
As I have noted, today RISC architectures are very popular, despite not following some of the original ideas that formed part of the original definition of RISC (such as having all instructions execute in a single cycle) because they lend themselves to efficient implementations.
The defining characteristics of RISC that have persisted are:
The first of these characteristics makes instruction decoding faster and more efficient. (And it ties in with the third characteristic, by forcing regster-to-register instructions to be larger in size.)
The second of these characteristics encourages programs to be written so that data can be retrieved from memory well ahead of the time when the other operand for the first calculation involving that data has itself been calculated and is thus available.
The third of these charactristics is the one that is the key to the popularity of RISC: with many registers, several different calculations, each one independent of the others, can be interleaved in a sequence of instructions.
While coding that way is confusing, and hence not natural for human programmer, a compiler can be designed to do this when possible; and, if successive instructions do not depend on each other, their execution can be overlapped.
Earlier computers could still overlap fetching and decoding an instruction with the processing of the previous instruction; the 7094 II and the SDS 9300 are examples of computers that did this. But dividing the execution of an instruction into steps, and overlapping the execution of succeeding instructions, as opposed to just preliminary instruction processing, raised an issue, since, normally, most instructions in computer programs had tended to depend on the result of the immediately preceding instruction.
In the absence of a large register pool, as provided by RISC a complicated and expensive technique, out-of-order execution, was required to allow superpipelining to provide performance gains. However, time has marched on, and today's high-performance implementations of most major RISC architectures are out-of-order, since 32 registers, as most of them have, are not enough to interleave as many different calculations as are needed to postpone dependencies for the number of cycles required by their current pipelines with many stages.
Another kind of computer is the Digital Signal Processor (DSP). These processors are designed for very high performance, and often have a sort of VLIW architecture.
Originally, a Very-Long Instruction Word computer meant something like a Control Data Cyberplus, where a single instruction would specify, somewhat like a word of horizontal microcode, what each of the computer's functional units should do for a given cycle.
Today, the same term is used to describe computers that have instructions that do not look much different from those of a conventional computer, but which execute several of them at a time, in batches that typically include up to eight instructions, and which are usually of variable size.
The Intel Itanium is an architecture which is intermediate between this kind of VLIW and conventional RISC; each 128-bit instruction word contains up to three instructions, and their available types are closely tied to the chip's superscalar capabilities.
Recently, I have been thinking about DSP-style computing, and, as well, about linking together the ability to execute instructions in CISC, RISC, and DSP forms.
CISC programs are easier to write, and as a CISC computer has only a limited number of registers, a CISC program would require less resources.
But if out-of-order execution is not used, RISC is needed to allow the instruction-level parallelism (ILP) in any one program to be exploited so as to allow that program to finish faster (to reduce latency).
So, I was thinking in terms of a computer for which programs were designed like this: the whole program was written in CISC code, but those sections of the program that had available ILP would be duplicated in RISC form as well. If many threads were running, the CISC version of those sections would execute; if only a few threads were present, then the available resources would be put to use towards making those threads finish more quickly by running their RISC versions where available.
And then I thought that this concept might also be extended further to embrace DSP-style code as well.
Here is what an instruction set in which DSP, RISC, and CISC code are closely related might look like:
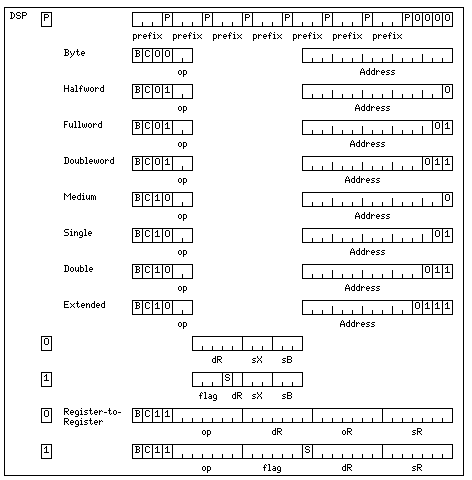
The diagram is divided into five boxes, labelled DSP, DSP-X, RISC, CISC, and CISC-A.
In the first box, I show the relatively simple DSP architecture I first thought of.
Each 32-bit instruction begins with two bits that serve a specialized purpose: B is the block mark bit, and C is the bit that indicates that an instruction is allowed to set the condition codes.
The remaining 30 bits are enough for a conventional RISC instruction set, even with 128 rather than 32 registers.
The same eight base registers would be used in DSP, RISC, and CISC modes of operation.
The eight integer registers used in CISC mode would serve as index registers in DSP and RISC modes, and some special register-to-register instructions would be available to access them as well as the eight CISC floating-point registers. This is needed to allow switching between modes, as when DSP or RISC execution ends, the large pool of registers used in that mode must be freed up.
In DSP mode, the block mark bit, B, works like this:
A block may contain up to eight 32-bit instructions. It only needs to be aligned on a 32-bit boundary.
The B bit is set on the last instruction of a block, so that the 32-bit word immediately following the last block in a section of DSP code is not spoiled by having to have the B bit set in it; so it is usable for code of other types or for data.
All the instructions in a block must be independent of one another, because their decoding and execution will begin simultaneously, leaving no opportunity to check for dependencies. The instructions in the next block, and indeed the next few blocks, should also be independent, because it is intended to begin processing them in the cycles which immediately follow, and it is intended that the implementation will be a high-performance implementation with a deep pipeline.
The C bit is used for the same purpose as in many RISC architectures, such as the PowerPC from IBM and Motorola; it indicates that an instruction may set the condition codes. Here, because instructions are grouped in blocks, if a block contains a conditional branch instruction, it will test the values of the condition code bits as they existed when the block was started; so the condition codes, as set by the most recent instruction in a previous block, will be what is relevant; if there is an instruction in the current block with the C bit set, its effect on the condition codes will only be available to instructions in later blocks.
Also, if a block contains a branch instruction, the branch takes place, in effect, after all the other instructions in the block are completed, and the position of the branch instruction within the block is irrelevant. It is acceptable for a block to contain more than one branch instruction if they are all conditional branch instructions with mutually-exclusive branch conditions.
Branches from DSP code will normally be into DSP code.
Note that the memory-reference instructions only have eight possible destination registers out of the 128 registers available. I envisaged appending 0000 to the three-bit register number in the destination register field, so that registers 0, 16, 32... to 112 would be possible destinations.
I envisage that an implementation would fetch 256 bits of instructions at a time, and buffer them so as to assemble the current instruction block when it crosses a 256-bit boundary, as it often would.
Not only are the same eight base registers used in DSP mode and RISC mode as in CISC mode, but the eight arithmetic/index registers of CISC mode serve as the index registers in DSP mode and RISC mode.
Since 32 registers have proven to be insufficient for allowing RISC architectures to eschew out-of-order operation if high performance through a deep pipeline is desired, I thought that while going to 128 registers might meet the needs of RISC, it might be inadequate for allowing all the instructions in perhaps twelve blocks, each containing eight instructions, to be independent, as needed for maximum DSP performance.
So I considered going from 128 registers to 1024 registers (that is the number of registers in each register bank, integer and floating) by modifying the format of the 32-bit instruction in a block that has the B bit set.
Originally, I thought that this meant the B bit would have to be set at the start of a block, and that branches could only be to the first 32-bit instruction in a block, but upon reflection, I realized that neither of those concerns was the case - as the whole block is processed at once.
However, it may not be currently technically feasible to put a bank of 1,024 registers on a chip, and have them all accessible in a single cycle.
Note that room is made for the prefix field by making the register-to-register instructions two-address instead of three-address, and by allowing only register zero (of each group of 128 registers) as the destination for a memory-reference instruction. Since only one instruction in a block has these limitations, because the prefix code value applies to the whole block, they should not be too serious.
Since the DSP mode looks a lot like the instruction set of a normal RISC computer, few changes would need to be made to the instruction formats. But at least one optimization seemed to be in order: so that 32 of the 128 registers could be the destination of a load or store instruction, the fact that load and store instructions (and, for that matter, branch instructions) never set condition codes meant that the condition code bit could be added to the opcode for those instructions.
The first bit of each 32-bit instruction word, the block mark bit, could also be used as part of the opcode in RISC mode; at the moment, though, it seems that it is not required.
Here, I tried to achieve something that would have the properties of a CISC architecture, and yet which would have enough of a resemblance to the RISC and DSP architectures previously defined so as to fit in gracefully with them.
The memory-reference instructions get a seven-bit opcode field, so there is room for memory-reference arithmetic instructions.
Instructions are still aligned on 32-bit boundaries; register-to-register instructions can fit two to a word, but they therefore must occur in pairs.
While that disposes of part of the burden of variable-length instruction coding associated with CISC, I did want to provide, as well, additional types of instruction in CISC mode that would require more than 32 bits to specify.
To ease the burden of handling this, I came up with the following scheme:
Just as in DSP mode, instructions would be fetched 256 bits at a time. But here, the first bit of each 32 bits would not divide the instructions into blocks. Instead, the 256-bit physical blocks would have some significance in CISC mode.
The first bit of each 32 bits, used as the block mark bit in DSP mode, and left as zero in RISC mode, is here used as a "warning" bit.
When the W bit is set in one of the 32-bit words of a 256-bit physical block, then the corresponding 32-bit word of the next 256-bit physical block shall be the first 32 bits of a 64-bit instruction.
This places certain restrictions on possible branch targets:
If there are any 64-bit instructions in a 256-bit physical block of CISC code to which a branch is made, those 64-bit instructions must entirely precede the 32-bit instruction which is the target of the branch.
Multiple register instructions would fit in 32 bits if there were enough opcode space available; since they aren't, to avoid wasting the remaining space in a 64-bit instruction, they are combined with register-to-register instructions to form a 64-bit instruction, on the basis that register-to-register instructions will be used frequently enough that they will almost always be useful.
Upon refletion, it appears that it will be necessary after all to free up additional opcode space through restricting 32-bit memory-reference instructions to aligned operands. This makes enough opcode space available to allow multiple-register instructions to fit in 32 bits, among other things.
Except for the 64-bit multiple-register instructions, the 64-bit instructions shown for the CISC mode will also be present here, but they have not been repeated to save space in the diagram.
The following diagram:
shows how additional efforts were made to modify the DSP instruction formats to further conserve opcode space in order to provide two important additional features.
Instruction predication is a feature that has been used with some RISC processors as well as many DSPs. It had even been used on some of the earliest computers ever built. This avoids conditional branches by using instructions to test conditions, and set flag bits based on those conditions, and then having subsequent instructions include a field which selects one of the flag bits, so that the instruction will only execute if the flag bit is set - or cleared, the sense to test for being selectable.
Rather than implementing it by adding a field to select a flag bit to every instruction, I chose to have one bit select if an instruction is predicated or not, as I felt that while I could shorten the instructions to make room for the new field selecting a flag bit, and still have them reasonable, I would prefer to at least allow the non-predicated instructions to use more bits.
The second issue I wished to deal with stemmed from this: given today's deep pipelines, as 32 registers was no longer enough for a RISC design to avoid the need for out-of-order execution, I had decided to give register files, one for integers and one for floating-point numbers, each having 128 elements, to tasks running in RISC mode.
This meant that DSP mode, which would involve executing blocks of up to eight instructions, ideally one new block every cycle, would need even more registers.
But I had been advised that due to delays in multiplexing logic, and issues relating to the length of signal paths, and perhaps other causes as well, one can't just make a register file as long as one wants, assuming that allocating six transistors to every bit will guarantee one can always access a word from the register file in a single cycle.
A reasonably obvious way of dealing with this would be to have the DSP instruction stream control the operation of eight RISC cores, each with register files of 128 elements. The TMS320C6000 DSP divides its registers into two groups, A and B, allowing a limited number of operations per execution block on the data in each of these groups of registers, and allowing a very limited number of transfers between the two groups of registers in a single execution block, so there is a precedent for organizing a CPU in this way.
However, compaison with the TMS320C6000 also highlights a serious flaw in the DSP component of this architecture as envisaged so far. The DSP320C6000 basically has two cores, each with four functional units. Thus, the ability to have an execution block specify up to eight operations, as a maximum, is well-suited to keeping the available functional units fully utilized. Having about four functional units in a CPU core is typical, as normally there would be one to handle addition and subtraction, one to perform shifts, one for multiplication, and one for division. Contrast this with my proposal to deal with the size of the register files required for DSP mode by going to eight cores. This means that the instruction format is now far behind the capabilities of the hardware on which it is running; to catch up, four DSP threads would have to be running simultaneously. This defeats the purpose of a DSP mode, which is to allow the chip to bring its full power to bear, when sufficient instruction-level parallelism (ILP) is available, on making one thread run faster. Going to a block with 32 instructions in it, instead of eight, is not an available solution; already, the DSP mode format demands a great deal of ILP, which will be only seldom available in programs. Using only two RISC cores to execute a DSP thread would bring about a closer match between the level of parallelism the DSP format can exploit and the available resources. Originally, the DSP format was conceived as allowing the register bank to be specified once per block. It was modified to include a bank specification for every instruction due to the shift to eight cores, since it would not make sense, after splitting up the 1,024 registers in each pool of registers into 128 registers on each of eight cores, to then have each block only use one of those cores. So, if a shift to two cores (per DSP thread) is envisaged, the instruction format might be changed to involve less overhead for specifying register banks. However, for one core, the extra three bits, once per block, could fit; for eight cores, one 32-bit word ended up having to be given up; six bits of overhead per block, plus one bit of overhead per word, to allow two banks to be specified per block, would not fit well with having either seven or eight instructions in a block. And, in addition, even without a change in instruction format, the original issue, that more than 128 registers at a time will likely slow access to those registers, will return. Of course, it is also true that programs seldom have a balanced mix of addition, multiplication and division to do at a given time, so this issue is perhaps not as severe as I have painted it; perhaps leaving the instruction format as it is, but going to four cores rather than eight, would be an appropriate compromise, if that did not already make the register banks too large to be reasonably fast. |
This, though, meant that my earlier idea of having the last instruction in every block select the same group of 128 registers for all the instructions in the block would no longer work; instead, it would need to be possible for each instruction in a block to refer to a different set of 128 registers. (It would not be necessary, however, as two independent instructions could also use different functional units in the same core.)
That would require taking another three bits from each instruction. Combined with the demands of instruction predication, I could not see an acceptable scheme of fitting everything into a 32-bit instruction word.
One way I thought to deal with it was to have the last word of an execution block, which I had earlier put in a special format to indicate the group of 128 registers used for the whole block, contain four additional bits for every other instruction in a block. But if it had to always be done this way, with no alternate format restricting instructions to 32 bits instead of 40 bits, then when a block was short, with only one or two instructions in it that can be started on the same cycle, then the overhead would be excessive.
And so in the diagram above, the first line instead shows the format of the first 32-bit word in a 256-bit storage block, which supplies four additional bits to each of the seven remaining 32-bit words in the storage block, without regard for the boundaries between execution blocks, indicated by setting the first bit of a 32-bit word, marked B in the diagram, in the last 32-bit word of the execution block.
Thus, if the 32-bit word is too short, I use the fact that 256 bits are fetched at a time to make the word longer.