combinations of FIGS and LTRS codes, the FIGS code switches to printing special characters, and the LTRS code switches to printing capital letters. This is called upper-case mode.
When one is already in letters case, a superfluous LTRS code always switches from upper-case printing to lower-case printing and back again. When in upper-case mode, it also sets lower-case mode. In lower-case mode, whether one is printing upper-case or lower-case letters at the time one has switched to printing figures characters, when one returns from printing figures characters to print letters, one begins with lower-case letters. A superfluous LTRS code encountered when printing lower-case letters switches one to printing upper-case letters, but one remains in lower-case mode, so that a LTRS code exiting from printing figures-case characters still returns one, initially, to printing lower-case letters.
It is only the sequence FIGS LTRS that operates as a reset into upper-case mode. In normal upper-case mode, when returning to letters case from figures case, one is returning to upper-case letters.
This can be a bit confusing, so I will illustrate it with an example:
ABC [FIGS] 1234 [LTRS] DEF [LTRS] ghi [FIGS] 1234 [LTRS] jkl [LTRS] MNOPQ [FIGS] 1234 [LTRS] rst [FIGS][LTRS] UVW [FIGS] 1234 [LTRS] XYZ
Essentially, toggling between upper and lower case with a superfluous LTRS is always on. FIGS LTRS resets (to upper-case, or capitals) only the default letters case that a normal LTRS, used for exiting figures printing, returns to. And that default flips back to lower case the first time lower case is accessed with an (otherwise) superflous LTRS.
Thus, this example proceeds as follows:
ABC [FIGS] 1234 [LTRS] DEF
One begins by having only figures and upper-case letters available.
[LTRS] ghi [FIGS] 1234 [LTRS] jkl
The superfluous LTRS now switches one into lower-case mode, as well as immediately switching to printing lower-case letters. The FIGS shift still takes you to normal figures case, and a LTRS shift returns you to lower-case letters.
[LTRS] MNOPQ [FIGS] 1234 [LTRS] rst
A superfluous LTRS shift changes you to printing upper-case characters, but the mode remains lower-case mode. Thus, FIGS takes you to printing digits, and LTRS takes you to printing in the default case for the current mode, which is lower case.
[FIGS][LTRS] UVW [FIGS] 1234 [LTRS] XYZ
A superfluous LTRS toggles between printing upper-case and lower-case, but only moves you from upper-case mode to lower-case mode. To change mode in the reverse direction, the combination FIGS LTRS is required. Once that combination is used, not only do you print in upper-case, but a LTRS shift used after printing figures will return you to the new default case, which is again upper case.
Note that it would be possible to use a superflous third-shift character to toggle between upper- and lower- case Cyrillic; the upper-case/lower-case status of Latin and Cyrillic characters could be independent, or could be joined. Additionally, since with the Cyrillic character set, and with even a number of national-use variants for languages using the Latin character set, some additional letters are placed in the figures-shift repertoire, one could even use a superfluous figures-shift character for toggling the upper/lower case status while in figures mode.
It is also noted in that standard that some teletypewriters might normally ignore the superfluous LTRS code for a higher degree of compatibility with existing equipment, and be awakened into printing in lower case, as well as into lower-case mode, only with the sequence FIGS LTRS LTRS which consists of the FIGS LTRS reset into upper-case mode followed immediately by a superfluous LTRS code.
The bulk of a typical text document is lower-case letters and spaces. Thus, it would seem that if one is using a fixed number of bits per character, a five-bit code with occasional shifts is optimal from the viewpoint of bandwidth efficiency.
The problem with using a five-bit code is to have available enough reasonably short shift codes so as to provide a large enough character repertoire for any use. If one is constrained to maintain compatibility with ITA 2, one does have the additional limitation that two character positions are used for the carriage return and line feed; in an ideal character code, they might be combined into a newline character, or relegated to some shifted character repertoire.
The use of a superfluous LTRS character to switch between upper and lower case made it possible, within ITA recommendation S.2, to add lower case to ITA 2 without having to use the only 5-bit combination in ITA 2 that remained unused, 00000, or Character no. 32. Of course, it would have been preferable to leave it as a null character, as it corresponds to unpunched paper tape. The combination 11111, which would have been attractive as another ignored character, is used as the next best thing, the letters shift.
Since we are going to use 00000 to access additional characters, it will be referred to below as ALT.
Several possible ways to modify ITA 2 for either an increased character repertoire or increased bandwith efficiency come to mind:
If the character set of ITA 2, with three national-use characters, and lower-case, is adequate, then the ALT character can be used to save bandwidth as follows:
When printing lower case letters, an ALT preceding a letter could make it uppercase without shifting, and thus requiring a shift back out.
When printing upper case letters, an ALT could be used to select a single figures-shift character.
Since ALT is used as an escape for printable characters, ALT FIGS, ALT LTRS, and ALT ALT, for example, would be available for special purposes, such as switching to other character coding schemes.
While ALT is the only unused 5-bit code, there are three national-use positions in the figures case, the shifted counterparts of the letters F, G, and H. These could be used to shift into three additional ensembles of characters; for example, a set of extra letters, such as accented letters, a set of extra punctuation marks and other special symbols, and a set of control characters.
This wouldn't involve the use of the ALT code at all, and by using the national-use characters in this way, the resulting code need not favor any existing assignment of those characters.
Many countries that use a script other than the Latin alphabet use the ALT character as a third shift into their alphabet, so that their teleprinters can still use the Latin alphabet.
In this case, when within this other alphabet, a superfluous ALT character could be used in the same way as a superfluous LTRS character to switch to its lowercase set. When shifting to an alphabet from either the figures case or the other alphabet, the case should begin at the case defined by the current mode, and there should only be a single mode setting for both alphabets. FIGS ALT as well as FIGS LTRS should cause a reset to upper case mode, as well as a shift to the alphabet indicated by the last shift character.
The ASCII over AMTOR scheme uses the ALT character in a way that increases compatibility with terminals that ignore it; it does not change whether letters or special characters are printed, it merely shifts to a second set of letters or special characters, respectively, when in letters or figures case.
This allows four, rather than three, sets of 26 printable characters to be used. However, that specific scheme uses lower case as its additional set of letters, and Recommendation S.2 already provides a different method of accessing lower case.
If the second set of letters characters is a national alphabet, then when shifting into figures case, it would make sense to still use the normal figures characters, not the supplementary set, but to return to the national alphabet when shifting into letters case.
Thus, the ALT character, when used while in letters case, should toggle a persistent value indicating which alphabet is in use, but which group of figures characters is used should always be reset to the default group when outside of figures case.
The combination ALT LTRS is clearly available for use; and if the alphabet in use is toggled persistently, a code for resetting to the default alphabet is needed.
It may be noted that, in some existing arrangements, extra letters for a non-Latin alphabet with more than 26 letters, or accented letters for a language using the Latin alphabet, occupy national-use positions in the figures case. As we have seen, the use of ALT as an escape character, rather than as a shift, furthers bandwidth efficiency, since unlike a shift, no second character for shifting back is needed, when an isolated character from a supplementary group is required. In addition, it would seem that shifting between the Latin alphabet and a non-Latin alphabet is an infrequent operation, and that additional special characters are likely to be largely used in isolation.
Thus, it appeared to me that it would be sensible to use a two-shift code to switch between national alphabets, and use ALT as an escape for supplementary characters, perhaps along the following lines:
When in figures case, an ALT preceding a printable character causes a character from a supplementary set of special characters to be used.
When in letters case, an ALT preceding a letter causes a character from a supplementary set of letters to be used.
The combination ALT LTRS would be used to toggle between national alphabets. With regard to being in upper or lower case, it should not have any effect at all. When it is encountered in figures case, though, it would shift into the next national alphabet, and, like a letters shift, it would select the case that corresponds to the default case for the current mode. (Note that when the national alphabet is different, the characters in the supplementary set of letters are also different.)
The combination ALT FIGS would be used to toggle between different supplementary sets of special characters; it would not shift to printing characters from that set, it would only change what characters were caused to print in future by an ALT character used as an escape.
The combination ALT FIGS LTRS should still be available, and would allow resetting to the default national alphabet. (Ending in LTRS, it also must function as a letters shift.)
The combination ALT LTRS FIGS is also available, and would be used to reset to the default supplementary set of special characters. (Ending in FIGS, it must also function as a figures shift.)
When already in figures shift, in addition to the ALT character, it is possible to assign a function to a superfluous FIGS shift. As it might be useful to print an extended sequence of supplementary figures shift characters, depending on the use to which they were being put, I had started from that point, only allowing switching between supplementary figures shift character sets when shifted into printing from the current supplementary figures shift character set. The ALT character was used for that function when in that mode. While using single-character codes as much as possible is efficient, as a starting point it made the scheme more difficult to understand than it needed to be.
In the introduction to the section on teletypewriter ciphers, the six-bit code used for teletypesetters, which had 5-level code as its basis, was shown. The sixth bit allowed letters and figures to have separate codes, so that a letters shift and a figures shift were not needed, but there were shift and unshift codes to increase the repertoire of figures characters as well as to allow lowercase letters.
This illustrates how one might define a 5-level code inspired by that 6-level code:
Instead of strictly extending ITA 2, some incompatibilities are allowed. To add a "shift" code and an "unshift" code to the existing letters shift and figures shift, now still required, it is necessary to free up an additional code point. This is done by using the code for carriage return to instead represent newline, so that an additional code for line feed is not needed.
Because the shift and unshift codes double the number of figures characters, some positions can be used for other purposes and still leave space for the printable characters used by the teletypesetter code. Thus, codes for line feed and carriage return are given, in case those functions do occasionally have to be separated; a code is given for bell, and one for em space and one for en space.
As the teletypesetter code included a large number of additional control functions, perhaps the code indicated as bell might instead be used as a control shift; also, in addition to the upper rail and lower rail shown, another option providing more of the ASCII character set might be seen as desirable.
That could lead to something like this:
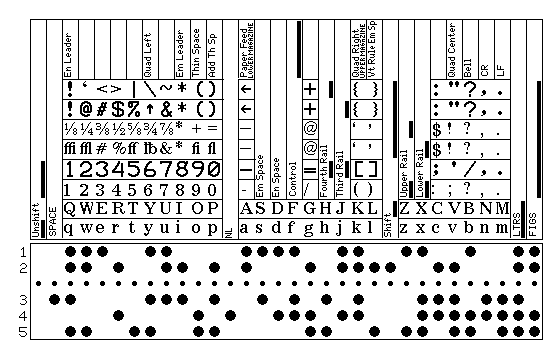
In the simplest model, the three statuses of letters shift versus figures shift, unshift versus shift, and lower rail versus upper rail would be independent and static. A more complex model might promote greater transmission efficiency. Thus, there could be one independent static status of shift versus unshift that applies while in letters shift, while entering figures shift would always start from the more common unshifted state. Upper rail versus lower rail would remain static and independent as a status, but the shift codes for them, only available in figures shift, could also change from unshifted to shifted, since it is only in that status that the distinction is visible, and so setting the upper rail/lower rail status could also serve as an indication that moving to shifted status, where characters the printing of which is affected by it, is desired.
The different schemes of extending ITA 2 above each have their advantages and drawbacks. And, of course, different character sets are also required for different purposes. If some special shift code combinations, whose use would not conflict with those used in repertoires of types I through V were used to select a repertoire and a language, one could have an extended ITA 2 that could be used to access the character sets for any number of languages, each one having a repertoire designed around it.
Of course, languages like Thai or Armenian would be served more efficiently by a 6-bit code than by a 5-bit code. They could still be handled, as Russian is, by placing the least frequent letters in the supplementary alphabetic set. But languages such as Chinese could be efficiently served, for example by using pairs of letters to represent a character in the normal letters shift, and sets of three letters to represent a character after an ALT character indicates the supplementary character set is to be used.
For the purpose of switching between repertoires at a high level, I propose the sequences ALT LTRS FIGS LTRS and FIGS LTRS FIGS LTRS. In this way, many shorter sequences are available, allowing additional functions to be incorporated into an extended version of the type V character repertoire which will be described below. The additional possibilities would also, of course, allow extension to character repertoires of the four other types if desired.
To allow a Type V repertoire to include many different alphabets and special character sets, I had proceeded to define a large number of shift code combinations, as follows:
The following diagram may make this form of the proposal for character repertoires of type V a little clearer, although it only illustrates part of what it involves.
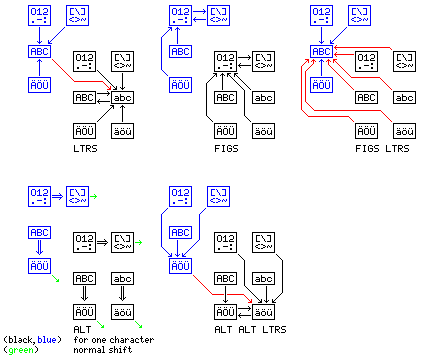
Only the codes that remain within a single character repertoire for a single language are depicted. Thus, what happens when a superfluous ALT code is found when printing extended figures-shift characters continuously (that is, within the mode reached by a superfluous FIGS code within figures-shift mode) and when printing extended letters-shift characters continuously (that is, within ALT ALT LTRS mode) is only shown as a small green arrow pointing off to one side; there is only an effect if there is more than one set of extended figure or alphabetic characters, respectively, and the result of an ALT LTRS code, which switches to another language entirely, is also not shown.
Upper case mode is shown in blue, normal lower case mode in black. The red arrows show how a superfluous LTRS code encountered in upper case mode, as well as a superfluous ALT ALT LTRS code, switches from upper case mode to lower case mode as well as to lower case, and how FIGS LTRS switches from lower case mode back to upper case.
Although it should be apparent what the different boxes in the diagrams stand for, making it explicit which modes they refer to may help in ensuring there is no ambiguity in the description of this proposed mode:
-------------- --------------
| upper-case | | upper-case |
| mode | | mode |
| | | extended |
| figures | | figures |
| shift | | shift |
| | | |
| | | |
-------------- --------------
--------------
| upper-case |
| mode | -------------- --------------
| | | lower-case | | lower-case |
| letters | | mode | | mode |
| shift | | | | extended |
| upper | | figures | | figures |
| case | | shift | | shift |
-------------- | | | |
| | | |
-------------- -------------- --------------
| upper-case |
| mode | -------------- --------------
| extended | | lower-case | | lower-case |
| letters | | mode | | mode |
| shift | | | | |
| upper | | letters | | letters |
| case | | shift | | shift |
-------------- | upper | | lower |
| case | | case |
-------------- --------------
-------------- --------------
| lower-case | | lower-case |
| mode | | mode |
| extended | | extended |
| letters | | letters |
| shift | | shift |
| upper | | lower |
| case | | case |
-------------- --------------
The diagram may also make explicit the substance of the different cases. Instead of using national-use positions in the figures case, any extra letters needed for a given language are placed in the set of extended alphabetic characters. The extended figures characters are intended to be usually used for the kinds of characters reached by the ALT character in ASCII over AMTOR; the other useful characters included in ASCII for which there was no room in the figures case of normal 5-level code.
The following diagram:
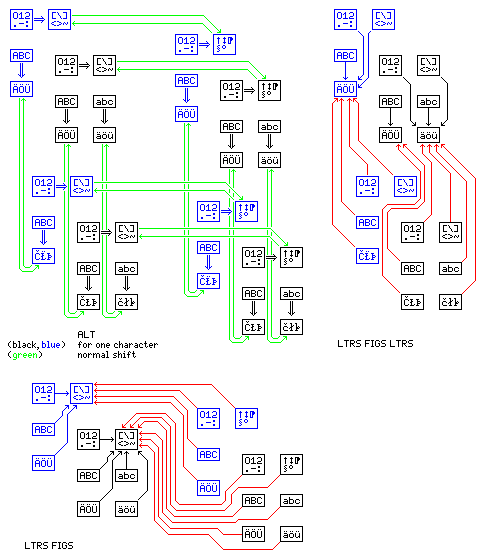
illustrates more fully what happens when superfluous ALT codes are encountered, by depicting the transition between character sets with different extended alphabetic characters or different extended figures characters.
LTRS FIGS and LTRS FIGS LTRS, in a sense, work the same way as a superfluous ALT code, except they only move to the first of the possible extended figures character sets or the first of the possible extended alphabetic character sets respectively, but they shift to those character sets from anywhere, preserving the distinction between upper-case mode and lower-case mode, and, in the case of LTRS FIGS LTRS, the distinction between upper and lower case themselves as well.
As for ALT LTRS, the following diagram attempts to show how it works:
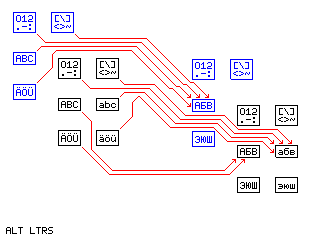
Again, ALT FIGS LTRS, not shown, works the same way as ALT LTRS, except that it only causes a transition directly to the first of the available languages.
For reasons of legibility, it was only able to show the transition from one language to the next; it must also be recognized that ALT LTRS would cause the same transition from the second language in the diagram, either to a third one in a cycle, or back to the first one if there are only two languages to toggle between.
After having developed much of the scheme outlined above, I saw that it would work nicely enough with Egyptian hieroglyphics: that language has an alphabet of 22 or 24 letters plus a wide symbol repertoire which could be handled by two or three code symbols in the extended alphabetic set. One could use the case shift to cycle through three character sets, hieroglyphic, hieratic, and demotic, despite the fact that they're not strictly isomorphic in the way that upper-case and lower-case are; this would be a trivial and obvious extension of the scheme. Or those character sets could be treated as different languages.
But that led me to thinking of Japanese. If one uses case-shifting for non-isomorphic character sets, treating hiragana as the lower case of katakana naturally comes to mind. But both of those syllabaries have considerably more than 26 characters, and so one has to use the extended alphabetic characters for the less common syllables.
And exactly where does that leave kanji?
One way to address this is to make use of the fact that it is normally the hiragana characters, not the katakana characters, that are used with kanji. Hence, a reasonably efficient route exists in the framework of the scheme as outlined, as follows:
Use the superfluous LTRS code to switch between kanji and hiragana, and use ALT LTRS to switch between this mode and katakana.
A particularly elegant possibility is to begin in katakana mode, switch to kanji with the first superfluous LTRS, toggle between kanji and hiragana with any subsequent superfluous LTRS, and return to katakana using the FIGS LTRS sequence. This makes kanji the case to which one returns when using LTRS to return from printing figures characters: katakana is the "original" upper case, kanji is lower case, and hiragana is the upper case used in lower case mode. By avoiding the use of ALT LTRS, this causes Japanese to be treated as a single language, which, of course, it is.
A more pedestrian route would be to use ALT LTRS to cycle between the Latin alphabet and katakana and hiragana, with the Latin alphabet being the base character set reached by ALT FIGS LTRS, and to access kanji by the use of a superfluous ALT code when in the ALT ALT LTRS case of the hiragana character set and likely also the katakana character set. This avoids the use of upper and lower case for tasks for which they are not really intended.
Given that the sequence FIGS LTRS is determined by Recommendation S. 2, and ALT is the only available single-character code, and thus is needed for the operations requiring the shortest codes, how is it possible to choose codes that can appear consecutively, without ambiguity, and still have a wide selection of relatively short codes?
One troublesome situation that I noted after assigning many of the shift sequences to my extended version of the type V character repertoire is that it might be desired, after shifting to a particular script, to print as the first character in that script a character from its extended alphabetic set, or to switch from upper to lower case or the reverse at the same time as one switches scripts.
To allow as many short codes as possible, an advantage can be derived by taking into account how the codes are used. For compatibility, any code ending in LTRS would select some type of alphabetic characters, and any code ending in FIGS would select some type of special characters. Thus, a superfluous LTRS code might be used immediately following a code ending in LTRS, but a FIGS code would not be needed immediately after such a code. But ALT is used as an escape in either case.
Thus, I initially decided it would be sufficient to restrict codes to the following form:
In most cases, this leads to no problem, but there are occasional cases in which it might be desired to have two codes following each other in a way that would create ambiguity; for example, ALT LTRS, used to switch to another national script, cannot be followed immediately by FIGS, even though there might be a change in the figures shift when changing scripts as well. This is, however, unlikely. ALT LTRS is being used the way ALT had been used as a third shift; changing from using the Latin alphabet to using the alphabet of a national script within a character repertoire associated with a given nation. So it is intended that the figures shift will not change; this is further facilitated by the fact that extended alphabetic characters, associated with a given alphabet, have their own place, and need not be included among figures shift characters.
The possibility that such problems may arise, however, was addressed by using ALT ALT as an escape to create a series of shift codes. As these codes contain neither LTRS nor FIGS, they do not cause a switch between letters and figures shift, but they can switch which set of printable characters is to be used in other respects, and thus they are used for mode changes which may need to be combined with other mode changes in a flexible manner.
The following table summarizes the actions of the various shift codes which operate within this particular type of character repertoire:
| Code | LETTERS FIGURES shift | UPPER LOWER case | UPPERCASE LOWERCASE mode | extended figures shift character set | extended letters shift character set | NORMAL EXTENDED figures shift characters | NORMAL EXTENDED letters shift characters | national script |
| LTRS if in figures shift or if printing extended letters shift characters | letters | sets to match mode | nc | nc | nc | normal | normal | nc |
| FIGS if in letters shift or if printing extended figures shift characters | figures | nc | nc | nc | nc | normal | normal | nc |
| LTRS if printing normal letters shift characters | letters (nc) | inverts | lowercase | nc | nc | nc | nc | nc |
| ALT ALT LTRS if printing extended letters shift characters | letters (nc) | inverts | lowercase | nc | nc | nc | nc | nc |
| FIGS LTRS | letters | upper | uppercase | nc | nc | nc | nc | nc |
| FIGS if printing normal figures shift characters | figures (nc) | nc | nc | nc | nc | extended | nc | nc |
| ALT ALT LTRS if not printing extended letters shift characters | letters | sets to match mode if not in letters shift | nc | nc | nc | nc | extended | nc |
| ALT ALT E | nc | nc | nc | nc | nc | extended if in figures shift | extended if in letters shift | nc |
| ALT if printing extended characters | nc | nc | nc | increments if in figures shift | increments if in letters shift | nc | nc | nc |
| ALT FIGS | figures | nc | nc | increments | nc | nc | nc | nc |
| LTRS FIGS | figures | nc | nc | first | nc | extended | nc | nc |
| ALT LTRS FIGS | figures | nc | nc | first | nc | nc | nc | nc |
| LTRS FIGS LTRS | letters | sets to match mode if not in letters shift | nc | nc | first | nc | extended | nc |
| ALT ALT A | nc | nc | nc | increments | nc | nc | nc | nc |
| ALT ALT B | nc | nc | nc | nc | increments | nc | nc | nc |
| ALT ALT C | nc | nc | nc | first | nc | nc | nc | nc |
| ALT ALT D | nc | nc | nc | nc | first | nc | nc | nc |
| ALT LTRS | letters | sets to match mode if not in letters shift | nc | first | first | normal | normal | increments |
| ALT FIGS LTRS | letters | sets to match mode if not in letters shift | nc | first | first | normal | normal | first |
| ALT ALT G | nc | nc | nc | first | first | normal | normal | increments |
| ALT ALT H | nc | nc | nc | first | first | normal | normal | first |
More recently, thinking of a more modest modification of the five-level ITA 2 code, I came up with this:
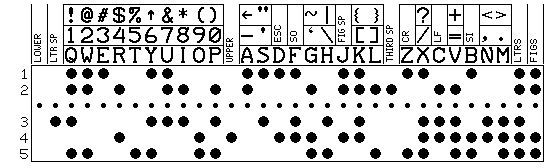
The space character is replaced with "letters space", providing the benefit of unshift on space; although the code involves shifting between letters and figures, space characters cause a return to letters case to avoid garbles.
Upper and lower case are provided; two codes are used to switch between them. Another code is taken for the "third space"; this works like letters space, except that it returns to the letters case of a "third-shift" alphabet. This way, when a printer is capable of switching to an alternative non-Latin alphabet, such as Cyrillic or Greek, spaces also serve to avoid garbling due to errors switching to the wrong alphabet.
In addition to using the all-zeroes code, the codes for carriage return and line feed have to be taken away to allow these additional control functions to have their own codes.
Thus, carriage return and line feed are moved to the figures shift repertoire, as was done with the 5-level code used for input-output by the Ferranti Mercury computer. Since WRU and BEL were functions in the figures case on conventional 5-level teletypewriters, this is not unprecedented.
Also, instead of using a single shift code to switch to an alternate script, I let the normal letters shift character switch from figures to letters for any script, and switch to an alternate script with SO and back to the Latin alphabet with SI. These functions are both in figures shift, and do not switch out of it (although including a switch to the letters shift in them, as sometimes only the letters shift characters are changed, may save characters, so I will need to ponder this further).
Incidentally, some of the rationale behind my choice of character assignments should be noted.
The space character, being common, had the code 00100 to minimize mechanical wear. Thus, I assigned the "third space" character to the similar code 00010 (in 54321 order) originally used for line feed so as to follow that principle.
The all-zeroes code, when it was used for a purpose, was sometimes used for the third shift code that switched to a non-Latin alphabet.
And letters shift had an all-ones code. Since those codes also perform the same functions with five-level paper tape as the ASCII NUL and DEL characters, being used to overpunch an error in the case of the all-ones code, and filling blank leader in the case of the all-zeroes code, despite "doing something" by shifting case, instead of being completely ignored, it seemed to me that this was possible only when the function was a case shift - since a case shift can be completely undone by a subsequent case shift.
Thus, at an earlier stage of the design, when I had the upper case and lower case shifts in the figures shift, I thought to make the all-zeroes code the one used for the additional "third space" character, but then realized that this would be a mistake.
The letters space both shifts out of figures case and out of an alternate non-Latin script, and the third space shifts out of figures case and into an alternate non-Latin script, but neither one affects whether one is in upper and lower case.
Unfortunately, there are not another two codes available to allow both cases to be covered, and printing upper-case instead of lower-case or vice versa will not cause as serious a garble, text will not become completely unreadable. However, I have been trying to think of a way to address this issue as well.
The ITU S.2 proposal for lower case makes use of superfluous letters shift codes. If letters space and third space became upper space and lower space instead, but it took two of them in a row (with no intervening case shift codes) before a shift took place, one could define an additional side channel, where the repeated sequence upper space, upper space, lower space, for upper-case text, or lower space, lower space, upper space, for lower-case text, also indicated that one was in shift-out non-Latin mode, with the sequences lower space, upper space, lower space and upper space, lower space, upper space triggering the correcting shift, and with three spaces of the same kind in a row triggering the opposite correcting shift, that could work without defining additional control characters for which no room appears to be available.
One possibility might be something like this:
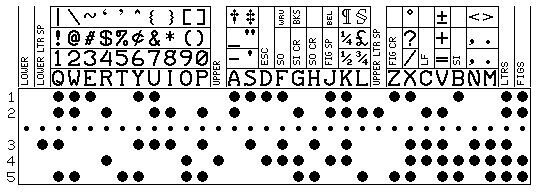
Here, the commonly-used case of upper and lower case is that for which each space within the letters shift serves as a reminder. Whether one is in the SO or SI state, shifted out to a non-Latin alphabet, or back in to the default one, is noted by the carriage returns: SO CR sends one to the non-Latin alphabet in letters case, SI CR sends one to the normal Latin alphabet in letters case, and FIG CR performs a carriage return without changing the shift state, since it is within the figures case.
Additional control codes are available by basing the character repertoire in figures case on a 44-key electric typewriter instead of on the larger ASCII keyboard and its character set; the additional, and rarely-used, ASCII characters, when they appear, need to be prefixed by an ESC. A few additional useful printable characters have also been added.
Further reflection has led me to the conclusion that there are two major issues with the design shown above.
The first issue is that the tension between allocating a higher priority to the distinction between a non-Latin alphabet and the Latin alphabet, since it causes more severe garbles, or allocating a higher priority to the upper-case and lower-case distinction, since that one would be commonly present, while alternate alphabets would be rare, at least in come contexts, is irreconcilable.
However, just as a garbled signal would not require a correcting signal to be sent to reassure the receiver that a valid control character had really been sent requiring him to unplug his 5-level code teleprinter, and replace it with one that used ASCII or EBCDIC, whether or not a non-Latin alphabet is going to be used on a given radio net or a given national telegraph system is a stable characteristic of the network.
Thus, it is entirely reasonable to define, in the standard, a primary space and a secondary space, and a primary carriage return, and a secondary carriage return, and to define two distinct modes of operation, between which equipment can be manually switched, but not switched by any control character:
One where primary space puts one in upper case as well as letters shift, and secondary space puts one in lower case as well as letters shift, while primary carriage return puts one in the shift-in state of the Latin alphabet and secondary carriage return puts one in the shift-out state of an alternate alphabet, and
Another one where primary space puts one in the shift-in state of the Latin alphabet as well as letters shift, and secondary space puts one in the shift-out state of the alternate alphabet as well as letters shift, while primary carriage return puts one in upper case, and secondary carriage return puts one in lower case.
The second one is that having both upper-case and lower-case characters in figures shift is not well-suited to how digits, punctuation, and special characters are used. Using a two-character escape sequence for less common characters, as that doesn't require an additional shift out at the end, would be more efficient.
But in that case, it would be desirable to have as many printable characters available in figures shift directly in any revised code as are available in the existing ITA 2 code, even including the three national use positions.
Fortunately, this is possible. Only two control characters absolutely must be directly available in figures shift directly: the escape character, as it provides access to all the other control characters, and the figures space character, so that the space character is never expanded to more than one code.
This does mean, though, that carriage return and line feed, once single codes, are now doubly relegated; not only are they moved to figures shift, but they are also now two-character escape sequences. However, they are relatively rarely used.
Another consideration is that the upper-case/lower-case distinction must be allowed to be significant in figures shift.
That in Russian, for example, several of the less-common letters of the alphabet are in figures shift, might not be decisive; shifting out to an alternate alphabet might change the characteristics of the code significantly; for example, one could shift out to switch to printing Chinese, which could be implemented by using the shift-in character set for everything but lower-case letters shift, within which every three letters would correspond to a single Chinese character from a set of 17,576 characters.
But in French, German, Swedish, and many other European languages, some or all of the three national-use positions are used for precomposed accented letters, and it would not be reasonable for those to be available in upper-case only. Admittedly, lower-case only would correspond to what many keyboards and versions of 7-bit ASCII where the national-use positions were used.
A possible objection here is that this would be wasteful on a mechanical teleprinter where most of the typebars would have to contain two copies of the same figures shift character in order that three or fewer of them would vary between upper-case and lower-case accented letters depending on the state of that shift. However, given the enormous cost advantages of terminal equipment using digital electronics over purely mechanical printers at the present time, as far as I am aware, the latter are no longer in production anywhere in the world. Thus, given the lack of a time machine with the aid of which one could make any new standard retroactive to a time when this was not the case, I cannot regard this as a serious objection.
Thus, I now envisage a code arrangement like the following:
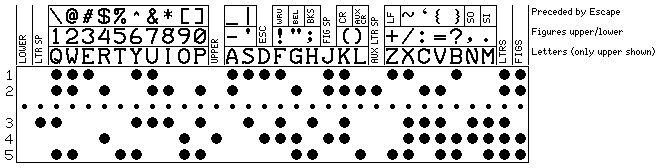
This has the one serious problem that not a single code position is left unused for further expansion.
However, one could follow the idea used in ITA Recommendation S.2, and make use of superfluous figures shifts, letters shifts, upper-case shifts, lower-case shifts, and secondary letters shifts to reach additional functions. Of course, if they shifted into alternate cases, there would be no garble correction for those.
As well, there is no real reason why ESC ESC and ESC figures space couldn't be used as two additional control codes; for that matter, even ESC letters space, ESC secondary letters space could be considered, and, if one was more desperate, ESC preceding the remaining codes used as shifts. And, naturally, one of the first things to use an additional control code for would be an additional escape, so that the issue would not recur. Well, at least, given Parkinson's Law, not right away.
Actually, it's worse than there not being any code positions left: as is obvious from the image, my intent was to cover all the printable characters in 7-bit ASCII. However, the code has shown only has 92 printable characters, so I had forgotten two of them - the less-than and greater-than symbols. It's not even immediately clear what the fix could be. The most obvious option seems to be to remove the control functions WRU and BEL, placing them as the first two allocations for control functions prefixed with ESC ESC.
A second escape character could be added to figures case if just one additional character, such as the exclamation mark or the double quote, were moved to the rarely used characters to be prefixed by ESC. This, however, would mean that not all three of the national use positions would be available for printable characters, the loss of one major benefit of this particular code arrangement.
Finally, I opted for conceptual simplicity instead of maximum efficiency, and chose to make the printable characters reached with ESC, but not the control characters, dependent on whether the upper-case or lower-case shift state was in effect when the escape character was issued:
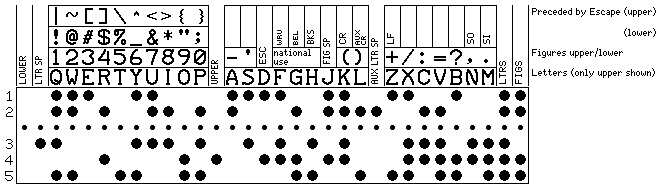
As this left room for a few additional printable characters in addition to a few additional control characters, I decided to put the three unassigned positions for printable characters back in the original national use positions, so that the most frequent accented letters for certain languages could be used efficiently.
As the upper-case escape code printable characters have been chosen to be ones much less frequently used than the lower-case escape code printable characters, it may well be preferable to make the lower-case set of characters that which prints in both upper and lower case, and to select the ones shown in upper case by a two-character escape sequence.
But there were now so many unassigned positions that an even more satisfactory way to resolve the issue was possible:
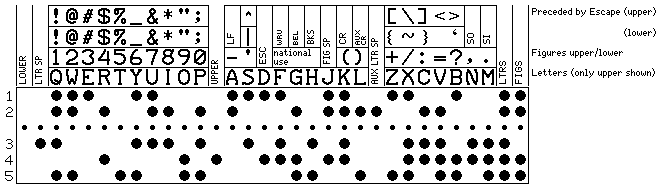
Here, while the most common printable characters reached by an ESC are case-independent, the ones that are very infrequent differ in upper and lower case. This still makes enough room for all the most necessary control characters, and enough room to retain the original national use code positions (which, again, as noted above, may be case dependent, so that both Ä, Ö, and Ü and ä, ö, and ü can be provided for German, for example). If a large number of additional control functions are needed, ESC ESC can always be used to prefix them.
Also, the reverse quote, which I left out of the previous diagram, is brought back; this meant that there wasn't still one unassigned control position, as I had originally hoped for when I began work on the diagram above; there is only one unassigned printable position. Perhaps the currency symbol for the Euro would be a good character to put there. Note, too, that it has been possible to preserve a vestige of ASCII ordering in these less frequent characters.
However, this version still left me unsatisfied.
The fundamental raison d'être of 5-level code is efficiency, and codes that require shifting in and out of lower case, or in and out of figures shift, detract from that.
Hence, after further thought, I went to this version:
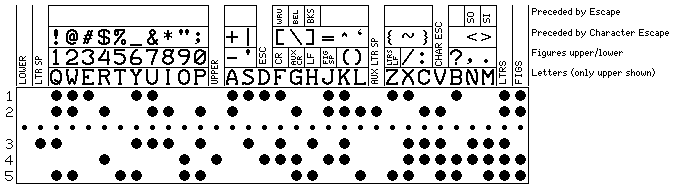
Here, some new control codes are added to those in figures shift which don't require ESC as a prefix.
One is a second prefix for additional printable characters, Character Escape, so that the full complement of necessary additional printable characters for the ASCII repertoire can be provided without the need to make them dependent on the status of the upper and lower-case shift. Again, one printable character position is left that can be used for the Euro symbol.
For national use, some of those characters can be replaced - and, particularly if the replacements are accented letters, they can be case-dependent. In that case, the need for upper and lower shifts isn't increased.
Another is the Letters Line Feed. Because, on a mechanical teleprinter, a carriage return takes more time than other printing functions, the sequence of characters for a new line is always CR LF, not the other way around. There are two carriage return characters, a primary and a secondary, which, as noted above, depending on the convention used in a given network, serve as reminders either of the upper-case versus lower-case status, or the shift-in versus shift-out status. Neither of these shift settings affect the line feed character, as it only needs to be in figures case, but it is still a line feed in upper or lower case, and in shift in or shift out state.
Adding Letters Line Feed now means that while a figures shift is needed prior to the CR LF sequence, replacing LF by LLF allows a letters shift following the CR LF sequence to be dispensed with.
It is envisaged that ESC ESC would be used for an additional 24 control characters, if needed, and similarly two CHAR ESC characters in a row could be used for an additional 24 printable characters.
In addition, ESC followed by CHAR ESC could indicate that the next two letters indicate one of 676 additional control characters, and CHAR ESC followed by ESC that the next two letters indicate one of 676 additional printable characters, thus providing ample room for future expansion.
The addition of the Letters Line Feed character brought to mind a point I had neglected to mention, but which was applicable to earlier iterations of the design.
If the primary and secondary letters space characters are used to confirm the upper-case/lower-case status, it is considered normal operation to use a primary letters space character after the (figures shift) period ending a sentence so that the next character will be an upper-case letter, and a secondary letter space character after a (figures shift) comma so that the next character after the space will be a lower-case letter, if such is the next desired character of the text to be transmitted.
Thus, although having multiple space characters and multiple carriage return characters which also change the shift state is primarily for the purpose of confirming the shift state, to mitigate the effects of a garbled transmission, it is also to be considered acceptable normal practice to use the changes in shift state these characters produce as a way to reduce the number of characters that need to be transmitted.
This means that for terminal equipment to ignore the changes in the shift state these characters cause as a way of reducing complexity and cost would be non-compliant, and not an admissible option.
This also suggested one more change, but that change, unfortunately, would require adding two more control characters to those in figures shift, and it appears to me that the number of printable characters there has already been reduced to the absolute bare minimum. Since the two versions of letters space may serve to confirm shift-in/shift-out state instead of upper-case/lower-case state, having two versions of letters space within figures case that always confirmed upper-case/lower-case state would ensure that the comma/period trick mentioned above could be done in either circumstance.
While it seemed that finding room for these additional characters would be difficult, further thought led to this:
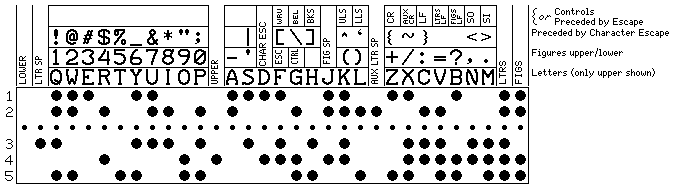
It combines a reasonably generous complement of printable characters in figures shift with a limited number of control characters.
The additional control characters now can be reached either with ESC as a prefix, or with CTRL to shift into a control state; the latter allows the two-character control sequence CR LF to get by with one shift character instead of two escape characters.
So among the controls, there is a plain line feed, a letters line feed, and a figures line feed. And the upper letters space and lower letters space are also added.
Since sequences of multiple control characters will be short, the fact that control is now a shift state, but nothing is used to confirm that shift state the way letters shift, shift-in versus shift-out, and upper-case versus lower-case, are confirmed within space and carriage return characters should not be an issue.