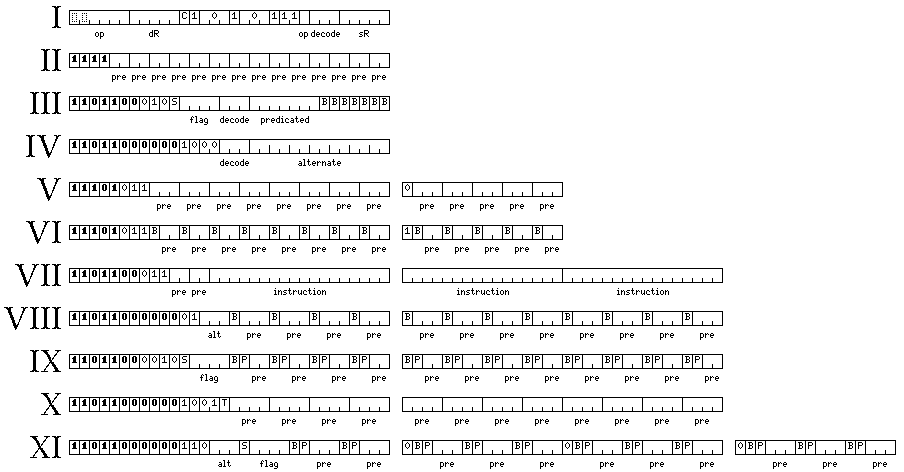
Welcome to the home page of the Concertina II computer architecture.
The original Concertina computer architecture was originally intended as a simple example of a conventional old-style CISC architecture, to help explain how computers work. It was expanded over time to include many features from a wide selection of historical computer architectures, to explain those as well.
Concertina II was intended as an ISA that could conceivably be of practical use in an actual implementation. However, I cannot make ambitious claims for it, as my experience in this area is quite limited. This architecture went through quite a number of drafts before I felt that I had struck an acceptable balance between the various factors that had to be compromised to provide the architecture with the capabilities I sought.
What is the Concertina II ISA, and what choices were made in its design?
The basic Concertina II instruction set is patterned after today's most popular type of ISA (instruction set architecture) design, RISC (reduced instruction set computing).
The basic instruction set consists of 32-bit instructions, but also adds the ability to use a pair of 16-bit instructions at any point in the sequence of instructions in place of a 32-bit instruction.
This allows increasing code density by using smaller instructions for many operations, without losing the simplicity of fetching and decoding instructiions gained by having all instructions of the same length. It was considered important enough that the length of the base register field was shortened from three bits to two bits for 16-bit displacements in the standard memory-reference instructions, as the least painful compromise that would provide the opcode space reguired.
As in many RISC designs, there are two main register files, one for integer values (with registers that are 64 bits wide) and one for floating-point values (with registers that are 128 bits wide), each of which contains 32 registers.
Also, the memory-reference instructions are of the load-store variety, following standard RISC practice.
The following extensions to the RISC model are included:
Typically, RISC architectures normally only allow two registers to be indicated in a memory-reference instruction. One is the destination register of the instruction, and the other one is the one the contents of which are added to the displacement to form the effective address, Since a base register is needed for any memory access when the displacement is not large enough to indicate any location in the available memory, this means that the advantage of having an index register isn't available, and array access require additional explicit arithmetic instructions to compute addresses.
Thus, since the use of arrays is a very common operation, full base-index addressing was considered a very important feature to add.
In order to make it possible to provide this feature, the integer registers were split up into groups of eight so that the index register and base register fields could be only three bits long instead of five bits long, thus allowing both to fit in an instruction.
Normally, if one allocates a block of memory containing 65,536 bytes, using a base register to point to that block, it is not useful to have addressing modes that can only access the first 4,096 bytes of that block. Therefore, separate groups of registers are used as the possible base registers for different sizes of displacement values.
Only one register serves as the implicit base register for 15-bit displacements; this is done to allow one larger block of memory to be used in conjunction with those accessed with 12-bit displacements. This permits more compact memory-reference instructions, and is inspired by the System/360 Model 20 computer.
The above summarizes how the basic instruction set of this computer was designed to take the basic RISC design, and offer important extensions to it, while still having instructions that fit in 32 bits.
But a number of other extensions are also offered. These require going beyond the RISC-like model of the basic instruction set, and instead recognizing that this architecture also has VLIW (Very Long Instruction Word) characteristics.
Instructions are to be fetched in blocks of 256 bits, each of which contains eight 32-bit instruction slots.
A small portion of the opcode space for instructions is dedicated to codes which represent headers instead of instructions. The first instruction slot in a block may contain a header, and if it does, the following slot may also contain a header, and so on.
Headers, if any, are processed before the instructions in a block are decoded.
After the headers are processed, or after it is determined that the block does not begin with a header, the computer has the information required to decode all the instructions in the block in parallel.
One of the most important features that having headers provides, which is still considered part of the basic instruction set of the Concertina II architecture, is pseudo-immediate values.
Some register-to-register instructions may have a source register specification replaced by a four-bit halfword (that is, denominated in units of 16 bits) pointer to an address within the current instruction block, which points to an operand for that instruction.
This capability is supported by headers which contain a three bit decode field, which indicates that some of the eight 32-bit instruction slots in the current block are to be ignored during instruction decoding, and skipped over in execution, so that pseudo-immediate values can be placed in them.
What are pseudo-immediate values, and why are they included in this ISA? Essentially, they are inspired by the Heads and Tails design of Heidi Pan. Immediate mode instructions have the advantage that a constant value can be used in a calculation without requiring an additional fetch of data, with all the delays and overhead of memory accesses in modern architectures, where DRAM is slow compared to processor logic.
This is because the immediate value is part of the instruction itself, and thus has already been fetched as part of the instruction stream.
But since data items come in several widths, comprehensive support of immediate values means that instructions must come in many different lengths, complicating their decoding.
With pseudo-immediate values, the length of the instruction doesn't have to be changed. A pointer to the value only takes up the same space as a register specification.
But if the value is fetched from a location indicated by a pointer, it isn't an immediate value any more. Hence the term "pseudo-immediate" - given that instructions are fetched from memory in 256-bit blocks, and the data to which the pointer refers is within the same block as the instruction itself, even though the values are not actually immediate values, they still offer the same basic advantage as immediate values.
In addition to pseudo-immediate values, headers allow two basic sets of features to be added to the ISA that go beyond the RISC model.
Thus, while the architecture initially has the appearance of a conventional RISC architecture, it is intended to combine the basic features and advantages of RISC, CISC, and VLIW architectures.
Note, however, that by VLIW, I mean modern VLIW architectures, such as the Itanium or, even more particularly, the Texas Instruments TMS320C6000 chip, and not the type of classic VLIW architecture the term was originally concieved of as referring to, such as that of the Control Data Cyber 200 computer.
There are 32 integer general registers and 32 floating-point registers, and those instructions that perform arithmetic or logical operations include a bit for enabling changes to the condition codes as a result of those instructions. These are characteristics found in RISC architectures.
Having register banks of 32 registers allows different calculations to be intertwined in the code, and being able to control if instructions affect the condition codes allows more intervening instructions between an instruction that sets the condition codes and a branch instruction that makes use of those results. Both of these things allowed code to be designed to offer some of the same benefits as are obtained from out-of-order execution, without the hardware overhead. However, at the microprocessor clock rates in use today, these measures normally are not enough to be effective: however, if code written this way is combined with simultaneous multi-threading (SMT), then there is still the potential for competing with out-of-order execution.
Instructions are organized into 256-bit blocks which contain eight 32-bit instruction slots.
These blocks are always aligned on the boundaries of aligned 32-byte areas in memory, so an instruction slot that may contain the initial header of a block must have an address the last five bits of which are zero.
When a block header makes provision for instructions longer than 32 bits, it is possible that these instructions may cross block boundaries, depending on the rules applicable to the particular block header format in use.
The instruction set is organized so that the computer is able to fetch a 256-bit block of instructions, and, after processing any block header within the block, to determine what, if any, special processing is required, immediately begin decoding each 32-bit instruction slot independently of the others in the block.
There are several different types of block header, which are shown in the diagram below.
Eleven types of header are illustrated in this diagram.
The first type of header also functions as a two-operand register-to-register operate instruction, as well as a header which, with its decode field, specifies the number of 32-bit instruction slots at the end of the block which are not decoded as instructions, but are instead reserved for other purposes, such as the data values for pseudo-immediates.
An immediate value in an instruction allows it to perform an arithmetic operation involving a constant without having to perform a fetch of data from memory in addition to the fetching from memory already performed as part of reading in the instruction stream.
An important design goal of the Concertina II architecture has been to drastically simplify the decoding of instructions; once a 256-bit instruction block has been checked for a header, and that header, if present, has been processed, all the instructions in the block can be decoded in parallel independently. The varying lengths of different data types mean that including a wide selection of instructions with immediate values would conflict with this.
A pseudo-immediate is addressed by a pointer in the instruction, which seems to be the same thing as a memory-to-register instruction making use of a constant value stored somewhere else. However, the pointer is a short-range one, which only points to a location within the same 256-bit instruction block as the current instruction is contained in.
Therefore, although it involdes a pointer reference, and thus is not "really" an immediate, hence the name "pseudo-immediate", it provides the same advnatage of the constant argument having been fetched as part of the instruction stream!
This first type of header reserves space for these constants which therefore won't be decoded erroneously as instructions, and because the header is also an instruction, it lets these three bits of information be provided without the overhead of using a full 32-bit instruction slot for a header and nothing else.
The second type of header creates a block which can include instructions of lengths other than 32 bits.
If a block begins with an instruction slot that begins with the bits 1111, that instruction
slot contains this type of header.
Here, each of the fields marked pre corresponds to one of the remaining 16-bit halves of the seven remaining 32-bit instruction slots in the block.
If a pre field contains 0 as its first bit, then the corresponding
16 bits in the block are the last sixteen bits of a seventeen bit short-format instruction;
the first bit of the instruction is the second bit in the pre field following
the leading zero.
If a pre field contains 10, then the corresponding 16 bits in the
block are normally the first 16 bits of a 32-bit instruction in the same standard format as
is used when there is no block header, or with the other type of header described above.
In addition, however, if those 16 bits begin with 1111, as this combination is no
longer required to indicate a header, it indicates that an instruction 48, 64, or more bits in
length is present, the length being indicated within the instruction as follows:
11110 48 bits 111110 64 bits 11111100 80 bits 11111101 96 bits 11111110 128 bits
If a pre field contains 11, this indicates the corresponding 16
bits in the block are not to be decoded unless decoding is initiated by a preceding 16-bit field
in the block. That is, they will be decoded if they are part of a 32-bit (or longer) instruction
that began before it. Thus, in addition to containing the later parts of instructions, the 16-bit
extents indicated by these pre bits may also be used for pseudo-immediate values.
Because pre bit values of 00, 01, and 10,
in addition to initiating the
decoding of instructions, also control execution, as only the instructions that are
decoded can be executed, it is not necessary for pseudo-immediate values to be placed at the
end of the block, they can be placed in any space that is indicated as not being decoded by
a pre value of 11. As we shall see below, taking advantage of
this opportunity is necessary in one case.
Instructions in blocks of this format may be the targets of jump and jump to subroutine instructions; their addresses are always those of the first 16-bit part of the instruction, with the first bit in the header for 17-bit instructions not being considered.
Because the positions where instructions start are explicitly indicated, instructions may cross block boundaries in this type of block.
Because this type of block header does not contain a decode field, any instruction that will continue into the next block must be located at the physical end of the block. Therefore, if pseudo-immediates are also used in such a block, then they must be placed between instructions instead.
The third type of header provides supplementary information which allows the computer to provide VLIW functionality.
A decode field to reserve space for pseudo-immediates is also included.
The primary feature of this type of header is to provide for VLIW features which can be used to accelerate the speed of instruction execution, particularly on lightweight implementations of the architecture which lack out-of-order execution.
The decode field is used to indicate the number of 32-bit instruction
slots that are reserved for data other than instructions, such as pseudo-immediate values,
for which no attempt is to be made to decode them as instructions. A value of 000
in the decode field indicates that all the remaining instruction slots are
to be decoded as instructions; a value of 001 indicates the last instruction
slot is to be reserved, and not decoded, and so on.
There are seven bits marked B, for break; they correspond to the last six of the seven remaining 32-bit instruction slots in the block, and if a bit marked B is set, this indicates that the instruction in its corresponding instruction slot may not be executed in parallel with the instructions that precede it.
|
Important note: it is intended that this ISA may be implemented in a number of ways. Specifically, in relation to the VLIW feature of the break bit, these three classes of implementations are possible:
In consequence, any programs which would produce a different result on the first two types of implementation listed above are to be considered to be invalid programs which have been written incorrectly. Thus, the architecture specification requires implementations to execute code which does not contain any explicit indications of parallel execution with sequential consistency. When code does contain such indications, implementations may follow those indications, or they may execute the code sequentially, even if different results are produced in the two cases; it is the programmer's responsibility, if consistent model-independent execution of programs is desired, only to indicate parallelism where it does not lead to results different from those of completely sequential code. There is, however, one oversimplification in the above, as a fourth type of implentation may also be desirable. Due to the existence of processor vulnerabilities such as Spectre, it may be useful for an out-of-order processor to have the ability to execute untrusted code in an in-order fashion. In that case, such a processor, although out-of-order, should also offer support for the break bit so that it can run in-order code designed to run as efficiently as possible, so as to reduce the loss of speed for in-order code. So, for example, untrusted JavaScript code on a web site could be compiled by the browser to code making full use of the break bit and other VLIW features, which would then be executed with branch speculation and other out-of-order features disabled. |
In this header format, there is also a four-bit flag field. This indicates which of the sixteen flag bits may be used for predicating instructions in this block. A seven-bit predicated field indicates which instruction slots contain an instruction the execution of which is conditional, based on that flag bit. There is also a bit marked S, for sense; if that bit is zero, a predicated instruction will execute if and only if the selected flag bit is set (equal to 1); if it is one, the predicated instruction will instead execute if and only if the selected flag bit is cleared (equal to 0).
The fourth type of header allows one to specify, for a block made up of 32-bit instructions,
whether those instructions are of the regular type (indicated by 00 in one
of the two-bit segments of the alternate field), or whether they are of one
of three alternate types of 32-bit instructions. This allows for extending the instruction
set.
This header, of course, does not provide access to the instructions longer than 32 bits
for which space is reserved within the main instruction set by reserving codes starting with
1111 for longer instructions; a header of the third type is required for this.
The alternate instruction sets may also have space
within them reserved for longer instructions, which would also not be accessible with this form
of header, but which would be accessible with a header of the sixth type.
The fifth type of header allows the alternate types of 32-bit instructions, as indicated with the fourth type of header for code consisting of 32-bit instructions only, to also be used within code which also includes 17-bit instructions and instructions longer than 32 bits.
Here, the prefix fields are each three bits long, rather than two bits long, as they were in the third type of header, and have the interpretations:
000 a 17-bit instruction starting with 0 001 a 17-bit instruction starting with 1 010 the start of a normal 32-bit instruction, or an instruction longer than 32 bits 011 not the start of an instruction 100 not used in this header format 101 alternate 32-bit instruction type 1 110 alternate 32-bit instruction type 2 111 alternate 32-bit instruction type 3
Incidentally, note that just as the normal 32-bit instruction set includes codes starting
with 1111 reserved for instructions longer than 32 bits, the alternate instruction
sets may also have a portion reserved for longer instructions, and they will also be accessible
from this header type.
The sixth type of header provides access only to the 17-bit instructions, and instructions longer than 32 bits, to which access is also provided by the second type of header. While its format is similar to that of the fifth type of header, here the extra prefix bit corresponding to each 16-bit halfword in the remainder of the instruction block is a B bit, allowing the explicit indication of which instructions may execute in parallel in code with variable-length instructions.
The seventh type of header reserves one instruction slot at the beginning of the block, immediately after the header. It is intended to increase the flexibility of the instruction encapsulation feature, which allows variable-length instructions, of the type used in a block with the third type of header, to also be used within ordinary blocks with no header or blocks with a header of the first or second types. As such, it will be discussed in the section below which deals with the encapsulation mechanism.
The eighth type of header combines the functionality of the fifth and sixth types of header, now allowing explicit indication of parallelism to be combined with the ability to select instructions belonging to three alternate types of instructions.
However, it also provides one additional type of function: the alt field indicates one of eight further alternate types of instructions; and this additional alternate type of instructions may be accessed because the prefix fields now have the interpretation:
000 a 17-bit instruction starting with 0 001 a 17-bit instruction starting with 1 010 the start of a normal 32-bit instruction, or an instruction longer than 32 bits 011 not the start of an instruction 100 additional 32-bit instruction type specified in the alt field 101 alternate 32-bit instruction type 1 110 alternate 32-bit instruction type 2 111 alternate 32-bit instruction type 3
The ninth type of header combines the instruction sets provided in the second and sixth types of header with predication, thus providing an alternative to encapsulation.
The tenth type of header provides a four-bit prefix for every 16 bits which remain in the block. As the focus of the additional instruction types provided is to increase code compactness, it was considered reasonable not to porovide additional header types which allow four bit headers to be combined with break bits and possibly also instruction predication, as was done for two- and three-bit prefixes.
The significance of a four-bit header is as follows:
0000 a 17-bit instruction starting with 0 0001 a 17-bit instruction starting with 1 0010 the start of a normal 32-bit instruction, or an instruction longer than 32 bits 0011 not the start of an instruction 0100 not used in this header format 0101 alternate 32-bit instruction type 1 0110 alternate 32-bit instruction type 2 0111 alternate 32-bit instruction type 3 1abc a 19-bit instruction starting with abc
The 19-bit instructions are memory-reference instructions, with a three-bit opcode, one bit to specify indexing, a three-bit base register specifier, and a 12-bit address. The T bit determines the types on which these instructions operate if they are operating on fixed-point data; if 0, the types are 16-bit and 32-bit; if 1, the types are 32-bit and 64-bit.
The eleventh type of header combines the instruction sets provided in the fifth and eighth types of header with predication, thus removing the need to attempt to create an encapsulation format in this case.
The bit combination 1111 is not used to begin ordinary instructions, as
it is used to indicate a header of the third type.
As we have seen, it is also used in later instruction slots after a header of the third type to indicate an instruction which is longer than 32 bits.
It also serves a purpose in instruction slots other than the first one in other types of block as well.
In that case, it begins the contents of both 32-bit instruction slots which contain three eighteen-bit instruction fields similar to those which follow a header of the third type; this allows short sequences of variable-length instructions to be included in code without reserving a whole block with a header of the third type for them.
The format of this pair of instruction slots is shown below:

As well as the format of this instruction bundle being shown in the top line of the diagram, it also shows how the elements of the bundle are combined to form three eighteen-bit instruction packets consisting of the two-bit prefix follwed by the 16 bits of instruction data which they modify.
Instructions longer than 16 bits may continue from one instruction bundle into another instruction bundle that is immediately following. This is true both if the two headers are contiguous within the same instruction block, or if the first bundle is at the end of the executable portion of one block (space reserved for pseudo-immediates may be present in between) and the second bundle begins the executable code in the next instruction block by being located immediately after a header of the second type.
Because 1111 is also used to indicate a header of the third type,
a block without a header cannot begin with an instruction bundle of this form.
This is addressed by the header of the seventh type, which performs an equivalent
function at the beginning of a block.
An instruction bundle may begin at the end of one block if its second half can immediately follow its first half; this is true when the second block begins with a header of the second type.
As well, to increase the flexibility of the encapsulation mechanism, the following circumstance is also allowed: the first half of an instruction bundle may end one block where the following block begins with a header of the fourth type; this header must then be immediately followed by the second half of the instruction bundle.
For purposes of assigning prefix data to the remainder of the instruction, the instruction bundle and the header of the fourth kind may be regarded as nested.
As with instructions inside a block with a header of the third kind, instructions encapsulated within these instruction bundles are regarded as addressable by the location of the 16-bit halfword containing the last few bits of their first eighteen bits, whether that is 16 bits, or 11 bits. This position also indicates the order of execution, so when an instruction bundle is split across a header of the fourth kind, execution order is:
And what about the case where it is desired to include, within an encapsulated sequence of variable-length code, alternate 32-bit instructions of the kinds that can be specified by headers of the fifth and sixth kinds?
In this case, encapsulation is indeed also possible, and a sequence of encapsulated code has the format shown below:

Note that the encapsulated bundle now occupies three instruction slots. The last two have the same form as the second one in a standard encapsulated bundle. The first one is again indicated by a sequence of bits which is also used to indicate a header, in particular the header of the fifth kind. Here, no provision is made for allowing this type of bundle to cross block boundaries, and so it can only begin in the second through sixth instruction slots of a block (instruction slots 1 through 5, as the first one would be addressed as instruction slot zero).
Incidentally, it is important to note that in addition to it being possible for an instruction beginning within a bundle from this form which abuts the end of an instruction block being able to continue into the subsequent instruction block, if it has a header of the corresponding sixth kind, if it happens that an instruction which may be expressed within a header of the third kind begins at the end of this type of instruction bundle, it, too, may continue into a subsequent instruction block of the third kind. This principle applies generally, including the next type of instruction bundle to be discussed, and headers of the eighth kind as well as the third and sixth; instructions which fit into both of two different kinds of bundle, blocks with two different kinds of header for variable-length code, or an instruction bundle and a block with a header for variable-length code which do not fully correspond, may cross from one to the other.
The basic complement of registers included with this architecture is as follows:
There are 32 integer registers, each of which is 64 bits in length, numbered from 0 to 31.
Registers 1 through 7 may be used as index registers.
Registers 25 through 31 may be used as base registers, each of which points to an area of 65,536 bytes in length.
Register 24 serves as a base register which points to an area 32,768 bytes in length.
Registers 9 through 15 may be used as base registers, each of which points to an area of 4,096 bytes in length.
At least part of the area of 4,096 bytes in length pointed to by register 8 will normally be used to contain up to 512 pointers, each 64 bits in length, for use in either Array Mode addressing or Address Table addressing.
Registers 17 through 23 may be used as base registers, each of which points to an area of 1,048,576 bytes in length. This addressing format is used for 48-bit extended memory-reference instructions.
Register 16 serves as a pointer to a table of pseudo-operations, if this feature is used.
There are 32 floating-point registers, each of which is 128 bits in length, numbered from 0 to 31.
Floating point numbers in IEEE 754 format have exponent fields of different length, depending on the size of the number. For faster computation, floating-point numbers are stored in floating-point registers in an internal form which corresponds to the format in which extended precision floating-point numbers are stored in memory: with a 15-bit exponent field, and without a hidden first bit in the significand.
As 128-bit extended floating-point numbers are already in this format in memory, all floating-point numbers will fit in a 128-bit register, although shorter floating-point numbers are expanded.
However, the 32 floating-point registers may also be used for Decimal Floating-Point (DFP) numbers. These numbers will also be expanded into an internal form for faster computation, but that internal form may take more than 128 bits.
This is dealt with as follows: Only 24 DFP numbers that are 128 bits in length may be stored in the 32 floating-point registers. When such a DFP number is stored in an even-numbered register, it is stored in that register, and the first 32 bits of the following register. When it is stored in a register the number of which is of the form 4n + 1 for integer n, the first 84 bits of the internal form of that number are stored in the last 84 bits of that register, and the remainder of the internal form of that number is stored in the last 84 bits of the second register after that register.
In this way, the same principle that storing double-length numbers in two adjacent registers is respected: numbers too long to be stored in a given register are stored in that register, and in another register of the same register file that is nearby. But the method is extended to allow more efficient use of the available space.
The same technique is used for the 128-bit floating-point format which has recently been added to IEEE 754 which does have a hidden first bit; therefore, in order to support this format, the usual 128-bit floating-point format offered by this architecture, while similar to, and based on, the Temporary Real format of the original 8087 coprocessor, has an exponent field that is one bit longer than that of the Temporary Real format.
There are 16 short vector registers, each of which is 256 bits in length.
Each of these registers may contain:
As well, they may contain sixteen 16-bit short floating-point numbers in one of two formats.
These numbers all remain in these registers in the same format as that in which they appear in memory.
Also, the entire set of 16 short vector registers can contain a table of bits used for bit-matrix-multiply operations on 64 bit binary words.
In addition to the basic set of registers, two other larger sets of registers are also included in the architecture:
A set of 128 64-bit integer registers, and a set of 128 128-bit floating point registers.
A set of 8 vector registers, each of which contains 64 storage locations for floating-point numbers, each one 80 bits wide. This allows the computer to process vectors of 72-bit floating-point numbers in addition to vectors of 64-bit floating-point numbers, if the optional variable memory width feature is included.
As for how data values are stored in memory:
Signed integer values are stored in binary two's complement format.
Floating-point numbers are stored in IEEE 754 format, but in addition there are instructions for processing data in the format originally used by IBM's System/360 computers, including the Extended Precision format introduced on the Model 85.
The architecture is big-endian: the most significant bits of a value are stored in the byte at the lowest numbered address.
As well, there are 16 flag bits which are used for instruction predication, and of course there is a 64-bit program counter. The program status quadword includes eight sets of condition codes, and the program counter and flag bits are also part of the program status quadword.