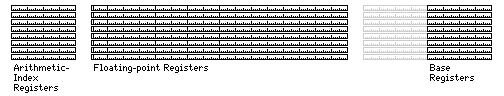
Computers are devices which automatically perform calculations. One type of computer is the electronic stored-program digital computer, and this is what people commonly think of when they think of a computer.
If a computer is not electronic, it might use electrical relays to accomplish the same switching operations as the logic gates which are built from transistors in an electronic computer. While this makes a large difference in terms of bulk, cost, and speed, conceptually it makes little difference to understanding the computer as an abstract device to process information.
In the early days of computers, there was no fully satisfactory way to store reasonably large quantities of information for access at speeds comparable to those of the computer. Thus, a possible configuration for a very early computer might include an internal memory of about thirty-two registers, each able to contain a number, and each available for random access with direct addressing, and built from the same types of component as used for the logic gates of the computer, along with some sort of sequential-access information source for programs and larger quantities of data. That information source might still be considered memory, such as a magnetic drum memory or a delay line, or it might be an input device, such as a paper tape reader or a punched-card reader. Or a computer might even have been programmed using patch cords. Depending on various design details, such an early computer might have had a greater or lesser departure from the way today's computers operate, but many of the same principles would still apply.
It is when one goes from digital computers to analog computers that one gets a completely different type of machine; one that can find approximate solutions to a number of mathematical problems, including ones that were very difficult for digital computers to deal with. But such computers could not handle multi-precision arithmetic, or work with text, or otherwise act as fully general-purpose computing devices.
These pages present a design for an electronic stored-program digital computer. It is a large and complex design, perhaps more so than any computer that has actually been implemented. This is true despite the fact that the design starts from a relatively simple architecture which serves as its basis.
This is because the simple architecture is then extended in a number of ways.
Supplementary instructions are added for the purpose of operating on arrays of numbers in a single operation, and for performing complex operations predefined by the user on character strings.
Various modes of operation are provided. Some of these are provided to permit the computer to perform more calculation steps in response to the fetching of a given number of words of program code from memory, others to broaden the available addressing modes and make the available set of instructions more uniform, and others to give access to some extended features of the machine.
Also, flexibility in data formats is provided, and one of the instruction modes in particular (general register mode) is designed, to facilitate emulation of other architectures. Given that market forces have limited the number of available architectures, one of my goals in specifying this architecture is to show how a microprocessor could be designed, without sacrificing efficiency, to permit programmers with different architectural preferences to choose a mode of operation accomodating those preferences from those available on a single microprocessor chip.
It is from these features that the complexity of the architecture is derived.
But the basic part of the computer's architecture is simple. Although it has more registers available to the programmer than illustrated below, this diagram shows the most important registers of the computer:
Eight registers are Arithmetic/Index Registers. These are the registers used when the computer performs calculations on binary integers. They are 32 bits long, since that is usually as large as a binary integer used in a calculation needs to be. They are also used optionally in address calculation: an indexed instruction, where the contents of an index register are added to the address, lets the computer refer to elements of an array. Integers are treated as signed two's complement quantities.
Eight registers are Floating-Point Registers. These are used when the computer performs calculations on numbers that might be very small or very large. These registers are 128 bits long. Usually, a 64-bit floating-point number is more than large enough, but while it is possible to make two integer registers work together on a larger number, this is not as easy for floating-point numbers because they are divided into an exponent field and a mantissa field. The term mantissa refers to the fractional part of the logarithm of a number; while its use with floating-point numbers is criticized by some as a misnomer, the mantissa of a floating-point number represents the same information about that number as would be contained in the mantissa of its logarithm: the part that needs to be multiplied by an integer power of the base to produce the actual number.
Eight registers are Base Registers. These registers may be 64 bits long if 64-bit addressing is provided. They are used to help the computer use a large amount of available memory while still having reasonably short instructions. A base register contains the address of the beginning of an area in memory currently used by the program running on the computer. Instructions, instead of containing addresses that are 32 bits or even 64 bits long, contain 16 bit addresses, accompanied by the three-bit specification of a base register.
Since a 32-bit address pointing to a particular byte allows reference to four gigabytes of memory, and many personal computers today have memory capacities on the order of 512 megabytes, it is entirely reasonable to expand the possible address space beyond 32 bits. But expanding it to 64 bits allows a memory four billion times as large as four gigabytes. Is that far larger than could ever be useful?
Avogadro's number is 6.022 times ten to the twenty-third power; it is (approximately) the number of hydrogen atoms that weigh a gram.
Thus, ten to the twenty-fourth power carbon atoms weigh 20 grams, and ten to the twenty-fourth power iron atoms weigh 94 grams. And, since two to the tenth power is 1,024, that means two to the eightieth power carbon atoms weigh about 25 grams.
A virtual address is often intended to refer to a location in a memory much larger than the actual physical random-access memory of a computer, because the additional memory locations can refer to pages swapped out to a magnetic storage device, such as a hard disk drive.
About 120 grams of iron would allow storage of two to the sixty-fourth power bits of information, even if it required 64,000 iron atoms to store a single bit. Thus, two to the sixty-fourth power bytes, or 16 million yottabytes, require less than a kilogram of iron to be stored at that efficiency. Thus, storage of that much information doesn't flatly contradict the laws of physics. 128-bit addressing, on the other hand, is likely to be safe from any demand for improvement for a very long time.
The instruction formats of this architecture owe a great deal of their inspiration to the IBM System/360 computer, although some other details were influenced by the Motorola 68000 microprocessor. The resulting instruction format, dividing a 16-bit halfword into a 7-bit opcode followed by three 3-bit fields indicating registers, is similar to that of the Cray-1 supercomputer; this had no direct role in inspiring the original basic design of this architecture, but the additional vector register capabilities of this architecture are very much inspired by that computer and its successors.
Although the arithmetic/index registers and the base registers may be thought of as corresponding, respectively, to the data and address registers of the Motorola 68000 architecture, there is one important difference: 68000 addressing modes allow one to choose whether to use a data register or an address register for indexing; here, only the arithmetic/index registers may serve as index registers.
The architecture described here can be thought of an attempt to construct the most powerful processing unit possible, by incorporating every feature ever used in computer design in attempts to make larger and more powerful computers.
Since the value of a computer is largely determined by the software it can run, the number of different computer architectures for which an abundant selection of software is available is likely to be limited; thus, offering the full range of computer capabilities within a single architecture allows choice and diversity to be retained. While some models of the IBM System/360 series had some vector arithmetic capabilities (these capabilities, in fact, inspired the external vector coprocessing abilities of this architecture), the VAX 6500 and some other models of VAX are almost unique in offering both decimal arithmetic and Cray-style vector capabilities.
The complexity of the full design described here allows a wide range of aspects of computer architecture to be illustrated. As well, because not all problems can be parallelized fully enough to be split up between different processors, taking advantage of the continuing improvement in computer technology first by building the fastest possible single processor and only subsequently by using as many processors as one can afford does make sense. Thus, the design illustrated here, although it includes some features which involve parallelism, is not an attempt at resolving the problem that has been termed the von Neumann bottleneck. The classic von Neumann stored-program computer architecture involves one central processor that does arithmetic, making use of information stored in a large memory. Thus, most of the information in the memory lies idle, while computations take place involving only a small number of items of data at a time.
Neural nets, cellular automata, and associative memories represent types of computing machines where the entire machine is engaged in computation. The trouble with these extreme solutions to the problem is that they are helpful only in certain specialized problem domains. On the other hand, a von Neumann computer with a magnetic drum memory or a magnetostrictive delay line memory is also using all its transistors (or vacuum tubes!), the potential building blocks of logic gates, to perform computation, so perhaps the wastefulness is merely the result of memory cells being comparable to logic gates in current integrated circuit technology.
A less extreme solution that has been suggested is building memories which include a small conventional microprocessor with every 4K words or every 32K words of RAM. One obstacle to this is standardization. Another is whether this would be worth the effort. It is also not clear that simply because one can put sixteen megabytes of RAM on a chip, one can also put 2,048 microprocessors (one for each 4,096 16-bit words), or even 128 microprocessors (one for each 32,768 32-bit words), on that chip as well. Would these small microprocessors have to include hardware floating-point capability to be useful, or would smaller ones that can only do integer arithmetic on single bytes be appropriate?
This page discusses one possible approach to this problem.
The following diagram illustrates more of the registers belonging to the architecture described here:

It does not illustrate all of them; there are banks of registers used for long vector operations which involve eight and sixty-four sets of registers each of which is equal in size to the entire set of supplementary registers shown in the diagram, and a process may also have additional register space allocated to it for use with the bit matrix multiply instruction, to be described later, involving multiple sets of registers similar in size to the short vector registers.
Thus, in addition to the basic three sets of eight registers, there are three other groups of eight registers like the base registers used to allow shorter instructions in some formats, there is a group of sixteen 256-bit registers used to allow vector operations in most operating modes, and there are also banks of sixty four registers for longer vector operations. The availability of these larger banks of registers might be restricted to some processes in a time-sharing environment, or they might be implemented using only cache memory, slower than actual registers, in some less expensive implementations of the architecture. The short vector registers serve an additional purpose as a bit matrix multiply register in some modes.
The architecture described on this site has been modified from time to time. Recently, the ability to use the cache memory as an instrument of accessing memory, externally divided into units of 256 bits, in multiples of other word sizes, such as 24, 36, and 40 bits, to allow memory-efficient emulation of older architectures, was added.
A feature to assist in emulation by providing a method of decoding an instruction in an instruction format described to the computer, and submitting converted instructions for execution has now been defined, but this definition is in its earliest stages. As well, this feature includes a method of retaining results of conversion, in a tabular format, so that each location in the table corresponds to a location in the memory of the computer being emulated (as opposed to true just-in-time compilation) and executing instructions from the table in preference to repeated translation, where possible, Although this architecture provides a significant degree of flexibility in its data formats, the attempt has not been made to allow all possible data formats, so a feature for conversion of arithmetic operands is also included, and this feature can be used outside of emulation to assist in converting data for use by a program operating in emulation.
Although this architecture has been designed, in some respects, according to my architectural preferences (i.e., it is big-endian by default), because I have included nearly every possible feature a computer could have, in order to allow this architecture to serve as a springboard for discussing these features, it would seem that, like the DEC Alpha, but even more so, it could not compete economically with simpler architectures for any given level of performance, except, of course, in those occasional applications where one of this architecture's more exotic features, not found elsewhere, proves to be useful. I cannot, therefore, unreservedly advocate it as fit for implementation, although I certainly would like to see some sort of CISC big-endian architecture with pipeline vector instructions become available at prices, and with a complement of software, reflecting the benefits of a mass market. Even that seems unlikely to happen in the real world at this time; this architecture, whose genre is such as to challenge the makers of acronyms (Grotesquely Baroque Instruction Set Computing?) would seem far less likely to see the light of day.
But, if pressed, I might indeed step forwards to claim that it is not truly all that bad; think of it as a computer like the Cray-1, with the addition of 64 processors that can only reference the cache, and which also has the ability to have multiple concurrent processes running that, by using only a 360-sized subset of the architecture, stay out of the way of the real number-crunching, even as they, scurrying about underfoot, make their contribution to overall throughput.
Eliminate the multiplicity of data storage widths, the plethora of floating-point formats, the Extended Translate instruction (even if one real machine, the IBM 7950, better known as HARVEST, offered somewhat similar capabilities to its one customer, the NSA), the ability to select or deselect, as an option, explicit indication of parallelism and the various postfix supplementary bits, and, of course, the second program counter (even if one real machine, the Honeywell 800, and its close relatives, had this feature), and the Simple Floating data type (even if at least one real computer, the Autonetics RECOMP II, implemented its floating-point capabilities in such a manner, although I know of no real computer that offered floating-point arithmetic of this kind in addition to conventional floating-point capabilities), and the result is an architecture quite comparable in complexity with many real architectures; vector register mode looks a lot like a Cray-1, symmetric three-address mode a bit like a Digital Equipment Corporation VAX (the Flexible CISC Mode, of course, resembles that computer rather more closely), and short shift mode a bit more like an IBM System/360 than the native mode does already (General Register Mode has an even closer resemblance to the System/360).
While one might protest that it is meaningless to note that this architecture would cease to be extravagant after one removes its extravagances, what is meaningful is to, by listing them, show that they are not as many in number, and as expensive in cost, as they might be feared to be on the basis of the initial impression they can create.
One extravagance has finally been successfully eliminated from the architecture as previously conceived. Originally, in addition to a basic instruction format more closely modelled on that of the System/360 and the 68000, there were dozens of alternative instruction formats. Most of these were attempts to be more parsimonious in the allocation of opcode space, so that a larger number of instructions could be only one or two words long.
By using a scheme pioneered on the SEL 32 minicomputer of allowing memory-reference instructions to act only on aligned operands, and then making use of what would be the otherwise unused least significant bits of addresses to help distinguish between data types, by distinguishing between sets of types of different lengths of two or more bytes, it was possible, by judicious choice of which less-frequent instructions to allow to be lengthened, to achieve a set of instruction formats in which all the common operatins were as short as possible.
A further gain that was achieved was to organize the instruction formats so that the length of an instruction could be determined by considerably less logic than was needed to decode the instructions fully. Once this had been achieved, the benefits of making the resulting mode of operation the only one made it imperative to do so.
Since this was written, alternate modes of operation have made a modest return to the architecture. The alternate modes, however, have been integrated into the length-determination scheme, so that switching to an alternate mode does not significantly increase the complexity of deterimining the length of an instruction. |
The original instruction format from which the current design was derived is shown here:
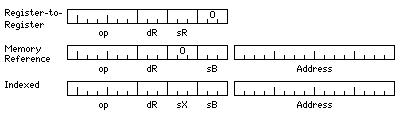
Inspired by the IBM 360, 16-bit address displacements instead of 12-bit ones are obtained by having eight base registers separate from eight general registers used both as accumulators and as index registers - as well as trimming the opcode field to seven bits from eight. Register to register instructions are indicated by putting zero in the base register field instead of by using a different opcode.
Since the elimination of the alternative addressing modes, I have thought of another way in which more opcode space might have been obtained. Using the System/360 Model 20 as a precedent, but with one important change, the base register field can be shifted to the address word while still allowing 15-bit displacements instead of 12-bit ones, at least part of the time:
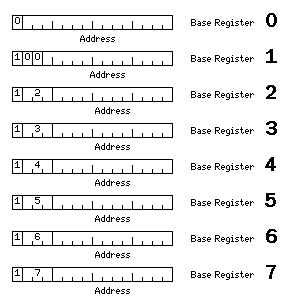
Base register 0 points to a 32K byte region of memory, and base register 1 points to an 8K byte region of memory; the other base registers point to 4K byte regions of memory, as on the IBM 360. Thus, a likely convention would be that a program would use base registers 0 and 1 for its primary data and program areas, either respectively or the other way around as suits its need, and the other base registers to range more widely for data.
As the base register field would not have to be in the first halfword of the instruction, this would allow a generous 10-bit opcode field.
As the number of gates that can be placed on a chip can be increased, there are a number of ways in which they can be used to increase performance. The simplest is to make use of data formats that are as large as are used within applications, rather than smaller ones due to space limitations; this has already been achieved, as we advanced from the days when the only microprocessors that existed only performed integer arithmetic, and only on eight-bit bytes of data. The next is to switch from using serial arithmetic to parallel arithmetic, and then to use more advanced types of circuitry for multiplication and division to achieve higher speeds and the possibility of pipelining, and this too has been achieved. As the number of available gates increases further, the other options that are available include adding more cache memory to a chip, putting more than one CPU on a single die, so that two or more processors can work in parallel, and, as illustrated here, making the architecture more elaborate by adding features, so that a greater number of operations can be performed by a single instruction instead of a short program. Another option, which also addresses the Von Neumann bottleneck, is to put dynamic RAM, which has a considerably higher bit density than the static RAM used for a cache, on the chip. This allows an arbitrarily wide data path from memory to the processor, and, as it happens, this would work well with the architecture outlined here, which could benefit from a 4,096-bit wide path to main memory from the cache, instead of the more conventional 256-bit wide path envisaged as practical.