As noted in the page on data compression, text can be represented more efficiently using Huffman coding. Since text is composed of words having lengths in a relatively narrow range, separated from each other by single spaces, a multi-state Huffman code, with one set of symbols for word lengths, and another set of symbols for letters, can be used, and it has the added attraction of obscuring this aspect of the structure of a text document.
Even when it is not intended to perform explicit compression, codes representing characters for transmission can be designed for efficiency.
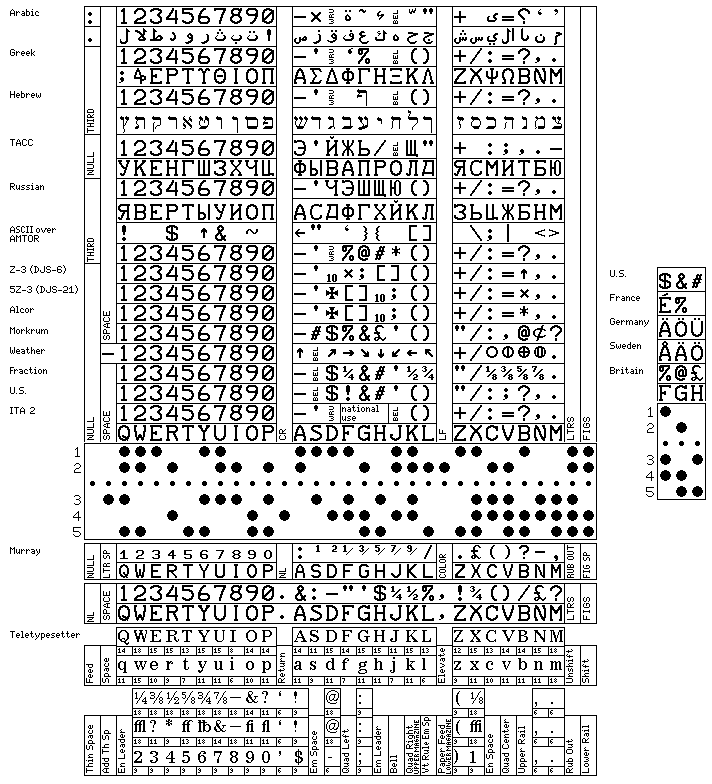
ITA 2, 5-level code, or the Murray code, generally known as Baudot, as it is based on his principle, even if it does not resemble his original code,
uses only five bits to represent a character, but sometimes extra characters are needed to shift between cases.
This chart illustrates FIELDATA, a character code briefly used for military purposes in the United States before being superseded by ASCII:
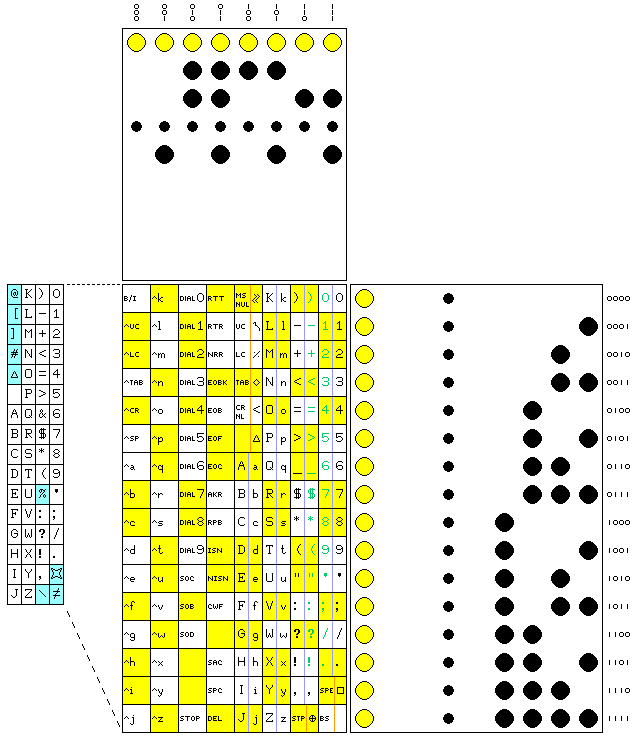
The holes shown in the paper tape represent the "paper tape pattern for control", while the order in which the columns of characters are arranged in the diagram represent instead the "basic pattern for control", wherein the second bit of the code, after the even parity bit, is zero for the first four columns and one for the last four columns.
The numerical bits in binary notation above and to the right of the illustrations of paper tape show the representations of the characters under the basic pattern for control.
This code has an unusual and interesting structure.
It has UC and LC control characters. However, instead of ( and ) being the upper-case equivalents of 9 and 0 respectively, they occupy related codepoints in an adjacent column. This allows the code to be used with the digits and special characters normally used without the need for recognizing the UC and LC characters, if the ability to handle lower-case characters is not required. Illustrating this situation, the diagram shows both upper- and lower- case letters in the code cells for the letters; in the code cells for special characters, the character is repeated, but the combination that should not occur if a conventional keyboard is used is shown in green.
Thus, while the code depicted here is a seven-bit code with two states, it lends itself to being adapted into a six-bit code with one state, and, indeed, a variant of FIELDATA of that form was long used with some Univac computers; this is shown on the left of the diagram, with character positions containing new symbols having a light blue-green background.
The control characters are:
B/I Blank/Idle SOC Start of Control Block SOB Start of Block SOD STOP RTT Ready to Transmit RTR Ready to Recieve NRR Not Ready to Receive EOBK End of Blockette EOB End of Block EOF End of File EOC End of Control Block AKR Acknowledge Receipt RPB Repeat Block ISN Interpret Sign NISN Non-Interpret Sign CWF Control Word Follows SAC SPC Special Character MS Master Space UC Upper Case LC Lower Case TAB Tabulate CR Carriage Return STP Stop SPE Special BS Back Space
In the original presentation of FIELDATA in a paper by W. F. Luebbert presented at the Fall 1959 Western Joint Computer Conference, the codes for ISN, NISN, and CWF were one larger than in the actual code used (as described, for example, in the manual from Philco for the BASICPAC computer); the unallocated code which preceded them was moved to the position following them.
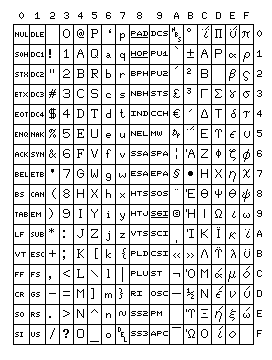
ASCII requires seven bits per character, and is simpler to use, since no shifts are required:
0 0 0 0 1 1 1 1
0 0 1 1 0 0 1 1
0 1 0 1 0 1 0 1
0000 NUL DLE 0 @ P ` p
0001 SOH DC1 ! 1 A Q a q
0010 STX DC2 " 2 B R b r
0011 ETX DC3 # 3 C S c s
0100 EOT DC4 $ 4 D T d t
0101 ENQ NAK % 5 E U e u
0110 ACK SYN & 6 F V f v
0111 BEL ETB ' 7 G W g w
1000 BS CAN ( 8 H X h x
1001 HT EM ) 9 I Y i y
1010 LF SUB * : J Z j z
1011 VT ESC + ; K [ k {
1100 FF FS , < L \ l |
1101 CR GS - = M ] m }
1110 SO RS . > N ^ n ~
1111 SI US / ? O _ o DEL Delete
But with seven bits per character, the temptation is strong to use a whole 8-bit byte for a character.
And here is a graphic representation of ASCII, illustrating the parity bit, if used, by placing characters with the parity bit active in odd parity against a yellow background:
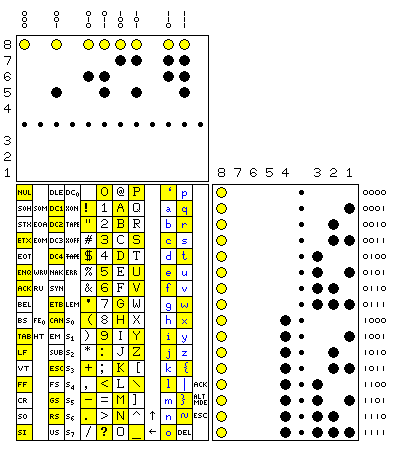
This diagram shows both the modern ASCII-67 code, which includes lower-case characters, and the previous ASCII-63 code, in which there were no lower-case characters, in which several control characters had different names, and in which a few of the printable characters with the highest codes were additional control characters instead.
Originally, there were many versions of 8-bit ASCII in use, providing extra characters on a number of computer systems. One common 8-bit ASCII character set found on printers was the one which supported the Japanese katakana syllabary (this was described in the standard JIS X 0201, and will be depicted below); the IBM PC, the Macintosh, and the Atari ST all had their own 8-bit character sets. Today, there is a standard; the Amiga was one of the first computers to use it.
Where the OE ligature was originally placed, the arithmetic symbols for multiplication and division were put in the middle of the accented letters, rather than with the new graphic symbols (this part of the standard was still undecided when the Amiga was designed, so those two characters were omitted from its character set; some printers have the original version as a "Unix character set"). The code used by the Amiga was the provisional version in which those two characters were undefined, because that question had not been settled yet.
In this standard, the extra characters consist of 32 additional control characters, followed by 95 printable characters, most of which are accented letters for the major European languages. Characters commonly found on typewriters, including a superscript 2 and 3 for use in typing measurements, but not a complete set of superscripts, are found.
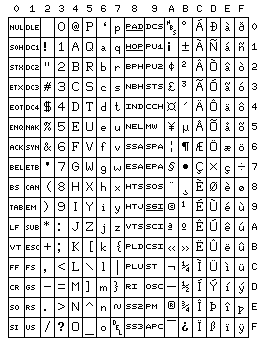
This 8-bit code, based on ASCII, is officially known as ISO 8859-1, and there are other 8-bit codes to serve languages which use characters not found in this code in the ISO 8859 family.
The internal code used with older versions of Microsoft Windows in their U.S. English language versions at least, known as Code Page 1252, was based on ISO 8859-1, but instead of having an additional 32 control characters, made use of those code positions for some useful printable characters not included in ISO 8859-1.
As with the 5-level code, some characters in 7-bit ASCII were available for national use. Or, to be precise, while ASCII itself did not include characters which could have alternate values, ASCII served as the basis for an international standard in which some ASCII characters were left unspecified. This modified version of ASCII was embodied in two essentially equivalent international standards, ISO 7 and ITA #5. The diagram below illustrates some of the available substitutions:
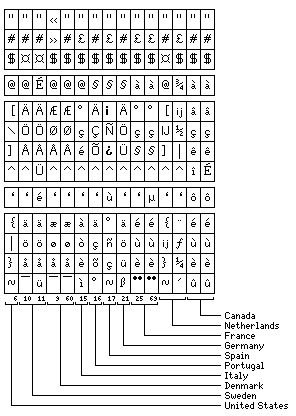
Note that the one for the Netherlands does not have a number; this version had not been registered, and none of the ISO 8859 series standards includes the Dutch IJ letter either.
The current 8-bit form of ASCII includes nearly all of the special characters shown here; however, other languages needed more additional characters, and thus there are also alternate forms of 8-bit ASCII for languages such as Greek and Russian.
One of the earliest forms of ASCII expanded to 8 bits, as mentioned above, was the one described by the Japanese standard JIS X 0201:

And another I'll depict here is ISO 8859-7, the Greek version of ASCII:
Many of the different national versions of ASCII were described and illustrated on Roman Czyborra's web page: this page has now been moved here.
While printers often have their own escape code sequences to switch between some of these character sets, today there are ambitious proposals to create a single code to encompass nearly all the world's languages.
There is the 16-bit Unicode character set, and the larger 31-bit ISO 10646 character set which includes it.
In the following sections, we will be examining a scheme for encoding a character set of potentially unlimited extent with reasonable efficiency, a scheme for encoding ISO 10646 characters which is highly compatible with normal ASCII, and ways in which the 5-level code has been, and could be, extended to handle a wider character repertoire.