Morse code uses variable-length symbols made up of dots and dashes, but unlike a straddling checkerboard, the length of a symbol is not determined by the dots and dashes within it. Instead, spaces are also needed to mark off the symbols from each other.
But fractionation is still possible using Morse code as a basis. Elementary Cryptanalysis, by H. F. Gaines, gives a cipher devised by M. E. Ohaver, the author of an early series of magazine columns on cryptanalysis which was of value to her in the writing of that book, called a "mutilation" cipher, that works like this:
Split the message in Morse code into two parts; the string of dots and dashes, and a series of numbers giving the number of dots or dashes in the representation of each letter. Then, take the numbers, divide them into groups of n, and reverse the order of the numbers in each group. Using the now transposed numbers as a guide, turn the string of dots and dashes back into letters.
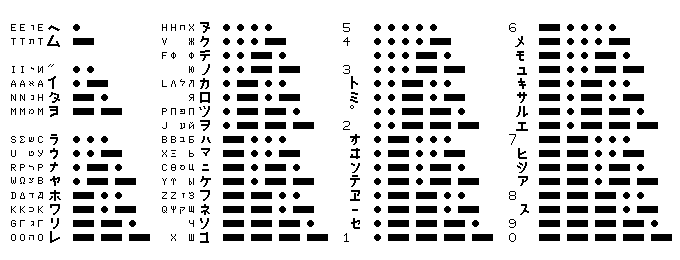
A table of Morse code follows (and, while I'm at it, I may as well include Japanese Morse, having the data available from one of my old USENET posts):
E . CD he I .. DE [A] S ... D7 ra H .... C7 nu
V ...- B8 ku
U ..- B3 u F ..-. C1 ti
(1) ..-- C9 no
A .- B2 i R .-. C5 na L .-.. B6 ka
(2) .-.- DB ro
W .-- D4 ya P .--. C2 tu
J .--- A6 wo
T - D1 mu N -. C0 ta D -.. CE ho B -... CA ha
X -..- CF ma
K -.- DC wa C -.-. C6 ni
Y -.-- B9 ke
M -- D6 yo G --. D8 ri Z --.. CC hu
Q --.- C8 ne
O --- DA re (3) ---. BF sho
(4) ---- BA ko
5 ..... 5 6 -.... 6
4 ....- 4 = -...- D2 me
(5) ...-. / -..-. D3 mo
3 ...-- 3 -..-- D5 yu
(6) ..-.. C4 to (c) -.-.. B7 ki
Inter ..-.- D0 mi Start -.-.- BB sa
..--. DF [B] ( -.--. D9 ru
2 ..--- 2 -.--- B4 e
Wait .-... B5 o 7 --... 7
(9) .-..- yi (e) --..- CB hi
+ .-.-. DD n --.-. BC shi
.-.-- C3 te (f) --.-- B1 a
.--.. ye 8 ---.. 8
(a) .--.- B0 - ---.- BD su
(b) .---. BE se 9 ----. 9
1 .---- 1 0 ----- 0
These notes represent two special marks in Japanese:
[A] double stroke following kana (nigori),
[B] small circle following kana (han-nigori).
These notes represent accented letters in European languages or Turkish:
(1) u umlaut (2) a umlaut, cedilla (3) o umlaut or other accent (4) ch, s cedilla (5) s hat (6) e primary accent (usually acute, grave in Italian) (9) e accent grave (a) a accent (b) j hat (c) c cedilla or accent (e) z accent grave (f) n tilde
To remove ambiguities, the Japanese syllables are preceded by the hex code, in the version of 8-bit ASCII that includes kana, of the kana symbol represented. The symbols whose phonetic values I give as yi and ye have the appearance, respectively:
* ********
******* *
* * *
* * * *
* * *
******* *
* *******
Here is a graphic, giving all the kana used in Japanese Morse:
In addition to placing the letters of the English alphabet there for comparison, the opportunity has been taken to include the alphabets for the Greek, Hebrew, and Russian versions of Morse code.
Since this system requires that the ciphertext letters must be able to represent all combinations of from one to four dots or dashes, four extra symbols, used in Morse for accented letters in some languages other than English, need to be included in the cipher alphabet.
While the original system, having only the group length as a key, may not have been all that secure, the basic concept is clever and original. The character lengths could as easily have been transposed by means of a double columnar transposition, and the dots and dashes could be translated to 0s and 1s, and enciphered by any applicable method, even DES.
While I consider Ohaver's "mutilation" cipher very interesting, for the principle which it illustrates, the term Fractionated Morse is normally used for a less elegant, but more secure, system, in which possible combinations of three symbols from the set of dot, dash, and x, the latter standing for the space between letters, are represented by letters. Note that combinations with two consecutive "x"s are not required, so the ciphertext uses a 22-letter alphabet.
The letters will vary in frequency, and since two adjacent letters that would produce two consecutive "x"s do not occur, redundancy still remains in subtle forms as well.
Also, fractionation can be done in a mixed fashion.
Because there are convenient ways to convert both letters and bits to a mix of symbols from a 3-element set and from a 5-element set, as well as an efficient way to convert from bits to letters, intriguing possibilities suggest themselves. An elaborate fractionation scheme combining the threads mentioned here together is described later.
One interesting way to produce a mixed fractionation scheme comes from the fact that the square of any triangular number is the same as the sum of the cubes of the consecutive numbers which, when added, produced that triangular number!
Making use of that fact, and since 10 is a triangular number, one can construct a table like this:
0 1 2 3 4 5 6 7 8 9 0 AAA AAB AAC * -+- -++ aca acb acc acd 1 ABA ABB ABC --- +-- +-+ ada adb adc add 2 ACA ACB ACC --+ ++- +++ baa bab bac bad 3 BAA BAB BAC CAA CAB CAC bba bbb bbc bbd 4 BBA BBB BBC CBA CBB CBC bca bcb bcc bcd 5 BCA BCB BCC CCA CCB CCC bda bdb bdc bdd 6 aaa aba daa dab dac dad caa cab cac cad 7 aab abb dba dbb dbc dbd cba cbb cbc cbd 8 aac abc dca dcb dcc dcd cca ccb ccc ccd 9 aad abd dda ddb ddc ddd cda cdb cdc cdd
As 1 cubed is just 1, and 2 cubed is 8, these symbols make up only a very small part of the square table above, and thus this part of the table is seldom used. One way to deal with that is to change the table, so that those 9 spaces are instead filled by two symbols from the ABC set of symbols.
0 1 2 3 4 5 6 7 8 9 0 AAA AAB AAC AA AB AC aca acb acc acd 1 ABA ABB ABC BA BB BC ada adb adc add 2 ACA ACB ACC CA CB CC baa bab bac bad 3 BAA BAB BAC CAA CAB CAC bba bbb bbc bbd 4 BBA BBB BBC CBA CBB CBC bca bcb bcc bcd 5 BCA BCB BCC CCA CCB CCC bda bdb bdc bdd 6 aaa aba daa dab dac dad caa cab cac cad 7 aab abb dba dbb dbc dbd cba cbb cbc cbd 8 aac abc dca dcb dcc dcd cca ccb ccc ccd 9 aad abd dda ddb ddc ddd cda cdb cdc cdd
Using the straddling checkerboard that we saw above,
9 8 2 7 0 1 6 4 3 5
-------------------
A T O N E S I R
2 B C D F G H J K L M
6 P Q U V W X Y Z . /
we can encipher a sample message in this scheme, just seriating across the whole message for simplicity (in practice, one would want to do other things):
TH EREISAP AC K AG EW AITING F ORY OU ATTH ESTATION message 821151349699282492016093830202775667629882114898370 straddling checkerboard d A B C c c b C d A a d d A A c b c d c d A b c b fractionation c B C A d d a B d A a d c A A b d a a d c B c d b encoding a B B B a d c a B a b b C C b a b a c a B c c b
For this example, I won't worry about enciphering the last digit of the message. Padding, or another encipherment step might take care of that.
Now, I seriate the symbols from the ABC and the abcd sets independently, retaining the type of each pair of digits, and thus the symbols are rearranged as follows, leading to enciphered digits:
d A B B c a c B d C a c d B C d b a c d d A a a a seriation a B C B d d b A d A c b c B A b b b d a c A a b d a C A A a c d c C d c a A B b c c c d c B b b b 621250409618791394350978824034733881986584017071170 reconversion
One could also leave all the "d" symbols in their place, and seriate only the "abc" and "ABC" symbols as though case did not matter - but then convert either to capital or small letters so that the type of each two digit group is kept the same. (Some care, of course, must be taken when developing a variation so that decipherment remains possible.) That would produce the following result:
d C A A b b b C d B c d d A B c a c d b d A c c b seriation a A A B d d a A d A b d c B A a d c a d a C c d b b B A C a d b a A c c c A A b b b c c c C b b b 633400125659272392307894841030671787645864228797370 reconversion
and this method has its strengths, but also its weaknesses (mainly because the "d"s remain fixed).
Another technique I once described involved first using the straddling checkerboard to encipher a message as digits, and then to use Playfair to encipher it. But instead of using the Playfair technique over a 5 by 5 square of letters, one uses a 10 by 10 square containing digit pairs, like the following:
68 71 07 49 76 42 54 77 21 82 02 09 98 65 70 55 17 01 50 91 33 35 30 08 62 22 97 44 06 57 64 18 78 58 96 34 11 56 52 38 95 26 86 20 27 37 93 05 14 85 63 29 39 61 87 10 88 32 00 80 31 81 16 83 24 99 67 72 13 53 89 94 47 40 25 73 04 59 84 19 03 75 28 60 12 41 43 48 66 74 79 46 36 45 51 69 23 15 92 70
Thus, the four digits 2076 would encipher to 2749 with this square.
Next
Chapter Start
Skip to Next Section
Table of Contents
Main page
Home page