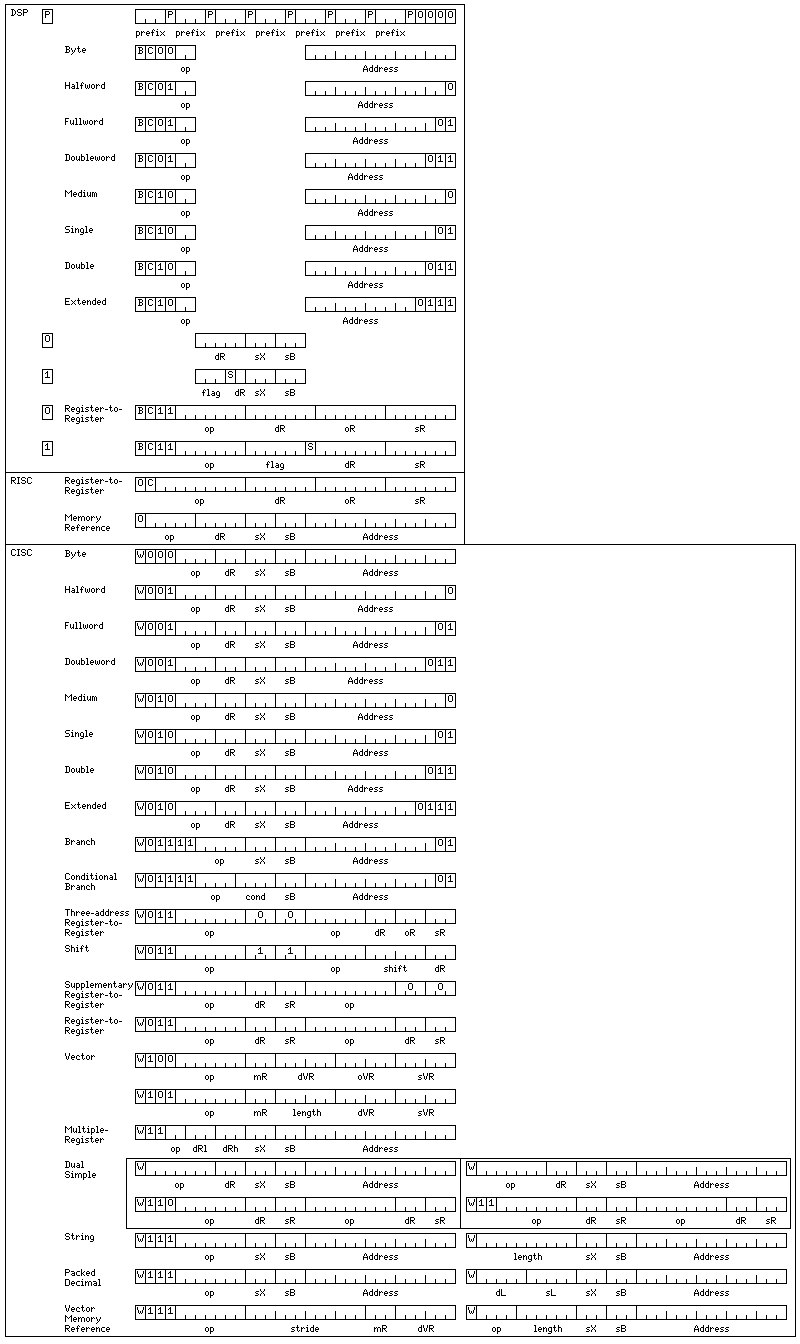
Having worked out, on the previous page, how to fit everything required for the instruction set into the space available, here are the instruction formats for the addressing modes that have survived:
The diagram is divided into three boxes, labelled DSP, RISC, and CISC.
The next step is to ask if the instructions for every operation of which I wish the architecture to be capable will really fit into the available space.
Some minor changes have been made to the CISC mode compared to the depiction on the previous page. The seven-bit opcodes for the vector instructions are no longer restricted to the basic set; the first two bits of the opcode may both be one. Instead, additional opcode space was created by not allowing both operands of a register-to-register instruction to be identical.
Thus, the instructions in the CISC mode from the Branch instructions to the Register-to-Register instructions are now shown in decoding order; if the first two bits of the opcode field are 1, one has a Branch or Conditional Branch instruction; otherwise, if the two register operands of the first of two register-to-register instructions in a 32-bit word are identical, one might have either a Three-address Register-to-Register instruction or a Shift instruction; otherwise, if the two register operands of the second of two register-to-register instructions in a 32-bit word are identical, one might have a Supplementary Register-to-Register instruction; otherwise, one has the default compound Register-to-Register word containing two instructions.
The Supplementary Register-to-Register instructions, like normal register-to-register instructions, cannot have both register fields identical; therefore, they appear after the Three-Address Register-to-Register instructions and the Shift instructions, because those instructions repurpose the last six bits of the 32-bit word, and thus they do not (at least in the case of the Shift instructions) guarantee that the last two three-bit areas of the word are not identical.
Another change is that the copious opcode space available for 64-bit instructions has now been utilized to provide a simple means of specifying unaligned memory-reference instructions. Just as a 32-bit instruction can contain two register-to-register instructions, a 64-bit instruction can contain two 32-bit instructions which may either be a dual register-to-register instruction, or a memory-reference instruction not restricted to aligned operands, but it may not contain 32-bit instructions of other types.
To be more specific, the "other types" that are excluded are the Branch, Conditional Branch, Vector, and Multiple-Register instructions. Those additional types of instructions that are indicated by making the source and destination registers of a register-to-register instruction the same, the Three-Address Register-to-Register, Shift, and Supplementary Register-to-Register types of instruction, are permitted to occur as one of the halves of a 64-bit instruction in the Dual Simple format.
It is important to allow multiple-register instructions, on the other hand, in regular 32-bit instructions so that one can appear, for example, at the very beginning of a subroutine (remember the restrictions on branch targets, so that 64-bit instructions can only appear where it is guaranteed that the previous memory block of instructions was fetched, so that the warning bits are available), as these instructions are used in calling sequences to save and restore registers.
Note that the opcode of the first register-to-register operation in the second word in this format is eight bits long, since a bit is not required in that location, as it is in the first word, to distinguish instructions in this format from the remaining 64-bit instructions.
Let's start with the CISC mode of operation.
Because 64-bit instructions are available in this mode, the amouont of opcode space available is plentiful indeed, as long as one allows oneself to resort to them.
However, the 32-bit portion of the instruction set is somewhat constrained, particularly as I sought to have the multiple-register instructions remain only 32 bits long; this meant that a quarter of the opcode space had to be turned over to them.
Both the register-to-register instructions and the vector instructions use seven-bit opcodes, the first two bits of which cannot both be one. These opcodes will use the same coding we have met frequently in connection with the Concertina architecture, seen elsewhere on these pages.
0000 0001 0010 0011 0100 0101 0110 0111 SWB IB SWH IH SW I SWL 000 CB UCB CH UCH C UC CL UCL 001 LB ULB LH ULH L UL LL *LA 010 STB XB STH XH ST X STL XL 011 AB NB AH NH A N AL NL 100 SB OB SH OH S O SL OL 101 *LAB MH MEH M ME ML MEL 110 *STAB *STBG DH DEH D DE DL DEL 111 1000 1001 1010 1011 SWM SWF SWD SWQ 000 CM CF CD CQ 001 LM LF LD LQ 010 STM STF STD STQ 011 AM AF AD AQ 100 SM SF SD SQ 101 MM MF MD MQ 110 DM DF DD DQ 111
First, we have four groups of sixteen instructions, for each of four data types.
The data types are:
B Byte 8 bits H Halfword 16 bits Integer 32 bits L Long 64 bits
and the operations are:
SW Swap C Compare L Load ST Store A Add S Subtract M Multiply D Divide I Insert UC Unsigned Compare UL Unsigned Load X Exclusive OR N AND O OR ME Multiply Extensibly DE Divide Extensibly
Some of these operations may need some explanation.
In this architecture, the eight arithmetic/index registers are each 64 bits long, for compatibility with the RISC and DSP modes of operation.
But fixed-point data may be 8, 16, or 32 bits in length in addition to 64 bits in length.
Thus, loading data from memory into a register is handled by three different instructions.
Load performs sign extension, fixed-point values normally being handled as being in two's complement form.
Insert puts the data being addressed in the least significant portion of the register destination, leaving the more significant bits unaffected.
Unsigned Load clears the bits of the register which are more significant than the data being retrieved.
These operations, and even their names, will, of course, be familiar to System/360 assembler programmers.
Multiply and Divide, however, do not work the way the corresponding instructions did on the System/360. Instead, like the corresponding floating-point instructions, they take two operands of the same length to produce a result that is also of the same length. So no remainder is provided from the divide instruction, and overflows are quite possible from the multiplication of large numbers.
This makes them correspond directly to the usual multiplication and division operations used in higher-level languages.
When additional capabilities are needed, however, the Multiply Extensibly and Divide Extensibly operations are available. These two instructions, as described here, work somewhat differently from the instructions of the same name for the Concertina architecture.
Multiply Extensibly takes two operands, and produces an integer product that is twice as long.
This can still fit in a single register, except for the case of the Multiply Extensibly Long instruction. This instruction will take an odd-numbered register as its destination operand; the product of its contents and those of the source operand will have its most significant part placed in the even-numbered register preceding the one that is the destination operand, and its least significant part placed in the destination operand itself.
Divide Extensibly takes a destination operand that is twice as long as the source operand. An even-numbered register is its destination operand in all cases; in the case of the Divide Extensibly Long instruction, the constraint is more strict, and the number of the register used as the destination operand must be divisible by four.
The number in the destination operand is divided by the number at the source operand. The remainder is placed in the destination operand, and the quotient is placed in the register, or registers, that follow it.
In the case of Divide Extensibly Halfword, the destination operand is the last 32 bits of the register specified; for Divide Extensibly, it is the entire register, and for Divide Extensibly Long, it is the register pair consisting of the register specified (with the most significant part of the dividend) and the register following (with the least significant part of the dividend).
The quotient is placed in the next higher register for Divide Extensibly Halfword and Divide Extensibly; it is placed in the next higher register pair for Divide Extensibly Long.
The quotient and remainder are the same length as the dividend or destination operand, and thus are both twice the length as the divider or source operand.
Thus, a divide check exception, where the quotient of a double-length dividend and a single-length divisor is too long to fit in a single-length result does not arise from the Divide Extensibly instruction.
Additional opcodes, shown with an asterisk in the table above as they do not follow the standard pattern of the other entries there, but performing additional vital functions are:
0000110 LAB Load Address/Base 0000111 STAB Store Address/Base 0001111 STBG Store Byte if Greater 0111010 LA Load Address
The Load Address/Base and Store Address/Base instructions allow data to be transferred to and from the eight base registers.
The Store Byte if Greater instruction stores the byte in the destination register at the source memory location only if the unsigned value of that byte is greater than the value already stored in that memory location.
The Load Address instruction loads the destination register with the effective address itself, rather than the data contained in memory at that address.
Except for LAB and STAB, however, these opcodes are not applicable to register-to-register instructions.
These opcodes can fit in the format of memory-reference instructions provided in this CISC mode, but in different positions in most cases.
LA Load Address w0001110 STBG Store Byte if Greater w0001111 LAB Load Address/Base w0010000 ... 011 STAB Store Address/Base w0010010 ... 011
The Load Address instruction is placed among the byte-aligned instructions for maximum flexibility.
Since the base registers are 64 bits long, the instructions to load and store their contents are placed among the instructions for the 64-bit long integer type, using the unused Insert and Unsigned Load opcodes for that type.
Floating-point instructions use the first eight basic operations listed above:
SW Swap C Compare L Load ST Store A Add S Subtract M Multiply D Divide
and apply them to the following data types:
M Medium 48 bits F Floating 32 bits D Double 64 bits Q Quad 128 bits
Floating, Double, and Quad are the normal standard IEEE 754 single, double, and extended precision floating-point numbers respectively.
Medium floating-point numbers, 48 bits long, are similar to single and double precision floating-point numbers in IEEE 754, but with one sign bit, an exponent field of ten bits, and a significand that is thirty-seven bits long.
Note that the Medium floating-point type is placed first in the list; numbers of this type are considered aligned operands, as opposed to unaligned operands, when they are aligned on 16-bit boundaries in memory. Thus, the ordering reflects alignment granularity rather than length.
The memory-reference instructions, as is typical for a CISC architecture, allow all normal operations between registers and memory instead of just loads and stores. Since there are sixteen such operations, a four bit field for the opcode is sufficient. In the case of the floating-point type, for the medium, single, and double types, additional unused opcodes are therefore available.
In the case of extended precision floating point, however, as the first bit is not hidden with that type, additional operations involving unnormalized arithmetic are provided:
The last part of the instruction set that is potentially tricky are the multiple register instructions.
There are four possible opcodes. That obviously is sufficient for load multiple, store multiple, load multiple floating, and store multiple floating.
But what about the eight base registers?
Fortunately, a detail not shown in the diagram comes to the rescue. The ordinary memory-reference instructions have been restricted to aligned operands in order to save enough opcode space for the multiple-register instructions to be placed among the 32-bit instructions.
There is no reason for the multiple-register operands to be able to handle unaligned operands. Thus, the opcodes can be allocated as follows:
LM Load Multiple w1100 ... 011 STM Store Multiple w1100 ... 011 LMF Load Multiple Floating w1100 ... 0111 STMF Store Multiple Floating w1100 ... 0111 LMB Load Multiple Base w1101 ... 011 STMB Store Multiple Base w1101 ... 011
Incidentally, it may be desired to provide for short vector instructions. If only eight, rather than sixteen, as in the Concertina architecture, short vector registers (again of 256 bits) are provided, one can have:
LMSV Load Multiple Short Vector w1100 ... 01111 STMSV Store Multiple Short Vector w1100 ... 01111
and 256-bit alignment can also provide opcodes for short vector memory-reference instructions.
Register-to-register short vector instructions, packed one to a 32-bit word instead of two to a word, could be provided within the very large extent of opcode space shown in the diagram as available for the shift instructions. This would also allow for additional fields for masking portions of the vectors, which would be lacking in the memory-reference instructions provided by the expedient noted above.
In RISC mode, memory-reference instructions are shown as having a five-bit opcode field which overlaps with the C bit, indicating that the condition codes may be set, for register-to-register operations.
Thus, some attention to how their opcodes are organized is required, and I propose the following organization:
00100 LM Load Medium 00101 STM Store Medium 00110 LF Load Floating 00111 STF Store Floating 01000 LB Load Byte 01001 STB Store Byte 01010 IB Insert Byte 01011 ULB Unsigned Load Byte 01100 LH Load Halfword 01101 STH Store Halfword 01110 IH Insert Halfword 01111 ULH Unsigned Load Halfword 10100 LD Load Double 10101 STD Store Double 10110 LQ Load Quad 10111 STQ Store Quad 11000 L Load 11001 ST Store 11010 I Insert 11011 UL Unsigned Load 11100 LL Load Long 11101 STL Store Long
This means that the first two bits of the opcode of a register-to-register instruction must be zero, but that still leaves a seven-bit opcode, which, as we have seen, is adequate.
However, this does imply that it might turn out to be useful, after all, to include the first bit of the instruction in the opcode, rather than just leaving it zero, as analogy to the other instruction modes, where it is used either as a block mark bit (DSP) or a warning bit (CISC) had suggested.
For one thing, it has been noted that RISC mode will require special instructions to transfer data between the set of 128 registers normally used in that mode, and the set of 8 registers used in CISC mode. Extra register-to-register opcodes will be needed for this special function; as well, the eight base registers need to be accessible, just as in CISC mode.
In DSP mode, the instructions have effectively been lengthened from 32 bits to 40. Even so, they are tightly squeezed, particularly if predicated.
The two bit opcode for memory-reference instructions is enough to specify load and store:
00 L Load 01 ST Store 10 I Insert 11 UL Unsigned Load
Unconditional branch and jump to subroutine can have these opcodes:
bc1010 ... 01 JMP Jump bc1011 ... 01 JSR Jump to Subroutine
since insert and unsigned load are not applicable to floating-point numbers.
However, register-to-register operations have only a seven-bit opcode. This still leaves room for some additional operations in addition to the basic ones. Fortunately, a flag bit setting operation does not need as much opcode space as a conditional branch, since sixty-four flag bits only require a six-bit field to specify, as opposed to twenty-one bits - three for an index register, three for a base register, and fifteen for the displacement - as used for a memory address.
If one is desperate, a conditional jump can be implemented as a predicated unconditional jump, although that involves two instructions instead of one.