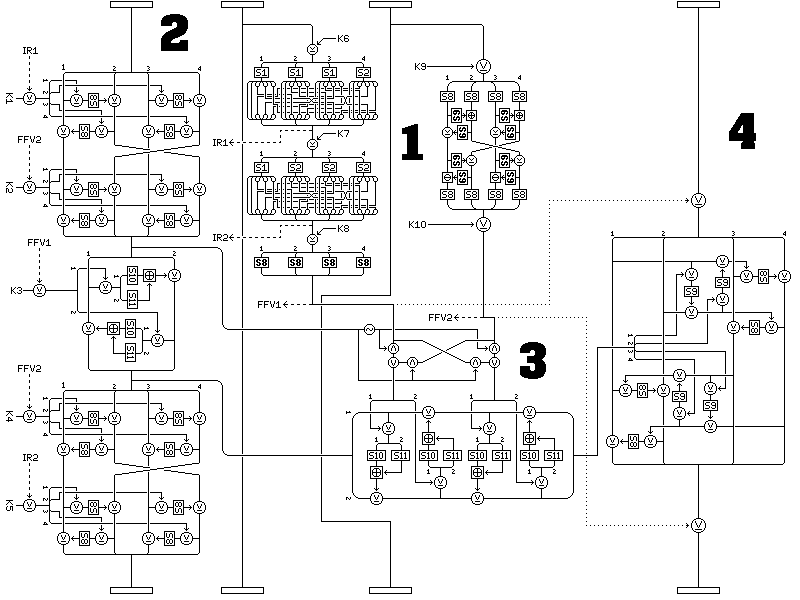
Quadibloc XI is a block cipher that has a design aimed at making differential and linear attacks extremely difficult. The Quadibloc XI round is illustrated in the diagram below:
Note that some connections shown by dotted and dashed lines in this diagram are not part of the basic Quadibloc XI round, but are added in variant forms of Quadibloc XI, to be described below. Also, the large numerals indicate an order in which the operations shown in the diagram can be performed. While the operations could be performed in left-to-right order for the basic Quadibloc XI round, the order indicated by the numerals is required if the modification indicated by the dashed lines is used; they are there to provide reassurance that the Quadibloc XI round remains invertible with that modification.
As Quadibloc XI is a design intended to provide very high security against possible future attacks, despite a speed penalty, the standard number of rounds recommended is 16. Since the first subblock is only transformed in isolation as a 32-bit entity, it is the fourth subblock that must be regarded as the one genuinely subjected to the full weight of the transformation provided by a given round. Given this, using 16 rounds (like DES, which changes half the block) instead of 32 rounds (like SKIPJACK, in which a quarter of the block is altered each round, plus another quarter in a simple way) may be regarded as optimistic. However, the rounds of Quadibloc XI are considerably more complicated.
After each round, except the last, the four subblocks are to be interchanged as follows:
From the order: 1 2 3 4 to the order: 3 1 4 2
Note that, as it is the first and fourth subblocks that are altered in each round, every subblock is altered every second round, and so the same subblock value is never used, in two rounds in a row, as an f-function input.
The Quadibloc XI round acts on the four 32-bit subblocks of the 128-bit block being enciphered, giving each subblock its own special role.
The first subblock is subjected to a series of three transformations of two different kinds, each controlled by round subkeys. Intermediate values between the first and second, and between the second and third, of these transformations are then used as inputs to the process of deriving a 32-bit value with which to modify the fourth subblock on the basis of the values of the second and third subblocks.
The second and third subblocks are not transformed, but are used as inputs to transformations, which again serve as f-functions. The two f-function outputs are first subjected to an ICE-style bit swap, under the control of one of the intermediate results from the first subblock. Then, the two results are used to provide subkey material for a four-round Feistel encipherment of the other intermediate result from the first subblock.
The result of this encipherment is then used to modify the fourth subblock. Instead of being XORed with it, it provides subkey material for Feistel encipherments of one half of that subblock, which produce subkey material for the actual Feistel encipherment of the other half of the subblock. This indirection further complicates cryptanalysis. Note the use of both S8 and S9 in this transformation. Also, it can be shown that, since S8 and S9 are both bijective, this complicated transformation is in fact a Latin square on its two inputs, and so it is not inferior as a combiner to a simple XOR.
The Quadibloc XI round begins by subjecting the leftmost subblock to a series of three transformations. After each of the first two transformations, the value of the modified result is used as an intermediate result in the processing of the remaining subblocks.
In the first transformation, numbering the bytes from 1 to 4 from left to right, the following sequence of steps is performed twice, using the first and second subkeys for the round as the subkey for the operation:
Thus, the block is divided into two halves; each half is subjected to two Feistel rounds in place, and the input to the f-function comes first from the byte on the left, and then in the second round from the byte on the right. The key-dependent S-box provides the f-function.
Bytes 2 and 4 of the block are interchanged between the two performances of this sequence of steps with the two subkeys used.
In the second transformation, the 32-bit block is split into two 16-bit halves. Two Feistel rounds take place, with the left half initially supplying the input to the f-function. The f-function begins with the input being XORed to 16 bits of subkey (the left half in the first round, the right half in the second, of the third 32-bit subkey for the round); then, the left half of the result is used to index into key-dependent S-box S10, and the right half of the result is used to index into key-dependent S-box S11. The two items found are then added by modulo-65536 addition (with the left byte considered as the most significant), and the result is the f-function output. The round is completed by modifying the target half of the block by XORing it with the f-function output.
The two Feistel rounds are performed in place; instead of the halves being swapped, for the second round, the right half supplies the input to the f-function.
The third transformation is performed using the same steps as the first transformation, except that it uses the fourth and fifth subkeys for the current round.
The next step in a Quadibloc XI round is to use the second and third subblocks, which are not modified by the round, as inputs to two f-functions.
The second subblock is used as input to the usual Quadibloc f-function, as used in Quadibloc II and several later ciphers of this series.
It is a keyed substitution/permutation network, and it uses a permutation that we will call P, although it differs from the permutation P of DES, being, unlike that permutation, symmetrical, which is as follows:
The bits 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 become 1 2 27 28 21 22 15 16 9 10 3 4 29 30 23 24 17 18 11 12 5 6 31 32 25 26 19 20 13 14 7 8
and this permutation is to be interpreted according to the following convention: the numbers in the bottom sequence identify the source of each bit in the permuted result in order.
The f-function taking the second subblock as input proceeds as follows:
The third subblock is used as input to an f-function with a different structure. Except for the fact that it uses the key-dependent S-box S8 in the direct line of encipherment, thus requiring extra RAM if used to modify a subblock, it could easily have been used as a transformation of the subblock instead of an f-function, such as those used with the first subblock.
This operation on a 32-bit value proceeds as follows:
The two f-function outputs are now subjected to a bit swap, in the fashion pioneered by the block cipher ICE.
Every bit in these two f-function outputs that corresponds to a bit in the first intermediate result which is a 1 is exchanged with its corresponding bit in the other f-function output. The diagram shows a method of using basic logical operations to achieve this result.
The 64 bit value resulting from this bit swap is then used as the source of four 16-bit round subkeys for four Feistel rounds of the same type as the two Feistel rounds used in the second transformation applied to the first subblock. The leftmost half of the first f-function output after swapping is used as the subkey for the first round, in which it is XORed with the leftmost half of the second 32-bit intermediate result to produce the 16-bit value which provides two 8-byte indexes into S10 and S11, the modulo-65536 sum of the two entries thus found being XORed with the rightmost half of the second 32-bit intermediate result. The remaining rounds alternate in which halves of that intermediate result they operate on, and use succeeding halves from the two f-function outputs as subkeys.
Finally, the 32-bit result of the encipherment of the second intermediate result is used as input to a transformation applied to the fourth subblock.
This transformation consists of two rounds.
In each round, one half of the subblock is used as input to two Feistel rounds, keyed by the input to be combined with the value being modified. The output of those Feistel rounds is then used to supply subkey input to two more Feistel rounds of the same type which modify the other half of the subblock. Thus, the input functions as a subkey in a cipher that produces a subkey. However, because there are only two rounds in each step, if the S-box contents were known, this structure would not provide protection against calculating the subkey input to it.
The first round proceeds as follows:
In the second round, bytes 3, 4, 1 and 2 serve the same functions as bytes 1, 2, 3, and 4 respectively did in the first round, and the third and fourth bytes of the input perform the same function as the first and second bytes of the input performed in the first round. The rounds are performed in place, so there is no interchange of bytes to move them into the positions of the bytes whose roles they now perform.
Perhaps the description of the cipher might be clearer if I provide pseudocode for it.
for round = 1 to 16
subkey_base = (round - 1) * 10
// Calculate first f-function, from second subblock
ffun1 = subblock(2) xor subkey( subkey_base + 6 )
ffun1 = ( S1( byte_of(ffun1,0) ),
S1( byte_of(ffun1,1) ),
S1( byte_of(ffun1,2) ),
S2( byte_of(ffun1,3) ) )
ffun1 = bits_from( ffun1,
0, 1, 26, 27, 20, 21, 14, 15,
8, 9, 2, 3, 28, 29, 22, 23,
16, 17, 10, 11, 4, 5, 30, 31,
24, 25, 18, 19, 12, 13, 6, 7 )
ffun1 = ffun1 xor subkey( subkey_base + 7 )
ffun1 = ( S1( byte_of(ffun1,0) ),
S2( byte_of(ffun1,1) ),
S2( byte_of(ffun1,2) ),
S2( byte_of(ffun1,3) ) )
ffun1 = bits_from( ffun1,
0, 1, 26, 27, 20, 21, 14, 15,
8, 9, 2, 3, 28, 29, 22, 23,
16, 17, 10, 11, 4, 5, 30, 31,
24, 25, 18, 19, 12, 13, 6, 7 )
ffun1 = ffun1 xor subkey( subkey_base + 8 )
ffun1 = ( S8( byte_of(ffun1,0) ),
S8( byte_of(ffun1,1) ),
S8( byte_of(ffun1,2) ),
S8( byte_of(ffun1,3) ) )
// Calculate second f-function, from third subblock
ffun2 = subblock(3) xor subkey( subkey_base + 9 )
b1 = S8( byte_of(ffun2,0) )
b2 = S8( byte_of(ffun2,1) )
b3 = S8( byte_of(ffun2,2) )
b4 = S8( byte_of(ffun2,3) )
b2 = b2 + S9( b1 ) [ mod 256 ]
b1 = b1 xor S9( b2 )
b4 = b4 + S9( b3 ) [ mod 256 ]
b3 = b3 xor S9( b4 )
swap b2, b4
b2 = b2 xor S9( b1 )
b1 = b1 - S9( b2 ) [ mod 256 ]
b4 = b4 xor S9( b3 )
b3 = b3 - S9( b4 ) [ mod 256 ]
ffun2 = ( S8( b1 ), S8( b2 ), S8( b3 ), S8( b4 ) )
ffun2 = ffun2 xor subkey( subkey_base + 10 )
// First step in modifying first subblock
b1 = byte_of( subblock(1), 0 )
b2 = byte_of( subblock(1), 1 )
b3 = byte_of( subblock(1), 2 )
b4 = byte_of( subblock(1), 3 )
sb1 = byte_of( subkey( subkey_base + 1 ), 0 )
sb2 = byte_of( subkey( subkey_base + 1 ), 1 )
sb3 = byte_of( subkey( subkey_base + 1 ), 2 )
sb4 = byte_of( subkey( subkey_base + 1 ), 3 )
b2 = b2 xor S8( b1 xor sb1 )
b4 = b4 xor S8( b3 xor sb2 )
b1 = b1 xor S8( b2 xor sb3 )
b3 = b3 xor S8( b4 xor sb4 )
sb1 = byte_of( subkey( subkey_base + 2 ), 0 )
sb2 = byte_of( subkey( subkey_base + 2 ), 1 )
sb3 = byte_of( subkey( subkey_base + 2 ), 2 )
sb4 = byte_of( subkey( subkey_base + 2 ), 3 )
b2 = b2 xor S8( b1 xor sb1 )
b4 = b4 xor S8( b3 xor sb2 )
b1 = b1 xor S8( b2 xor sb3 )
b3 = b3 xor S8( b4 xor sb4 )
subblock_value = ( b1, b2, b3, b4 )
swap_control = subblock_value
// Second step in modifying first subblock
h1 = halfword_of( subblock_value, 0 )
h2 = halfword_of( subblock_value, 1 )
sh1 = halfword_of( subkey( subkey_base + 3 ), 0 )
sh2 = halfword_of( subkey( subkey_base + 3 ), 1 )
f = h1 xor sh1
h2 = h2 xor ( S10( byte_of( f, 0 ) ) + S11( byte_of( f, 1 ) ) [ mod 65536 ]
f = h2 xor sh2
h1 = h1 xor ( S10( byte_of( f, 0 ) ) + S11( byte_of( f, 1 ) ) [ mod 65536 ]
subblock_value = ( h1, h2 )
round_input = subblock_value
// Third step in modifying first subblock
b1 = byte_of( subblock_value, 0 )
b2 = byte_of( subblock_value, 1 )
b3 = byte_of( subblock_value, 2 )
b4 = byte_of( subblock_value, 3 )
sb1 = byte_of( subkey( subkey_base + 4 ), 0 )
sb2 = byte_of( subkey( subkey_base + 4 ), 1 )
sb3 = byte_of( subkey( subkey_base + 4 ), 2 )
sb4 = byte_of( subkey( subkey_base + 4 ), 3 )
b2 = b2 xor S8( b1 xor sb1 )
b4 = b4 xor S8( b3 xor sb2 )
b1 = b1 xor S8( b2 xor sb3 )
b3 = b3 xor S8( b4 xor sb4 )
sb1 = byte_of( subkey( subkey_base + 5 ), 0 )
sb2 = byte_of( subkey( subkey_base + 5 ), 1 )
sb3 = byte_of( subkey( subkey_base + 5 ), 2 )
sb4 = byte_of( subkey( subkey_base + 5 ), 3 )
b2 = b2 xor S8( b1 xor sb1 )
b4 = b4 xor S8( b3 xor sb2 )
b1 = b1 xor S8( b2 xor sb3 )
b3 = b3 xor S8( b4 xor sb4 )
subblock_value = ( b1, b2, b3, b4 )
subblock(1) = subblock_value
// Produce subkeys for enciphering round_input to modify
// the fourth subblock
// The intent of this code is to swap those bits of the
// two f-function outputs that correspond to 1 bits in
// the variable swap_control
internal_subkey_1 = ffun1 and ( not swap_control )
internal_subkey_2 = ffun2 and ( not swap_control )
internal_subkey_1 = internal_subkey_1 or ( ffun2 and swap_control )
internal_subkey_2 = internal_subkey_2 or ( ffun1 and swap_control )
// Produce the value used to modify the fourth subblock
h1 = halfword_of( round_input, 0 )
h2 = halfword_of( round_input, 1 )
sh1 = halfword_of( internal_subkey_1, 0 )
sh2 = halfword_of( internal_subkey_1, 1 )
f = h1 xor sh1
h2 = h2 xor ( S10( byte_of( f, 0 ) ) + S11( byte_of( f, 1 ) ) [ mod 65536 ]
f = h2 xor sh2
h1 = h1 xor ( S10( byte_of( f, 0 ) ) + S11( byte_of( f, 1 ) ) [ mod 65536 ]
sh1 = halfword_of( internal_subkey_2, 0 )
sh2 = halfword_of( internal_subkey_2, 1 )
f = h1 xor sh1
h2 = h2 xor ( S10( byte_of( f, 0 ) ) + S11( byte_of( f, 1 ) ) [ mod 65536 ]
f = h2 xor sh2
h1 = h1 xor ( S10( byte_of( f, 0 ) ) + S11( byte_of( f, 1 ) ) [ mod 65536 ]
combiner_input = ( h1, h2 )
// Modify the fourth subblock
b1 = byte_of( subblock(4), 0 )
b2 = byte_of( subblock(4), 1 )
b3 = byte_of( subblock(4), 2 )
b4 = byte_of( subblock(4), 3 )
sb1 = byte_of( combiner_input, 0 )
sb2 = byte_of( combiner_input, 1 )
sb3 = byte_of( combiner_input, 2 )
sb4 = byte_of( combiner_input, 3 )
t2 = b2 xor S9( b1 xor sb1 )
t1 = b1 xor S9( t2 xor sb2 )
b4 = b4 xor S8( b3 xor t1 )
b3 = b3 xor S8( b4 xor t2 )
t4 = b4 xor S9( b3 xor sb3 )
t3 = b3 xor S9( t4 xor sb4 )
b2 = b2 xor S8( b1 xor t3 )
b1 = b1 xor S8( b3 xor t4 )
subblock(4) = ( b1, b2, b3, b4 )
// Swap subblocks
if round < 16 then
{ for i = 1 to 4
temp(i) = subblock(i)
next i
subblock(1) = temp(3)
subblock(2) = temp(1)
subblock(3) = temp(4)
subblock(4) = temp(2)
}
next round
While I hesitate to burden visitors to this web page with the bandwidth cost, the following diagram may be of use to some in illustrating how the inverse round (in this case, the last round of decipherment, since the subkeys used in the first round of encipherment are shown) works:
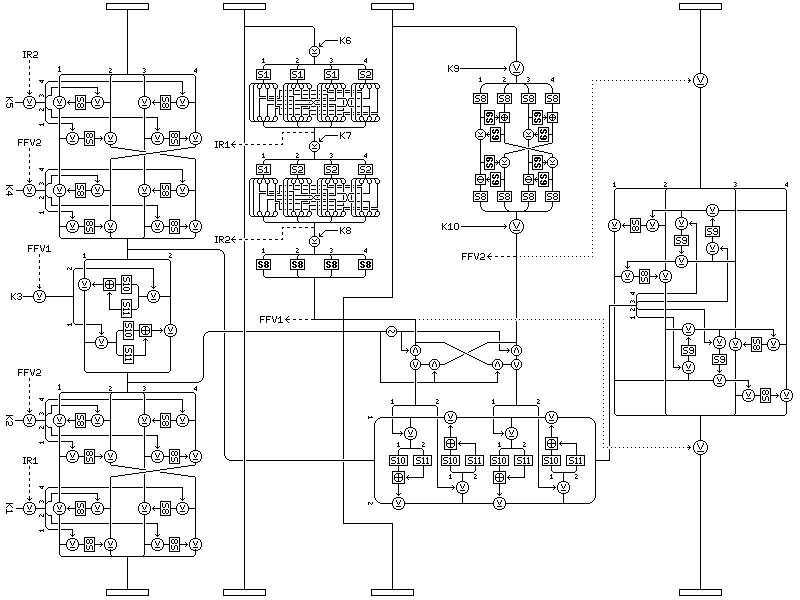
And don't forget to invert the order in which you rotate your subblocks between rounds:
From the order: 1 2 3 4 to the order: 2 4 1 3
Quadibloc XI uses the following key material: 10 subkeys, each 32 bits long, per round, and two key-dependent S-boxes, S8 and S9, containing the bytes from 0 to 255 in a shuffled order, and two key-dependent S-boxes, S10 and S11, each containing 256 16-bit entries, not otherwise constrained. The subkeys used by the first round are K1 through K15, as shown in the diagram, and those used by the second round are K16 through K30, and so on.
The key will be a multiple of four bytes in length, and must be at least eight bytes in length.
Subkey generation proceeds as follows:
Three strings of bytes of different length are produced from the key.
The first string consists of the key, followed by one byte containing the one's complement of the XOR of all the bytes of the key.
The second string consists of the one's complements of the bytes of the key in reverse order, with three bytes appended containing the following three quantities:
The third string consists of alternating bytes, taken from the bytes of the key in reverse order, and then from the bytes of the one's complement of the key, and then that string is followed by the one's complements of the first four bytes of the key.
Thus, if the key is:
128 64 32 16 8 4 2 1 1 2 3 4 5 6 7 8
then the strings generated from it are as follows:
First string: 128 64 32 16 8 4 2 1 1 2 3 4 5 6 7 8 8 Second string: 247 248 249 250 251 252 253 254 254 253 251 247 239 223 191 127 37 170 93 Third string: 8 127 7 191 6 223 5 239 4 247 3 251 2 253 1 254 1 254 2 253 4 252 8 251 16 250 32 249 64 248 128 247 127 191 223 239
Given that the length of the key is 4n, the lengths of the three strings are 4n+1, 4n+3, and 8n+4, and hence all three are relatively prime, since both 4n+1 and 4n+3 are odd, and 8n+4 is two times 4n+2.
Two buffers, each containing room for 256 bytes, are filled by generating bytes from the first and second strings by placing them in a nonlinear shift register.
The form of that shift register is shown in the following illustration, showing its precise form for the first string.
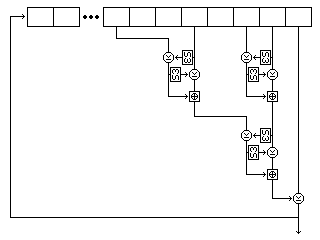
Five bytes are read from the string at each step. For the first string, they are, as shown in the diagram, the eighth-last, fifth-last, third-last, and second-last bytes and the last byte. For the second string, they are the eighth-last, seventh-last, fourth-last, and second-last bytes, and the last byte. For the third string, they are the twelfth-last, tenth-last, seventh-last, and fourth-last bytes, and the last byte.
Each time the shift register produces a byte, it does so as follows:
Both buffers contain 256 bytes. The first buffer, called buffer A, is filled with 256 successive bytes generated from the second string by means of the nonlinear shift register filled with the second string. The second buffer, called buffer B, is filled with 256 successive bytes generated from the first string by means of the nonlinear shift register filled with the first string.
Once the setup is complete, subkey material is generated one byte at a time, the first byte generated being the leftmost byte of subkey K1, and so on.
A subkey byte is generated as follows:
The following diagram attempts to illustrate the complete process of subkey byte generation:
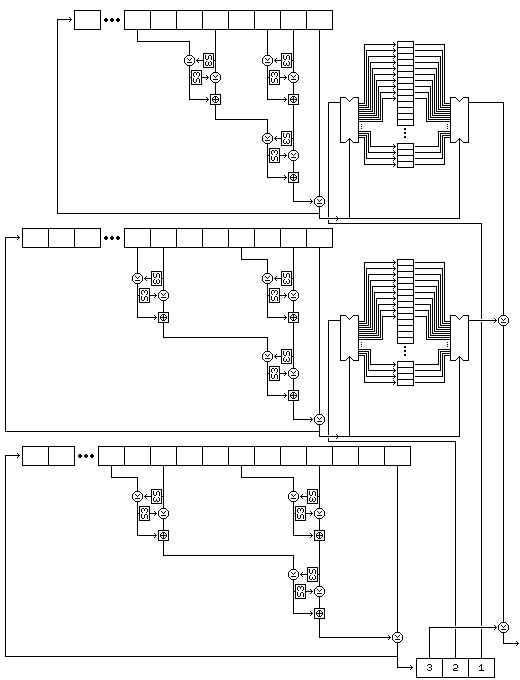
Note that this procedure, since it exercises the two strings used to select bytes, rather than the string used to generate values, results in a small change in the key resulting in large changes in the subkeys from the very beginning.
If we compare the generator as it operates with two keys differing only slightly, note that the first two shift registers have been exercised, but the third has not, since the key was loaded, and that the two buffers were loaded from the first two shift registers in the beginning. Thus, there will be considerable overlap between the contents of those two buffers and the output of the third shift register at the start for two similar keys. Because the first two shift registers will be thoroughly mixed, however, they will select different bits from the two buffers to be XORed into the output byte. Thus, usually a small change will make the output completely different. However, if the first two shift registers point to the same buffer bytes in both cases by coincidence, (or later on, to buffer bytes filled with the same values in the sequence from the third shift register, a second opportunity for this) which has a one in 65,536 probability, then the output bytes will be significantly more likely to have the same value. Hence, for similar keys, there will be a whisper of correlation in the subkey bytes generated; the generator is not absolutely perfect, but it is quite good.
Once all the required 32-bit subkey words are generated, the key-dependent S-boxes S8 and S9 must be generated. To generate each bijective S-box, the following procedure is used:
The resulting contents of buffer D are used as the key-dependent bijective S-box intended to be produced. Note that this is a procedure, introduced for Quadibloc X, is more straightforwards than the other two basic procedures used previously to produce S8 in other ciphers in this series.
This procedure, although it uses buffers A and B, leaves them undisturbed; thus, byte generation may continue after one S-box is produced.
After the 32-bit subkeys have been produced, the sequence of events is as follows:
S-box S8 is produced using the procedure outlined above.
S-box S10 is generated merely by generating output bytes, in the same manner as for the 32-bit subkeys, to produce its 256 16-bit entries. The first byte generated is the first and most significant byte of entry 0, the second byte the second and least significant byte of entry 0, the third byte the most significant byte of entry 1, and so on.
S-box S9 is produced using the procedure outlined above to produce a bijective S-box with 256 8-bit entries.
S-box S11 is generated by the same process as used to produce S10.
Again, if it will make things clearer, here is pseudocode for the subkey generation procedure. It calls five routines, run_shift_register_1, run_shift_register_2, run_shift_register_3, generate_byte, and make_permutation.
global n, register1, register2, register3
global a_array, b_array
n = length( key )
for i = 0 to n-1
key_byte( i+1 ) = byte_of( key, i )
next i
// Initialize shift registers from key
accum = 0
for i = 1 to n
register1( i ) = key_byte( i )
accum = accum xor key_byte( i )
next i
register1( n + 1 ) = not accum
accum = 0
accum1 = 0
accum2 = 0
for i = 1 to n
register2( n + 1 - i ) = not key_byte(i)
accum = accum + key_byte(i) [ mod 255 ]
if odd(i) then
{ accum1 = accum1 xor key_byte(i)
}
else
{ accum2 = accum2 xor key_byte(i)
}
next i
register2( n + 1 ) = accum + 1
register2( n + 2 ) = accum1
register2( n + 3 ) = not accum2
for i = 1 to n
register3( 2 * n - 1 ) = key_byte( n + 1 - i )
register3( 2 * n ) = not key_byte( i )
next i
for i = 1 to 4
register3( n + i ) = not key_byte( i )
next i
// Initialize a_array and b_array
for i = 1 to 256
a_array( i - 1 ) = run_shift_register_2
next i
for i = 1 to 256
b_array( i - 1 ) = run_shift_register_1
next i
// Generate subkeys
for i = 1 to 160
b1 = generate_byte
b2 = generate_byte
b3 = generate_byte
b4 = generate_byte
subkey( i ) = ( b1, b2, b3, b4 )
next i
make_permutation( S8 )
for i = 0 to 255
b1 = generate_byte
b2 = generate_byte
S10( i ) = ( b1, b2 )
next i
make_permutation( S9 )
for i = 0 to 255
b1 = generate_byte
b2 = generate_byte
S11( i ) = ( b1, b2 )
next i
Here is the pseudocode for run_shift_register_1:
b1 = register1( n - 6 ) b2 = register1( n - 3 ) b3 = register1( n - 1 ) b4 = register1( n ) b1 = b1 xor S3( b2 ) b2 = b2 xor S3( b1 ) b2 = b2 + b1 [ mod 256 ] b3 = b3 xor S3( b4 ) b4 = b4 xor S3( b3 ) b4 = b4 + b3 [ mod 256 ] b2 = b2 xor S3( b4 ) b4 = b4 xor S3( b2 ) b4 = b4 + b2 [ mod 256 ] result = b4 xor register1( n + 1 ) for i = n + 1 to 2 step -1 register1( i ) = register1( i - 1 ) next i register1( 1 ) = result return result
Here is the pseudocode for run_shift_register_2:
b1 = register2( n - 4 ) b2 = register2( n - 3 ) b3 = register2( n ) b4 = register2( n + 2 ) b1 = b1 xor S3( b2 ) b2 = b2 xor S3( b1 ) b2 = b2 + b1 [ mod 256 ] b3 = b3 xor S3( b4 ) b4 = b4 xor S3( b3 ) b4 = b4 + b3 [ mod 256 ] b2 = b2 xor S3( b4 ) b4 = b4 xor S3( b2 ) b4 = b4 + b2 [ mod 256 ] result = b4 xor register2( n + 3 ) for i = n + 3 to 2 step -1 register2( i ) = register2( i - 1 ) next i register2( 1 ) = result return result
Here is the pseudocode for run_shift_register_3:
b1 = register3( 2 * n - 7 ) b2 = register3( 2 * n - 5 ) b3 = register3( 2 * n - 2 ) b4 = register3( 2 * n + 1 ) b1 = b1 xor S3( b2 ) b2 = b2 xor S3( b1 ) b2 = b2 + b1 [ mod 256 ] b3 = b3 xor S3( b4 ) b4 = b4 xor S3( b3 ) b4 = b4 + b3 [ mod 256 ] b2 = b2 xor S3( b4 ) b4 = b4 xor S3( b2 ) b4 = b4 + b2 [ mod 256 ] result = b4 xor register3( 2 * n + 4 ) for i = 2 * n + 4 to 2 step -1 register3( i ) = register3( i - 1 ) next i register3( 1 ) = result return result
And here is the pseudocode for generate_byte:
x1 = run_shift_register_3 x2 = run_shift_register_3 t3 = run_shift_register_3 p1 = run_shift_register_1 p2 = run_shift_register_2 t1 = a_array( p1 ) t2 = b_array( p2 ) a_array( p1 ) = x1 b_array( p2 ) = x2 return t1 xor t2 xor t3
And here is the pseudocode for make_permutation:
subroutine make_permutation( array )
for i = 0 to 255
c_array( i ) = generate_byte
array( i ) = i
next i
for i = 0 to 255
if ( c_array( i ) != i ) then
{ swap array( i ), array( c_array( i ) )
}
next i
for i = 0 to 255
if ( b_array( i ) != i ) then
{ swap array( i ), array( c_array( i ) )
}
next i
for i = 0 to 255
if ( a_array( i ) != i ) then
{ swap array( i ), array( c_array( i ) )
}
next i
As this cipher is highly secure against conventional attacks, it might be considered using it with only eight rounds, despite the fact that really only one quarter of the block is securely encrypted at each round (another quarter is encrypted, but with a cipher acting on a pure 32-bit block).
As it is possible to work backwards from the combiner which applies a 32-bit input to the fourth subblock, because each byte of that subblock is modified only once, to that input, to allow the cipher to be used with only four rounds, or to make it more secure with eight, the dotted lines in the diagram illustrate a possible modification: the f-function outputs generated from the second and third subblocks, in addition to being subjected to a bit swap, and used as subkeys for the Feistel rounds which produce that 32-bit input, are also directly XORed to the fourth subblock, the one from the second subblock before, and the one from the third subblock after, the combiner.
This variant can be referred to as Quadibloc XI EM. (Extended Modification)
The dashed lines in the diagram indicate an additional possible modification, which also constitutes a departure from the purity of the original Quadibloc XI design in order to increase the apparent strength of each individual round (and thus edge towards a design more like Quadibloc X, but still not going as far; the middle two subblocks are still unmodified in each round). The outputs of the f-functions resulting from the second and third subblocks, and the two intermediate results of the f-function of the second subblock, are used to XOR with the five subkeys controlling encipherment of the first subblock, so that it is no longer merely subjected to a fixed transformation applied only to a 32-bit value.
Specifically, before being used in the modification of the first subblock, the first five subkeys for the round are modified as follows:
Using rounds including both this modification, and the one indicated by dotted lines as well, creates Quadibloc XI HD. (Heightened Dependence)
Except for the one standard Quadibloc f-function, using fixed S-boxes S1 and S2, the whole cipher is entirely built on four key-dependent S-boxes. These S-boxes are generated in a fashion that makes their contents completely arbitrary; this makes it more difficult to attack them in some ways than a method of generation that limits their possible contents, but it also means that they could have, for a particular key, poor differential characteristics.
Thus, I propose the following variant form of Quadibloc XI to address this concern:
In rounds 1 through 4, and rounds 13 through 16, whenever S8 is called for in the design, use instead S-box S4 from the standard Quadibloc set generated from Euler's constant, and whenever S9 is called for in the design, use instead S-box S5 from the standard Quadibloc set generated from Euler's constant, with the following two exceptions: in the f-function using the second subblock as input, retain S8 in the final layer, since S1 and S2 are already used, and in the f-function using the third subblock as input, retain S9 (but do replace S8 by S4). The places where S-boxes S8 and S9 are not replaced have their names shown in bold in the diagram.
This variant can be referred to as Quadibloc XI FB. (Fixed Box)
Quadibloc XI M (Mixed) is a sixteen-round variant with the following structure: the S-boxes for each of the sixteen rounds are as in Quadibloc XI FB. Rounds 5 through 12 include the dotted-line modification, as in Quadibloc XI EM. Rounds 1 through 4, and rounds 13 through 16, in addition to using S-boxes S4 and S5, also include the dashed-line modification from Quadibloc XI HD, but unlike it, do not include the dotted-line modification.
Quadibloc XI SL (Safe Limited) is Quadibloc XI HD, but with the S-boxes changed as in the outer rounds of Quadibloc XI FB as well. Can this variant be used with as few as four rounds? Given the slowness and complexity of each round of the cipher, that would be desirable, but given the boomerang attack, it would only be secure if one of the two transformations which alter the subblocks was completely immune to a differential attack. Thus, even with the more elaborate variations, it appears that eight rounds is the absolute minimum that can be recommended.
Since the S-boxes S8 and S9 are arbitrary permutations, they might be linear; in the worst case, they could contain the identity permutation. Since the S-boxes S10 and S11 contain arbitrary data, they might even be biased; in the worst case, they could contain all zeroes.
Were the extremely unlikely event of S10 and S11 being all zeroes to come to pass, a large segment of the round would become irrelevant; in the basic Quadibloc XI round, the two f-function results from the second and third subblocks would become irrelevant. If, in addition, S8 and S9 contained the identity permutation, the cipher would become a mere linear combination of the subkeys with the block, because the one guaranteed nonlinear part of the cipher, the f-function of the second subblock, would not be used.
This could be seen as an argument for using either the dotted-line or dashed-line modifications, or using the fixed-box variant. But the modifications have the drawback of exposing inner parts of the round.
A modification of the basic round structure:
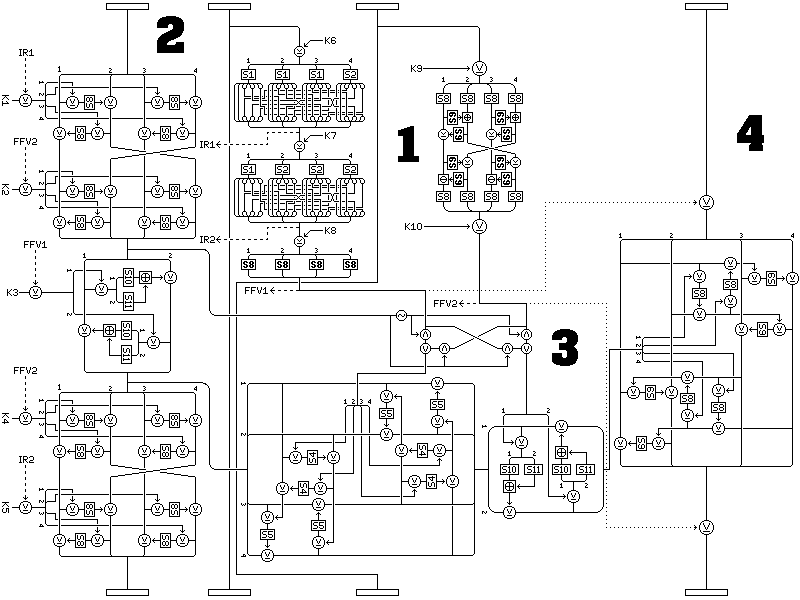
where the first two rounds of the Feistel structure using the bit-swap output are replaced by a combiner like that used with the fourth subblock; where the combiner in that position uses S-boxes S4 and S5 in all variants, and where in addition S8 and S9 are reversed in positions in the combiner for the fourth subblock, addresses the worst-case scenario, by ensuring the output from the standard Quadibloc f-function, except where the bit-swapping intermediate result is all ones, always has an influence on the encipherment.
Even with the default variation, and S8 and S9 being linear, while the final combiner may reduce to something little better than a simple XOR, we are now assured that the value applied by it is produced by a method having significance.
Of course, S10 and S11 being filled with zeroes is unlikely, but they could contain a slight bias, and this combined with a partial linearity in S8 and S9 could result in some weakness, which this modified round structure would reduce. As well, it adds yet another level of indirection to the round. Note that all the other variant forms of the cipher may still be applied to this modified round. Thus, in addition to Quadibloc XI with only this modification, which can be called Quadibloc XI WR (Weak key Resistant) we have Quadibloc XI WR EM, WR HD, WR FB, WR M, and WR SL.
The fact that it is possible to work back from the combiner to its inputs, however, suggests another modification to the Quadibloc XI round of a completely different kind.
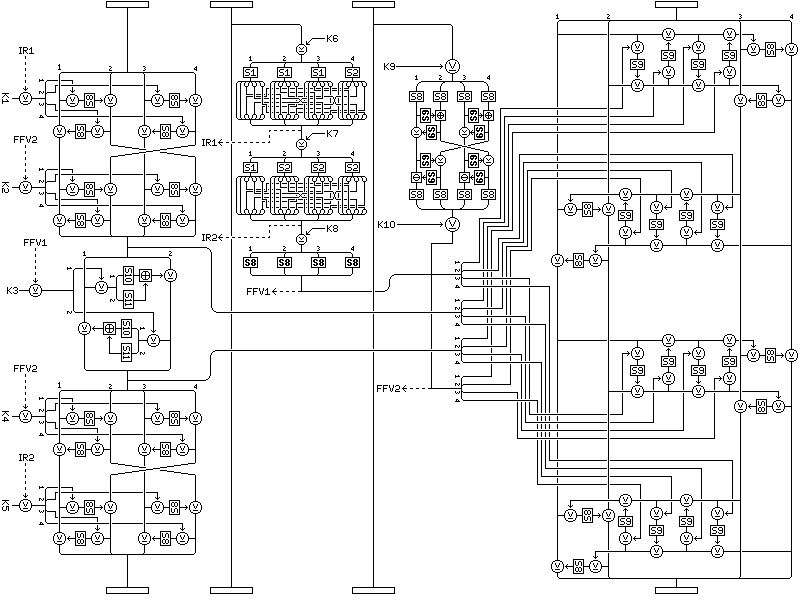
For obvious reasons, the dotted line modification is no longer applicable to the round, but everything else stays the same in terms of the available options and how the round can be employed. Here, instead of using the two f-function outputs, and the two intermediate values of the first subblock, to produce a value to combine with the fourth subblock in a complicated way, all four inputs are combined with the fourth subblock.
This leads to four, rather than two, Feistel rounds taking place in each direction. The four input values are split up, so that one byte from each is used in the inner Feistel rounds, and the four sources are always used in the same order.
Normal Quadibloc XI with this round type employed can be termed Quadibloc XI D (Double); with the dashed-line modification only, we obtain Quadibloc XI D HD; and of course Quadibloc XI D FB is also possible. Quadibloc XI MX (Mixed Extended) will designate a version of Quadibloc XI M in which the middle eight rounds, instead of having the dotted line modification, are of this round type, while the outer rounds use the fixed S-boxes, and have the dashed line modification but not the dotted line modification, as in regular Quadibloc XI M. And Quadibloc XI WR MX would use the Quadibloc XI WR type of outer round (with the dashed-line modification added).
Of course, although one has to stop somewhere, this naturally suggests somehow retaining the part omitted from the original Quadibloc XI round in addition to the doubled-up combiner. One way this could be done is illustrated below:
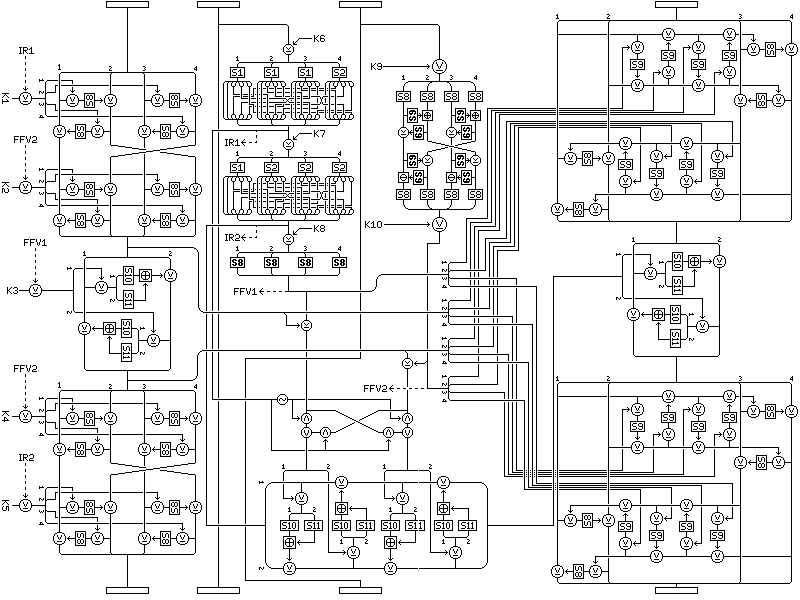
To avoid using the same values twice, now the two intermediate results from the f-function of the second subblock are brought into play, the second one as the round input, and the first as the swap control value. The two inputs to the swap are the XORs of the f-function outputs and the first subblock intermediate values. To ensure variety in the operations applied to the fourth subblock, two rounds using S10 and S11 are used as the combiner to apply the complex function output to that subblock.
This version can be termed Quadibloc XI C (Compound), and of course Quadibloc XI C HD and Quadibloc XI C FB are again also possible as with Quadibloc XI D.
Next
Start of Section
Skip to Next Section
Skip to Next Chapter
Table of Contents
Main Page